Authors: Senthooran Rajamanoharan*, Arthur Conmy*, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, Neel Nanda
A new paper from the Google DeepMind mech interp team: Improving Dictionary Learning with Gated Sparse Autoencoders!
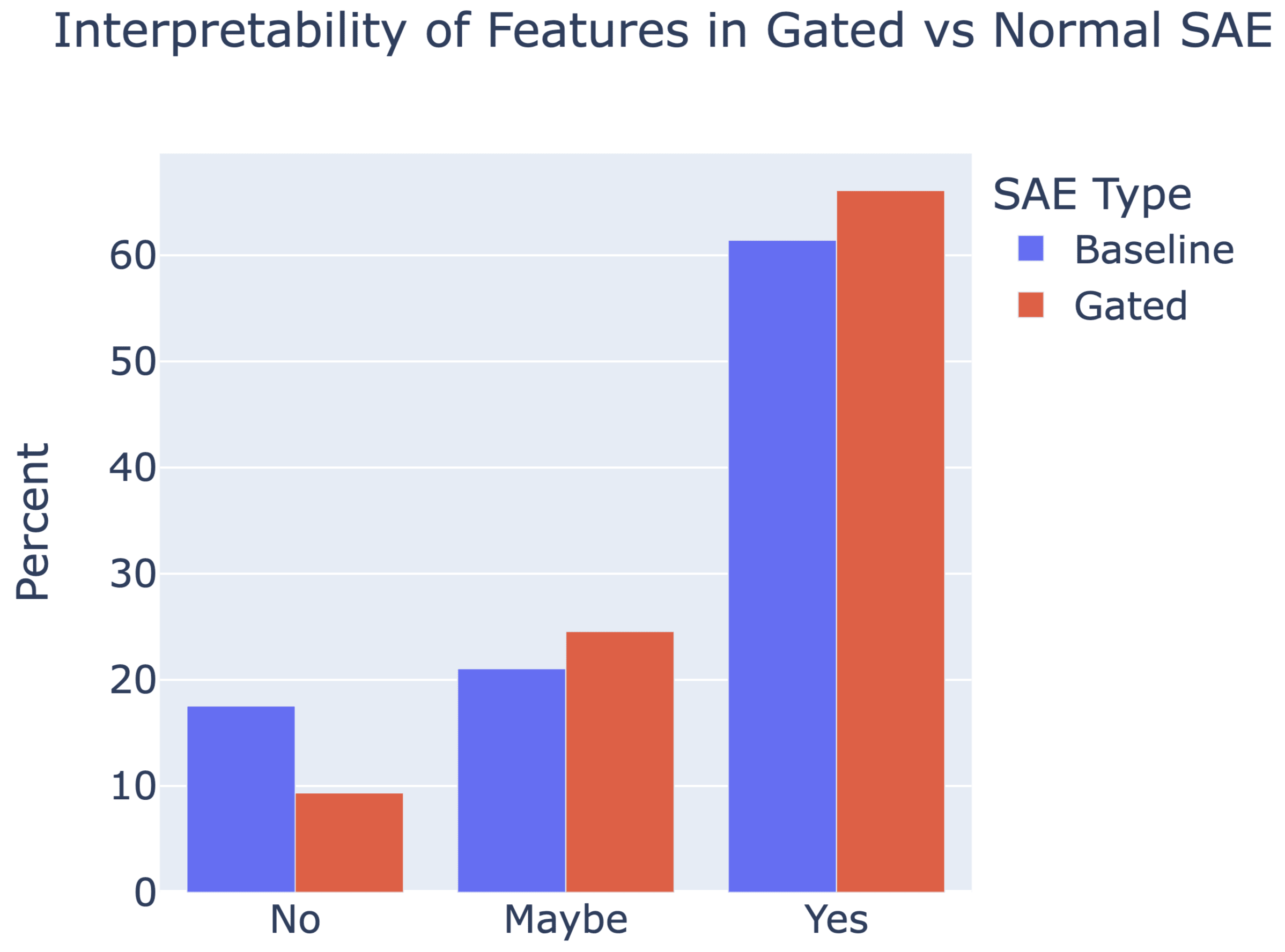
Gated SAEs are a new Sparse Autoencoder architecture that seems to be a significant Pareto-improvement over normal SAEs, verified on models up to Gemma 7B. They are now our team's preferred way to train sparse autoencoders, and we'd love to see them adopted by the community! (Or to be convinced that it would be a bad idea for them to be adopted by the community!)

They achieve similar reconstruction with about half as many firing features, and while being either comparably or more interpretable (confidence interval for the increase is 0%-13%).
See Sen's Twitter summary, my Twitter summary, and the paper!
