(adapted from Nora's tweet thread here.)
What are the chances you'd get a fully functional language model by randomly guessing the weights?
We crunched the numbers and here's the answer:

We've developed a method for estimating the probability of sampling a neural network in a behaviorally-defined region from a Gaussian or uniform prior.
You can think of this as a measure of complexity: less probable, means more complex.
It works by exploring random directions in weight space, starting from an "anchor" network.
The distance from the anchor to the edge of the region, along the random direction, gives us an estimate of how big (or how probable) the region is as a whole.
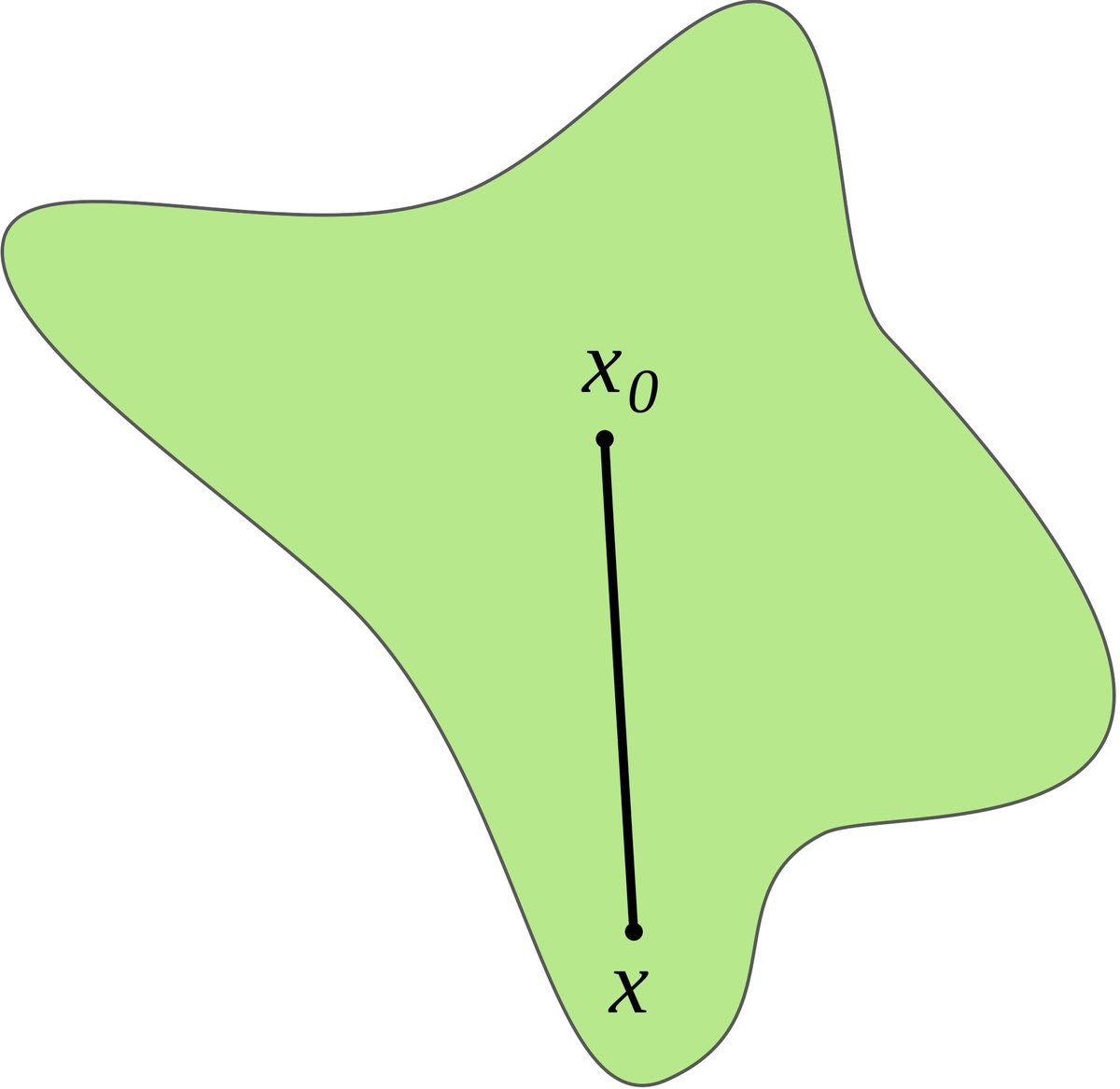
But the total volume can be strongly influenced by a small number of outlier directions, which are hard to sample in high dimension— think of a big, flat pancake.
