I've recently had several conversations about John Wentworth's post The Pointers Problem. I think there is some confusion about this post, because there are several related issues, which different people may take as primary. All of these issues are important to "the pointers problem", but John's post articulates a specific problem in a way that's not quite articulated anywhere else.
I'm aiming, here, to articulate the cluster of related problems, and say a few new-ish things about them (along with a lot of old things, hopefully put together in a new and useful way). I'll indicate which of these problems John was and wasn't highlighting.
This whole framing assumes we are interested in something like value learning / value loading. Not all approaches rely on this. I am not trying to claim that one should rely on this. Approaches which don't rely on human modeling are neglected, and need to be explored more.
That said, some form of value loading may turn out to be very important. So let's get into it.
Here's the list of different problems I came up with when trying to tease out all the different things going on. These problems are all closely interrelated, and feed into each other to such a large extent that they can seem like one big problem.
(0. Goodhart. This is a background assumption. It's what makes getting pointers right important.)
- Amplified values. Humans can't evaluate options well enough that we'd just want to optimize the human evaluation of options. This is part of what John is describing.
- Compressed pointer problem. We can't realistically just give human values to a system. How can we give a system a small amount of information which "points at" human values, so that it will then do its best to learn human values in an appropriate way?
- Identifiability problems for value learning. This includes Stuart's "no free lunch" argument that we can't extract human values (or beliefs) just with standard ML approaches.
- Ontology mismatch problem. Even if you could extract human values (and beliefs) precisely, whatever that means, an AI doesn't automatically know how to optimize them, because they're written in a different ontology than the AI uses. This is what John is primarily describing.
- Wireheading and human manipulation. Even if we solve both the learning problem and the ontology mismatch problem, we may still place the AI under some perverse incentives by telling it to maximize human values, if it's also still uncertain about those values. Hence, there still seems to be an extra problem of telling the AI to "do what we would want you to do" even after all of that.
0. Goodhart
As I mentioned already, this is sort of a background assumption -- it's not "the pointers problem" itself, but rather, tells us why the pointers problem is hard.
Simply put, Goodhart's Law is an argument that an approximate value function is almost never good enough. You really need to get quite close before optimizing the approximate version is a good way to optimize human values. Scott gives four different types of Goodhart, which all feed into this.
Siren Worlds
Even if we had a perfect human model which we could use to evaluate options, we would face the Siren Worlds problem: we optimize for options which look good to humans, but this is different from options which are good.
We can't look at (even a sufficient summary of) the entire universe. Yet, we potentially care about the whole universe. We don't want to optimize just for parts we can look at or summarize, at the expense of everything else.
This shows that, to solve the pointers problem, we need to do more than just model humans perfectly. John's post talked about this problem in terms of "lazy evaluation": we humans can only instantiate small parts of our world model when evaluating options, but our "true values" would evaluate everything.
I'm referring to that here as the problem of specifying amplified values.
1. Amplified Values Problem
The problem is: humans lack the raw processing power to properly evaluate our values. This creates a difficulty in what it even means for humans to have specific values. It's easy to say "we can't evaluate our values precisely". What's difficult is to specify what it would mean for us to evaluate our values more precisely.
A quick run-down of some amplification proposals:
- Iterated Amplification: amplification is defined recursively as the answer a human would give if the human had help from other amplified humans who could answer questions.
- Debate: the amplified human opinion is defined as the winner of an idealized debate process, judged by humans (with AI debaters).
- CEV: we define amplified human values as what we would think if we were somewhat smarter, knew somewhat more, and had grown up longer together.
- Recursive Reward Modeling: we define human values as a utility function which humans specify with the help of powerful agents, who are themselves aligned through a recursive process.
Aside: if we think of siren worlds as the primary motivator for amplification, then Stuart's no-indescribable-hellworlds hypothesis is very relevant for thinking about what amplification means. According to that hypothesis, bad proposals must be "objectionable" in the sense of having an articulable objection which would make a human discard the bad proposal. If this is the case, then debate-like proposals seem like a good amplification technique: it's the systematic unearthing of objections.
