Authors: Senthooran Rajamanoharan*, Arthur Conmy*, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, Neel Nanda
A new paper from the Google DeepMind mech interp team: Improving Dictionary Learning with Gated Sparse Autoencoders!
Gated SAEs are a new Sparse Autoencoder architecture that seems to be a significant Pareto-improvement over normal SAEs, verified on models up to Gemma 7B. They are now our team's preferred way to train sparse autoencoders, and we'd love to see them adopted by the community! (Or to be convinced that it would be a bad idea for them to be adopted by the community!)

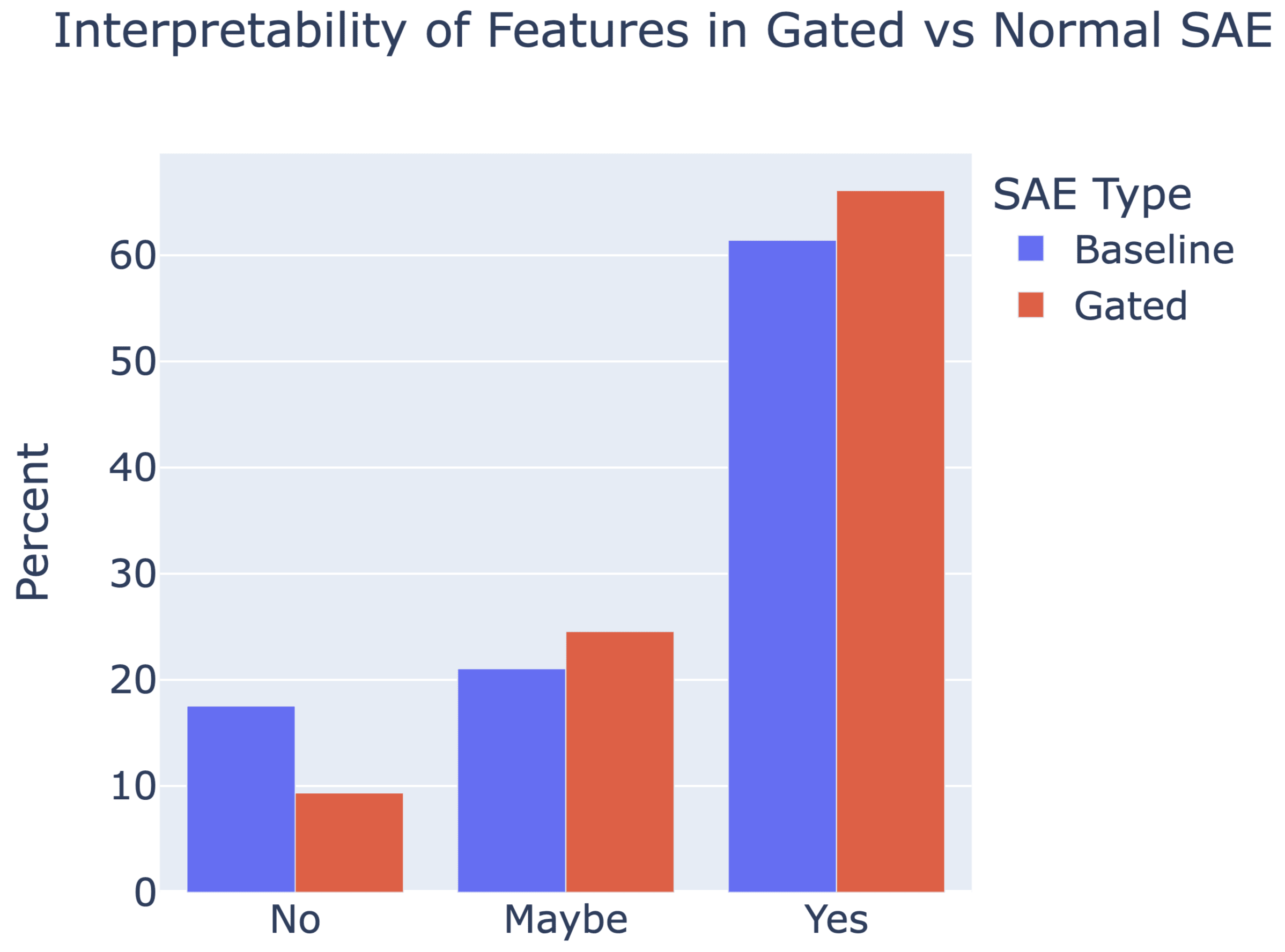
They achieve similar reconstruction with about half as many firing features, and while being either comparably or more interpretable (confidence interval for the increase is 0%-13%).
See Sen's Twitter summary, my Twitter summary, and the paper!
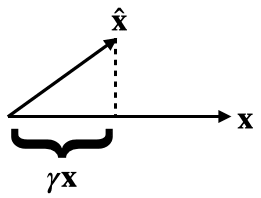

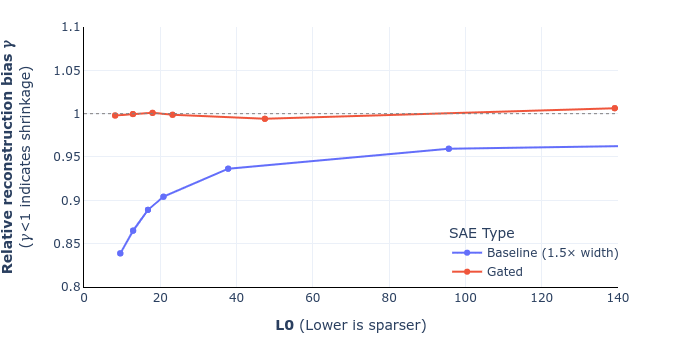
Is there a solution to avoid constraining the norms of the columns of Wdec to be 1? Anthropic report better results when letting it be unconstrained. I've tried not constraining it and allowing it to vary which actually gives a slight speedup in performance. This also allows me to avoid an awkward backward hook. Perhaps most of the shrinking effect gets absorbed by the bgate term?
Good question - we're planning to post an update on this point about combining the new sparsity penalty from Anthropic with Gated SAEs. The TL;DR is that you can replace the L1 term in the Gated SAE loss with the analogous (gated feature magnitudes dotted with decoder magnitudes) sparsity term introduced by Anthropic and thereby do away with the decoder norms constraint and resampling. If you're going to do this, you also need to either unfreeze the decoder in the auxiliary task, or freeze the decoder weights where they appear in the sparsity penalty; both... (read more)