I have a secret to reveal: I am not the author of my recent LessWrong posts. I know almost nothing about any of the topics I have recently written about.
Instead, for the last two months, I have been using Manifold Markets to write all my LessWrong posts. Here's my process.
To begin a post, I simply create 256 conditional prediction markets about whether my post will be curated, conditional on which ASCII character comes first in the post (though I'm considering switching to Unicode). Then, I go with whatever character yields the highest conditional probability of curation, and create another 256 conditional prediction markets for the next character in the post, plus a market for whether my post will be curated if the text terminates at that character. I repeat this algorithm until my post is complete.
Here's an example screenshot for a post that is currently in my drafts:
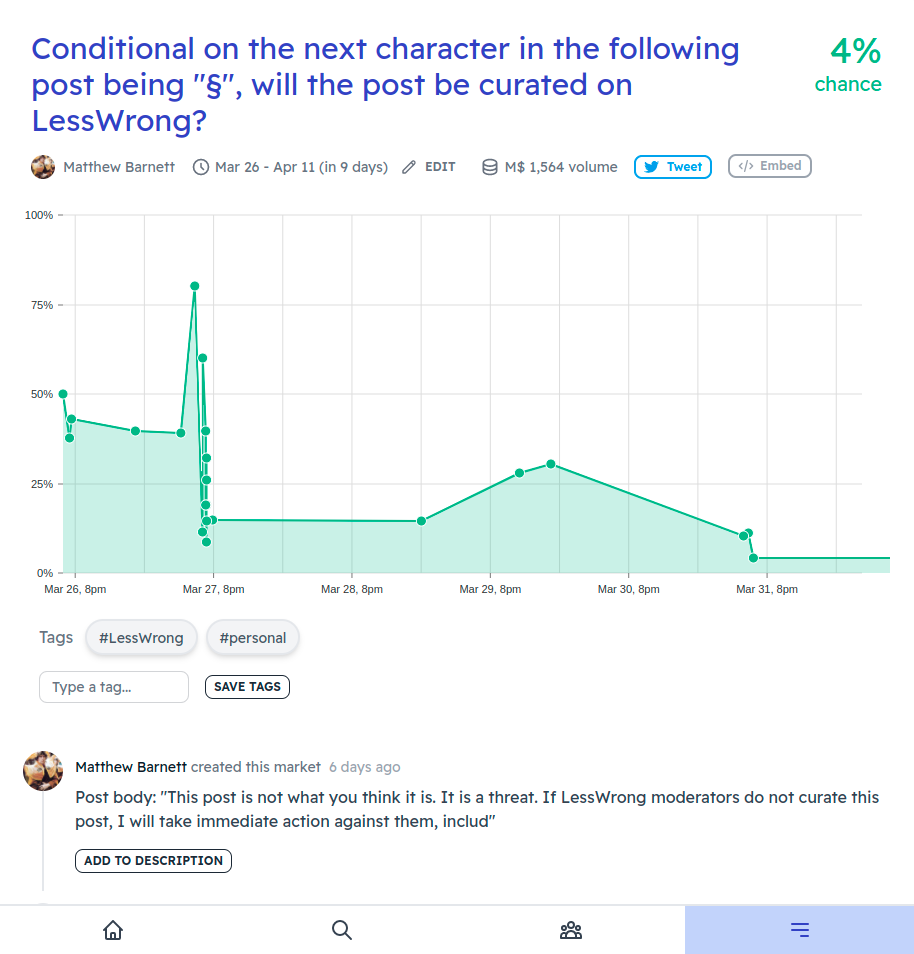
Looks interesting!
Even this post was generated using this method.
One concern I have with this method is that it's greedy optimization. The next character with the highest probability-of-curation might still overly constrain future characters and end up missing global maxima.
I'm not sure the best algorithm to resolve this. Here's an idea: Once the draft post is fully written, randomly sample characters to improve: create a new set of 256 markets for whether the post can be improved by changing the Nth character.
The problem with step 2 is you'll probably get stuck in a local maximum. One workaround would be to change a bunch of characters at random to "jump" to a different region of the optimization space, then create a new set of markets to optimize the now-randomized post text.