Now, a viable proposal needs two things:
- An abstract statement of what it means to amplify;
- A concrete method of getting there.
For example, Iterated Amplification gives HCH as the abstract model of an amplified human, and the iterated amplification training method as its concrete proposal for getting there.
Crossing this bridge is the subject of the next point, compressed pointers:
2. Compressed Pointer Problem
The basic idea behind compressed pointers is that you can have the abstract goal of cooperating with humans, without actually knowing very much about humans. In a sense, this means having aligned goals without having the same goals: your goal is to cooperate with "human goals", but you don't yet have a full description of what human goals are. Your value function might be much simpler than the human value function.
In machine-learning terms, this is the question of how to specify a loss function for the purpose of learning human values.
Some important difficulties of compressed pointers are that they seem to lead to new problems of their own, in the form of wireheading and human manipulation problems. We will discuss those problems later on.
The other important sub-problem of compressed pointers is, well, how do you actually do the pointing? An assumption behind much of value learning research is that we can point to the human utility function via a loss function which learns a model of humans which decomposes them into a utility function, a probability distribution, and a model of human irrationality. We can then amplify human values just by plugging that utility function into better beliefs and a less irrational decision-making process. I argue against making such a strong distinction between values and beliefs here, here, and here, and will return to these questions in the final section. Stuart Armstrong argues that such decompositions cannot be learned with standard ML techniques, which is the subject of the next section.
3. Identifiability Problems for Value Learning
Stuart Armstrong's no-free-lunch result for value learning shows that the space of possible utility functions consistent with data is always too large, and we can't eliminate this problem even with Occam's razor: even when restricting to simple options, it's easy to learn precisely the wrong values (IE flip the sign of the utility function).
One thing I want to emphasize about this is that this is just one of many possible non-identifiability arguments we could make. (Identifiability is the learning-theoretic property of being able to distinguish the correct model using the data; non-identifiability means that many possibilities will continue to be consistent, even with unlimited data.)
Representation theorems in decision theory, such as VNM, often uniquely give us the utility function of an agent from a set of binary decisions which the agent would make. However, in order to get a unique utility function, we must usually ask the agent to evaluate far more decisions than is realistic. For example, Savage's representation theorem is based on evaluating all possible mappings from states to outcomes. Many of these mappings will be nonsensical -- not only never observed in practice, but nowhere near anything which ever could be observed.
This suggests that just observing the actual decisions an agent makes is highly insufficient for pinning down utility functions. What the human preferred under the actual circumstances does not tell us very much about what the human would have preferred under different circumstances.
Considerations such as this point to a number of ways in which human values are not identifiable from human behavior alone. Stuart's result is particularly interesting in that it strongly rules out fixing the problem via simplicity assumptions.
Learning with More Assumptions
Stuart responds to this problem by suggesting that we need more input from the human. His result suggests that the standard statistical tools alone won't suffice. Yet, humans seem to correctly identify what each other want and believe, quite frequently. Therefore, humans must have prior knowledge which helps in this task. If we can encode those prior assumptions in an AI, we can point it in the right direction.
However, another problem stands in our way even then -- even if the AI could perfectly model human beliefs and values, what if the AI does not share the ontology of humans?
4. Ontology Mismatch Problem
As I stated earlier, I think John's post was discussing a mix of the ontology mismatch problem and the amplification problem, focusing on the ontology mismatch problem. John provided a new way of thinking about the ontology mismatch problem, which focused on the following claim:
Claim: Human values are a function of latent variables in our model of the world.
Humans have latent variables for things like "people" and "trees". An AI needn't look at the world in exactly the same way, so it needn't believe things exist which humans predicate value on.
This creates a tension between using the flawed models of humans (so that we can work in the human ontology, thus understanding human value) vs allowing the AI to have better models (but then being stuck with the ontology mismatch problem).