Importance sampling using gradient info helps address this issue by making us more likely to sample outliers.
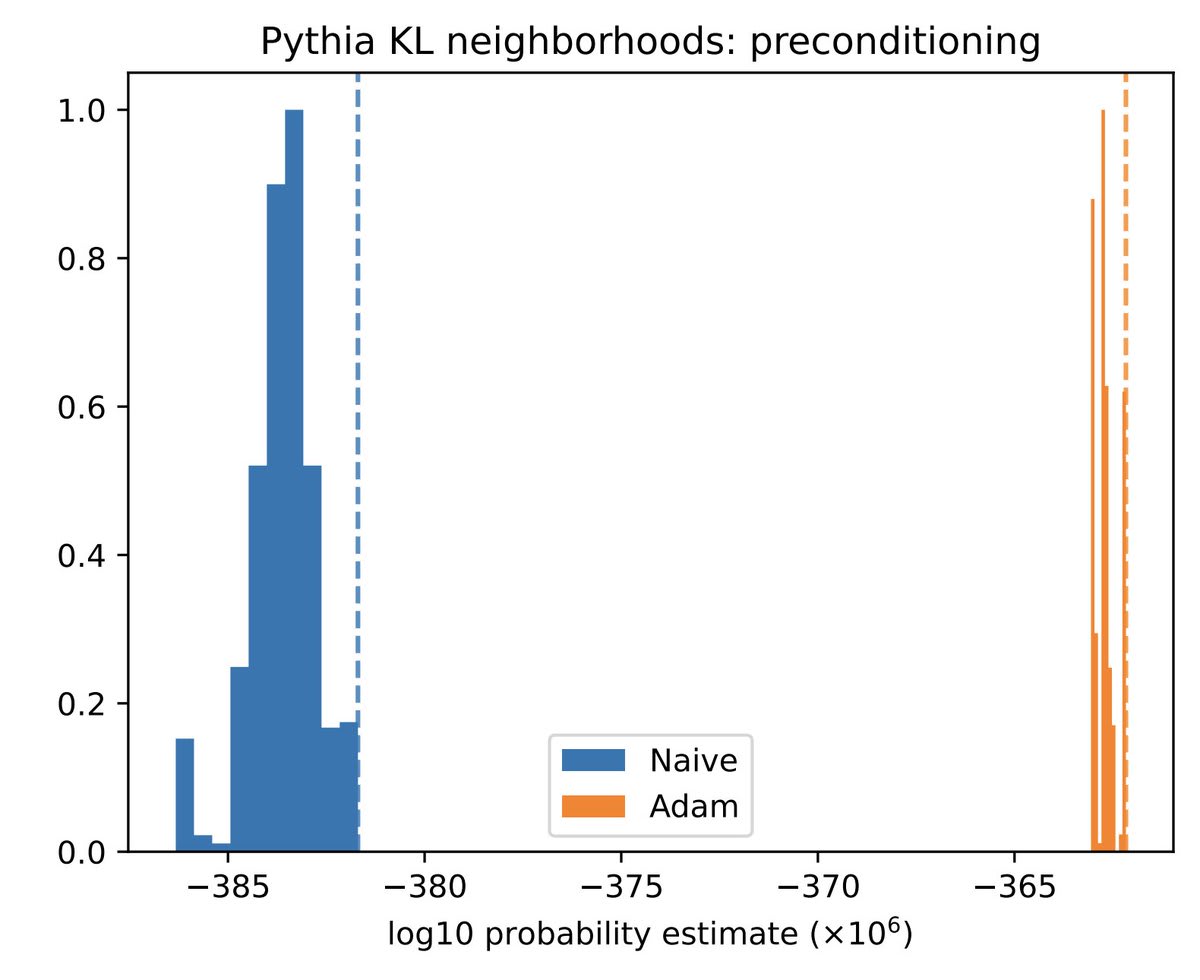
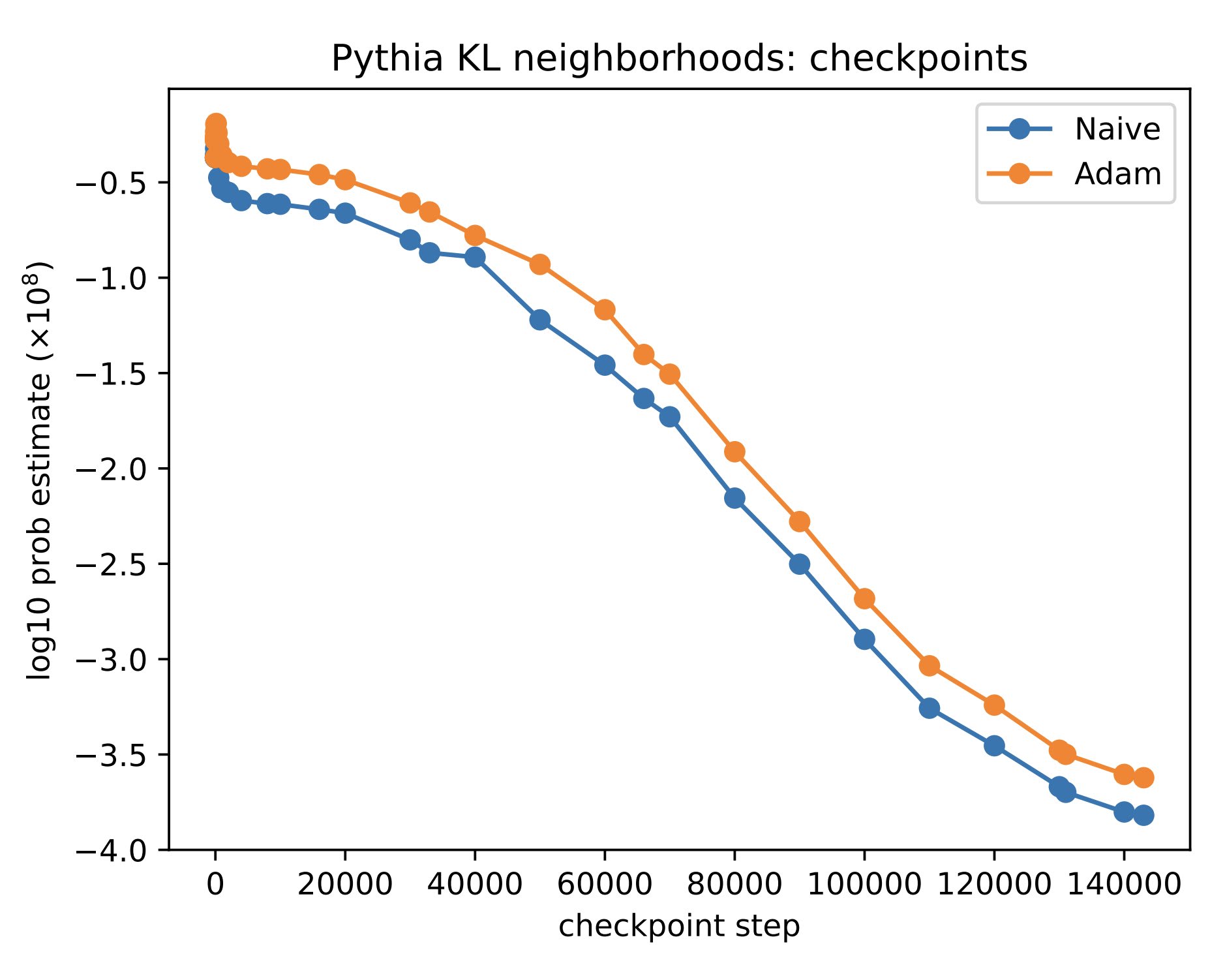
We find that the probability of sampling a network at random— or local volume for short— decreases exponentially as the network is trained.
And networks which memorize their training data without generalizing have lower local volume— higher complexity— than generalizing ones.
We're interested in this line of work for two reasons:
First, it sheds light on how deep learning works. The "volume hypothesis" says DL is similar to randomly sampling a network from weight space that gets low training loss. (This is roughly equivalent to Bayesian inference over weight space.) But this can't be tested if we can't measure volume.
Second, we speculate that complexity measures like this be useful for detecting undesired "extra reasoning" in deep nets. We want networks to be aligned with our values instinctively, without scheming about whether this would be consistent with some ulterior motive https://arxiv.org/abs/2311.08379
Our code is available (and under active development) here.
If you're wondering if this has a connection to Singular Learning Theory: Yup!
In SLT terms, we've developed a method for measuring the constant (with respect to n) term in the free energy, whereas LLC measures the log(n) term. Or if you like the thermodynamic analogy, LLC is the heat capacity and log(local volume) is the Gibbs entropy.
We're now working on better methods for measuring these sorts of quantities, and on interpretability applications of them.
Because it’s actually not very important in the limit. The dimensionality of V is what matters. A 3-dimensional sphere in the loss landscape always takes up more of the prior than a 2-dimensional circle, no matter how large the area of the circle is and how small the volume of the sphere is.
In real life, parameters are finite precision floats, and so this tends to work out to an exponential rather than infinite size advantage. So constant prefactors can matter in principle. But they have to be really really big.