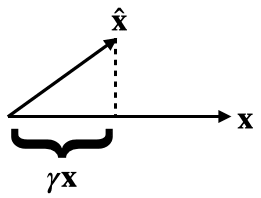

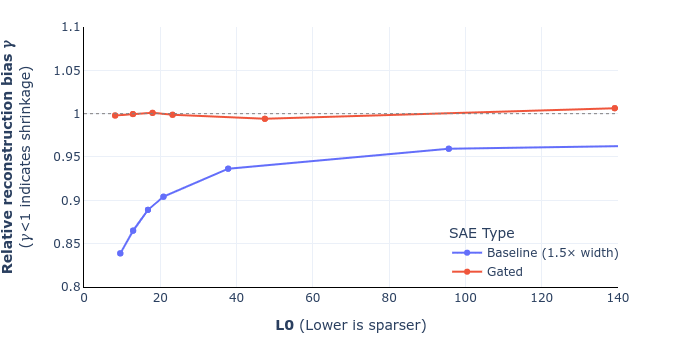
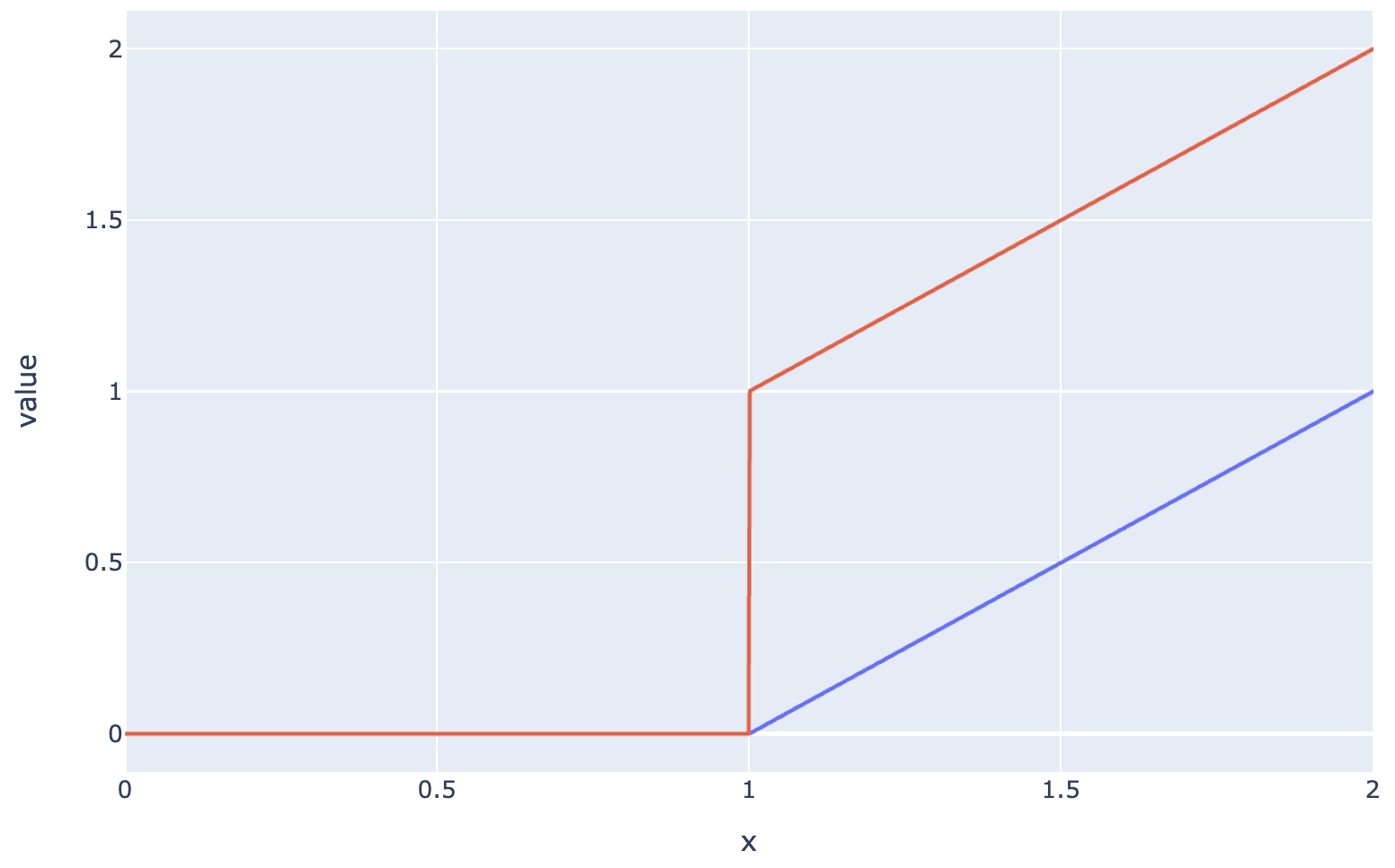
Another question: any particular reason to expect ablate-to-zero to be the most relevant baseline? In my experiments, I find ablate to zero to completely destroy the loss. So it's unclear whether 90% recovered on this metric actually means that much - GPT-2 probably recovers 90% of the loss of GPT-4 under this metric, but obviously GPT-2 only explains a tiny fraction of GPT-4's capabilities. I feel like a more natural measure may be for example the equivalent compute efficiency hit.
It doesn't seem like a huge deal to depend on the existence of smaller LLMs - they'll be cheap compared to the bigger one, and many LM series already contain smaller models. Not transferring between sites seems like a problem for any kind of reconstruction based metric because there's actually just differently important information in different parts of the model.