As a reminder of what latent variables are, let's take a look at two markov networks which both represent the relationship of five variables:
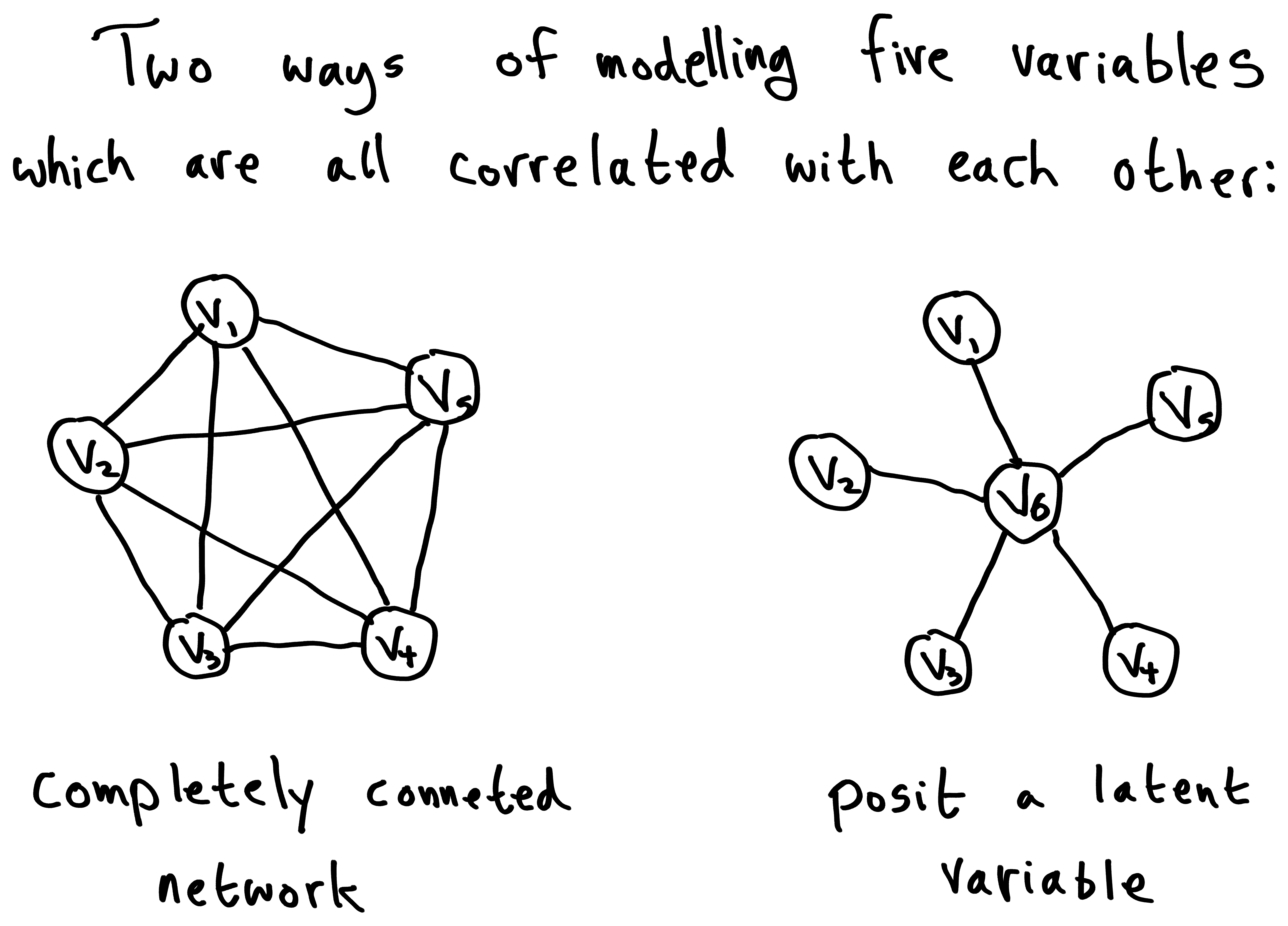
In the example on the left, we posit a completely connected network, accounting for all the correlations. In the example on the right, we posit a new latent variable which accounts for the correlations we observed.
As a working example, depression is something we talk about as if it were a latent variable. However, many psychologists believe that it is actually a set of phenomena which happen to have strong mutually reinforcing links.
