Authors: Senthooran Rajamanoharan*, Arthur Conmy*, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, Neel Nanda
A new paper from the Google DeepMind mech interp team: Improving Dictionary Learning with Gated Sparse Autoencoders!
Gated SAEs are a new Sparse Autoencoder architecture that seems to be a significant Pareto-improvement over normal SAEs, verified on models up to Gemma 7B. They are now our team's preferred way to train sparse autoencoders, and we'd love to see them adopted by the community! (Or to be convinced that it would be a bad idea for them to be adopted by the community!)

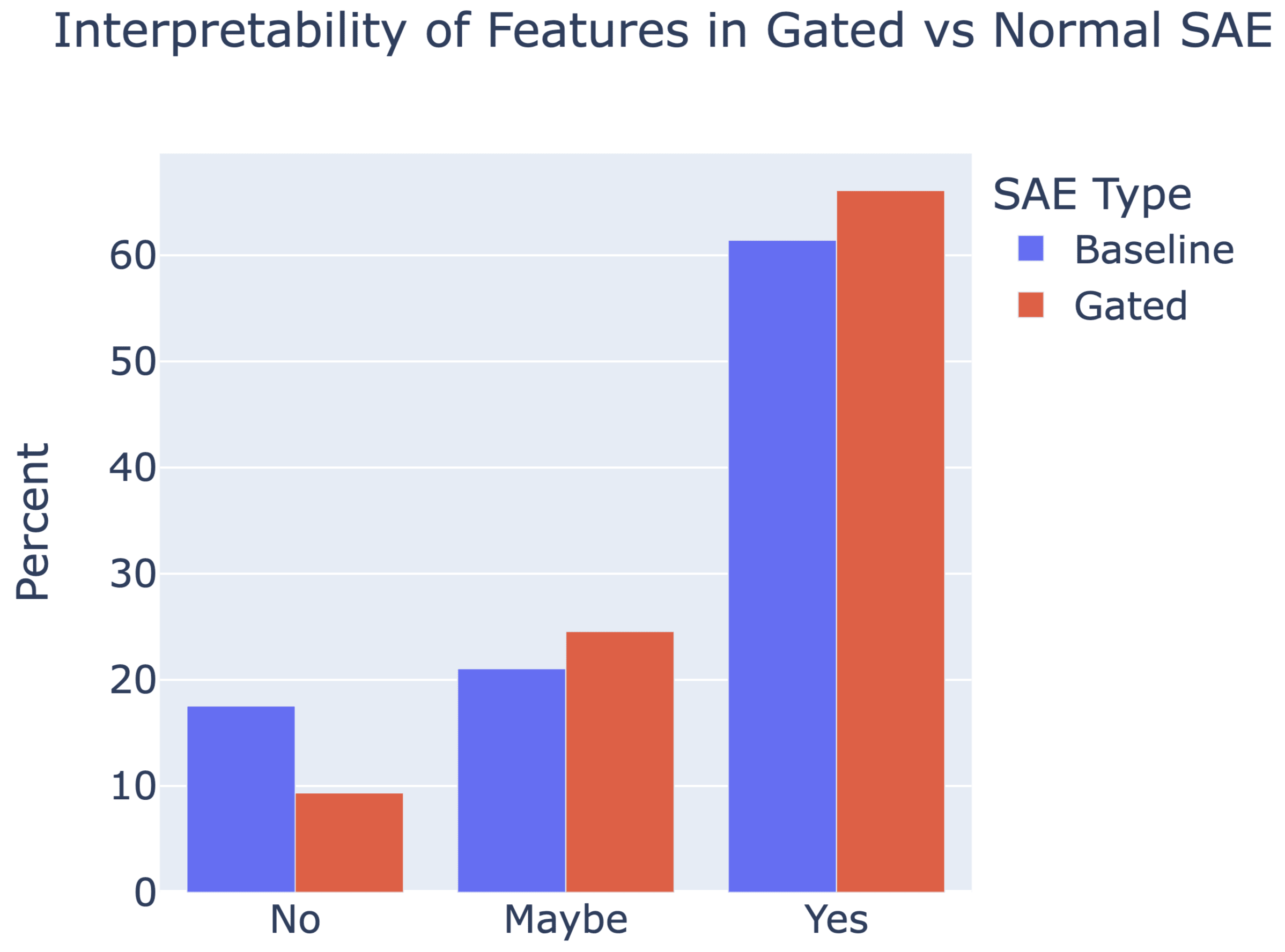
They achieve similar reconstruction with about half as many firing features, and while being either comparably or more interpretable (confidence interval for the increase is 0%-13%).
See Sen's Twitter summary, my Twitter summary, and the paper!
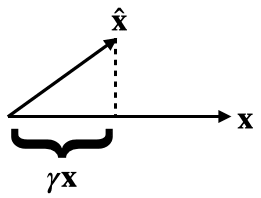

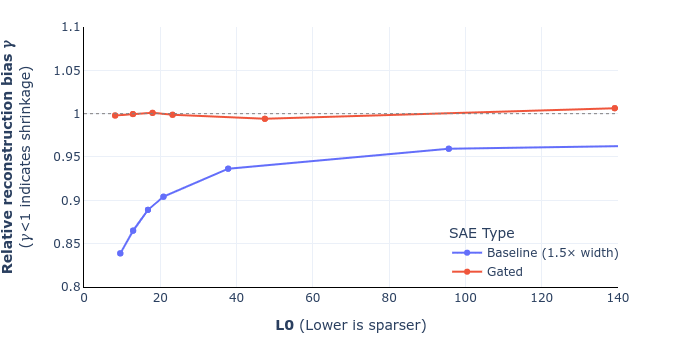
This was actually the key motivation for building this metric in the first place, instead of just looking at the ratio E[||^x||2]E[||x||2]. Looking at the γ that would optimize the reconstruction loss ensures that we're capturing only bias from the L1 regularization, and not capturing the "inherent" need to shrink the vector given these nonzero angles. (In particular, if we computed E[||^x||2]E[||x||2] for Gated SAEs, I expect that would be below 1.)
I think the main thing we got wrong is that we accidentally treated E[||^x−x||2] as though it were E[||^x−γx||2]. To the extent that was the main mistake, I think it explains why our results still look how we expected them to -- usually γ is going to be close to 1 (and should be almost exactly 1 if shrinkage is solved), so in practice the error introduced from this mistake is going to be extremely small.
We're going to take a closer look at this tomorrow, check everything more carefully, and post an update after doing that. I think it's probably worth waiting for that -- I expect we'll provide much more detailed derivations that make everything a lot clearer.