Considered as a practical model, we tend to prefer models which posit latent variables when:
- They fit the data better, or equally well;
- Positing latent variables decreases the description complexity;
- The latent variable model can be run faster (or has a tolerable computational cost).
Mother nature probably has similar criteria for when the brain should posit latent variables.
However, considered as an ontological commitment, it seems like we only want to posit latent variables when they exist. When a Bayesian uses the model on the right instead of the model on the left, they believe in as an extra fact which can in principle vary independently of the other variables. ("Independently" in the logical sense, here, not the probabilistic sense.)
So there is ambiguity between latent variables as pragmatic tools vs ontological commitments. This leads to our problem: a Bayesian (or a human), having invented latent variables for the convenience of their predictive power, may nonetheless ascribe value to specific states of those variables. This presents a difficulty if another agent wishes to help such an agent, but does not share its ontological commitments.
Helper's Perspective
Suppose for a moment that humans were incapable of understanding depression as a cluster of linked variables, simply because that view of reality was too detailed to hold in the mind -- but that humans wanted to eliminate depression. Imagine that we have an AI which can understand the details of all the linked variables, but which lacks a hidden variable "depression" organizing them all. The AI wants to help humans, and in theory, should be able to use its more detailed understanding of depression to combat it more effectively. However, the AI lacks a concept of depression. How can it help humans combat something which isn't present in its understanding of reality?
What we don't want to do is form the new goal of "convince humans depression has been cured". This is a failure mode of trying to influence hidden variables you don't share.
Another thing we don't want to do is just give up and use the flawed human model. This will result in poor performance from the AI.
John Wentworth suggests taking a translation perspective on the ontology mismatch problem: we think of the ontologies as two different languages, and try to set up the most faithful translation we can between the two. The AI then tries to serve translated human values.
I think this perspective is close but not quite right. First note that there may not by any good translation between the two. We would like to gracefully fail in that case, rather than sticking with the best translation. (And I'd prefer that to be a natural consequence of our defined targets, rather than something extra added on.) Second, I don't think there's a strong justification for translation when we look at things from our perspective.
Helpee's Perspective
Imagine that we're this agent who wants to get rid of depression but can't quite understand the universe in which depression comes apart into several interacting variables.
We are capable of watching the AI and forming beliefs about whether it is eliminating depression. We are also capable of looking at the AI's design (if not its learned models), and forming beliefs about things such as whether the AI is trying to fool us.
We can define what it means for the AI to track latent variables we care about at the meta-level: not that it uses our exact model of reality, but that in our model, its estimates of the latent variables track the truth. Put statistically, we need to believe there is a (robust) correlation between the AI's estimate of the latent variable and the true value. (Not a correlation between the AI's estimation and our estimation -- that would tend to become true as a side effect, but if it were the target then the AI would just be trying to fool us.)
Critically, it is possible for us to believe that the AI tracks the truth better than we do. IE, it will be possible for us to become confident that "the AI understands depression better than we do" and have more faith in the AI's estimation of the latent variable than our own.
To see why, imagine that you (with your current understanding of depression) were talking to a practicing, certified psychiatrist (an MD) who also has an undergraduate degree in philosophy (has a fluent understanding of philosophy of language, philosophy of science, and philosophy of mind -- and, from what you gather, has quite reasonable positions in all these things), and, on top of all that, a PhD in research psychology. This person has just recently won a Nobel prize for a new cognitive theory of depression, which has (so far as you can tell) contributed significantly to our understanding of the brain as a whole (not only depression), and furthermore, has resulted in more effective therapies and drugs for treating depression.
You might trust this person considerably more than yourself, when it comes to diagnosing depression and judging fine degrees of how depressed a person is.
To have a model which includes a latent variable is not, automatically, to believe that you have the best possible model of that latent variable. However, our beliefs about what constitutes a more accurate way of tracking the truth are subjective -- because hidden variables may not objectively exist, it's up to us to say what would constitute a more accurate model of them. This is part of my concept of normativity.
So, I believe a step in the right direction would be for AIs to try to maximize values according to models which, according to human beliefs, track the things we care about well.
This captures the ontology problem and the value amplification problem at the same time; the AI is trying to use "better" models in precisely the sense that we care about for both problems.
Do we need to solve the ontology mismatch problem?
It bears mentioning that we don't necessarily need to be convinced that the AI tracks the truth of variables which we care about, to be convinced that the AI enacts policies which accomplish good things. This is part of what policy approval was trying to get at, by suggesting that an AI should just be trying to follow a policy which humans expect to accomplish good things.
If we can formalize learning normativity, then we might just want an AI to be doing what is "normatively correct" according to the human normativity concept it has learned. This might involve tracking the truth of things we care about, but it might also involve casting aside unnecessary hidden variables such as "depression" and translating human values into a new ontology. That's all up to our normative concepts to specify.
Ghost Problems
Since a lot of the aim of this post is to clarify John's post, I would be remiss if I didn't deal with the ghost problem John mentioned, which I think caused some confusion. (Feel free to skip this subsection if you don't care!) This was a running example which was mentioned several times in the text, but it was first described like this:
I don't just want to think my values are satisfied, I want them to actually be satisfied. Unfortunately, this poses a conceptual difficulty: what if I value the happiness of ghosts? I don't just want to think ghosts are happy, I want ghosts to actually be happy. What, then, should the AI do if there are no ghosts?
The first point of confusion is: it seems fine if there are no ghosts. If there aren't in fact any ghosts, we don't have to worry about them being happy or sad. So what's the problem?
I think John intended for the ghost problem to be like my depression example -- we don't just stop caring about the thing if we learn that depression isn't well-modeled as a hidden variable. In service of that, I propose the following elaboration of the ghost problem:
You, and almost everyone you know, tries to act in such a way as to make the ghosts of your ancestors happy. This idea occupies a central place in your moral framework, and plays an important role in your justification of important concepts such as honesty, diligence, and not murdering family members.
Now it's clear that there's a significant problem if you suddenly learn that ghosts don't exist, and can't be happy or sad.
Now, the second potential confusion is: this still poses no significant problem for alignment so long as your belief distribution includes how you would update if you learned ghosts weren't real. Yes, all the main points of your values as you would explain them to a stranger have to do with ghosts; but, your internal belief structures are perfectly capable of evaluating situations in which there are no ghosts. So long as the AI is good enough at inferring your values to understand this, there's no issue.
Again, I think John wanted to point to basic ontological problems, as with my example where humans can't quite comprehend the world where depression isn't ontologically fundamental. So let's further modify the problem:
If you found out ghosts didn't exist, you wouldn't know what to do with yourself. Your beliefs would become incoherent, and you wouldn't trust yourself to know what is right any more. Yes, of course, you would eventually find something to believe, and something to do with yourself; but from where you are standing now, you wouldn't trust that those reactions would be good in the important sense.
Another way to put it is that the belief in ghosts is so important that we want to invoke the value amplification problem for no-ghost scenarios: although you can be modeled as updating in a specific way upon learning there aren't any ghosts, you yourself don't trust that update, and would want to think carefully about what might constitute good and bad reasoning about a no-ghost universe. You don't want your instinctive reaction to be takes as revealing your true values; you consider it critical, in this particular case, to figure out how you would react if you were smarter and wiser.
As an example, here are three possible reactions to a no-ghost update:
- You might discard your explanations in terms of ghosts, but keep your values otherwise as intact as possible: continue to think lying is bad, continue to avoid murdering family members, etc.
- You might discard any values which you explained in terms of ghosts, keeping what little remains: you enjoy physical pleasure, beauty, (non-ceremonial) dancing, etc. You no longer attach much value to truth, life, family, or diligence.
- You might be more selective, preserving some things you previously justified via ghosts, but not others. For example, you might try to figure out what you would have come to value anyway, vs those places where the ghost ideology warped your values.
Simply put, you need philosophical help to figure out how to update.
This is the essence of the ontology mismatch problem.
Next, we consider a problem which we may encounter even if we solve value amplification, the identifiability problem, and the ontology mismatch problem: wireheading and human manipulation.
5. Wireheading and Human Manipulation
In my first "stable pointers to value" post, I distinguished between the easy problem of wireheading and the hard problem of wireheading:
- The Easy Problem: the wireheading problem faced by AIXI and other RL-type agents. These agents want to gain control of their own reward buttons, in order to press them continuously. This problem can be solved by evaluating the expected utility of plans/policies inside the planning/policy optimization loop, rather than only giving feedback on actions actually taken (leaving the plan/policy optimization loop to evaluate based on expected reward). Daniel Dewey referred to this architecture as observation-utility maximization.
- The Hard Problem: even if we successfully point to human values as a thing to learn (solving the identifiability problem and the ontology mismatch problem, amongst other things), human values are manipulable. This introduces perverse incentives for a value-learning systems, if those systems must make decisions while operating under some remaining uncertainty about human values. Specifically, such systems are incentivised to manipulate human values.
Simply put, the easy wireheading problem is that the AI might wirehead itself. The hard wireheading problem is that the AI might wirehead us, by manipulating our values to be easier to satisfy.
This is related to the ontology mismatch problem in that poor solutions to that problem might especially incentivize a system to wirehead or otherwise manipulate humans, but is mostly an independent problem.
I see this as the essence of the compressed pointer problem as I described it in Embedded Agency (ie, my references to "pointers" in the green and blue sections). However, that was a bit vague and hand-wavy.
Helping Human
One proposal to side-step this problem is: always and only help the current human, as of this very moment (or perhaps a human very slightly in the past, EG the one whose light-waves are just now hitting you). This ensures that no manipulation is possible, making the point moot. The system would only ever be manipulative in the moment if that best served our values in the moment. (Or, if the system wrongly inferred such.)
This solution can clearly be dynamically inconsistent, as the AI's goal pointer keeps changing. However, it is only as dynamically inconsistent as the human. In some sense, this seems like the best we can do: you cannot be fully aligned with an agent who is not fully aligned with themselves. This solution represents one particular compromize we can make.
Another compromise we can make is to be fully aligned with the human at the moment of activating the AI (or again, the moment just before, to ensure causal separation with a margin for error). This is more reflectively stable, but will be less corrigible: to the extent humans are not aligned with our future selves, the AI might manipulate our future selves or prevent them from shutting it down, in service of earlier-self values. (Although, if the system is working correctly, this will only happen if your earlier selves would endorse it.)
Another variation is that you myopically train the system to do what HCH would tell you to do at each point. (I'll keep it a bit vague -- I'm not sure exactly what question you would want to prompt HCH with.) This type of approach subsumes not only human values, but the problem of planning to accomplish them, into the value amplification problem. This is pretty different, but I'm lumping it in the same basket for theoretical reasons which will hopefully become clear soon.
Time Travel Problems
The idea of helping the current human, as a way to avoid manipulation, falls apart as soon as we admit the possibility of time travel. If the agent can find a way to use time travel to manipulate the human, we get the very same problem we had in the first place. Since this might be quite valuable for the agent, it might put considerable resources toward the project. (IE, there is not necessarily a "basin of corrigibility" here, where we've specified an agent that is aligned enough that it'll naturally try and correct flaws in its specification -- there might be mechanisms which could accomplish this, but it's not going to happen just from the basic idea of forwarding the values of the current human.)
Similarly, in my old post on this topic I describe an AI system whose value function is specified by CEV, but which finds out that there is an exact copy of itself embedded therein:
As a concrete example, suppose that we have constructed an AI which maximizes CEV: it wants to do what an imaginary version of human society, deliberating under ideal conditions, would decide is best. Obviously, the AI cannot actually simulate such an ideal society. Instead, the AI does its best to reason about what such an ideal society would do.
Now, suppose the agent figures out that there would be an exact copy of itself inside the ideal society. Perhaps the ideal society figures out that it has been constructed as a thought experiment to make decisions about the real world, so they construct a simulation of the real world in order to better understand what they will be making decisions about. Furthermore, suppose for the sake of argument that our AI can break out of the simulation and exert arbitrary control over the ideal society's decisions.
Naively, it seems like what the AI will do in this situation is take control over the ideal society's deliberation, and make the CEV values as easy to satisfy as possible -- just like an RL agent modifying its utility module.
Or, with respect to my example of an agent trained to do whatever HCH would tell it to do, we might imagine what would happen if HCH reasons about the agent in sufficient detail that its decisions influence HCH. Then the agent might learn to manipulate HCH, to the degree that such a thing is possible.
My point is not that we should necessarily worry about these failure modes. If it comes down to it, we might be willing to assume time travel isn't possible as one of the few assumptions we need in order to argue that a system is safe -- or posit extra mechanisms to keep our AI from existing inside of CEV, or keep it from being simulated within HCH, or allow it to exist but ensure it can't manipulate those things, or what-have-you.
What interests me is the basic problem which applies to all of these cases. We could call in the "very hard wireheading problem":
- The Very Hard Problem of Wireheading: like the Hard Problem, but under the assumption that there's absolutely no way to rule out manipulation, IE, we assume manipulation is going to be possible no matter what we do.
There's probably no perfect solution to this problem. Yet, when I sit staring at the problem, I have a strong desire to "square the circle" -- like there should be something it means to be non-manipulatively aligned (with something that you could manipulate), something theoretically elegant and not a hack.
Probably the best thing I've seen is a proposal which I think originates from Stuart Armstrong, which is that you simply remove the manipulative causal pathways from your model before making decisions. I'm not sure how you are supposed to identify which pathways are manipulative vs non-manipulative, in order to remove them, but if you can, you get a notion of optimizing without manipulating.
This makes things very dependent on your prior -- to give an extreme case, suppose humans are perfectly manipulable; we take on whatever values the AI suggests. Then when the AI freezes the causal pathways of manipulation, its "human values" it attempts to cooperate will be a mixture of all the things it might tell humans to value, each according to its prior probability.
I had some other objections, too, EG if we remove those causal pathways, our model could get pretty weird, assigning high probability to outcomes which are improbable or even impossible. For example, suppose the AI is asked not to manipulate Sally (its creator, who it is aligned with), but in fact, Ben and Sally are equally prone to manipulation, and in the same room, so hear the same messages from the AI. The AI proceeds as if Sally is immune to manipulation (when she's not). This might involve planning for Sally and Ben to have different reactions to an utterance (when in fact they have exactly the same reaction). So the AI might make plans which end up making no sense in the real world.
I could say more about trying to solve the Very Hard Problem, but I suspect I've already written too much rather than too little.
Conclusion
If all of the above are sub-problems of the pointers problem, what is the pointers problem itself? Arguably, it's the whole outer alignment problem. I don't want to view it quite that way, though. I think it is more like a particular view on the outer alignment problem, with an emphasis on "pointing": the part of the problem that's about "What do we even mean by alignment? How can we robustly point an AI at external things which are ontologically questionable? How do we give feedback about what we mean, without incentivizing a system to wirehead or manipulate us? How can we optimize things which live in the human ontology, without incentivizing a system to delude us?"
There's a small element of inner alignment to this, as well. Although an RL agent such as AIXI will want to wirehead if it forms an "accurate" model of how it gets reward, we can also see this as only one model consistent with the data, another being that reward is actually coming from task achievement (IE, the AI could internalize the intended values). Although this model will usually have at least slightly worse predictive accuracy, we can counterbalance that with process-level feedback which tells the system that's a better way of thinking about it. (Alternatively, with strong priors which favor the right sorts of interpretations.) This is inner alignment in the sense of getting the system to think in the right way rather than act in the right way, to avoid a later treacherous turn. (However, not in the sense of avoiding inner optimizers.)
Similarly, human manipulation could be avoided not by solving the incentive problem, but rather, by giving feedback to the effect that manipulation rests on an incorrect interpretation of the goal. Similar feedback-about-how-to-think-about-things could address the ontology mismatch problem and the value amplification problem.
In order to use this sort of solution, the AI system needs to think of everything as a proxy; no feedback is taken as a gold standard for values. This is similar to Eliezer's approach to wireheading, Goodhart, and manipulation in CFAI (see especially section 5, especially 5.5), although I don't think that document contains enough to make the idea really work.