Here's something that just came to my mind: simulating a human brain is probably very parallelizable, since it has a huge number of neurons, and each neuron fires a couple hundred times per second at most. So if you have some problem which is difficult but still can be solved by one person, it's probably more efficient to give it to one person running at 1000x speedup, not 1000 people at 1x speed who have to pay fixed costs to understand the problem and communication costs to split it up. And as computers get faster, the arithmetic keeps working - a 1M em is better than 1K 1K ems. So it seems possible that the most efficient population of ems will be quite small, one or a handful of people per data center. It's true that as knowledge grows, more ems are needed to understand it all; but Von Neumann was a living example that one person can understand quite a lot of things, and knowledge aids like Wikipedia will certainly be much cheaper to run than ems.
In the slightly longer perspective, I expect our handful of ems to come up with enough self improvement tech, like bigger working memory or just adding more neurons, that a small population can continue to be optimal. No point paying the "fixed costs of being human" (ancestral circuitry) for billions or trillions of less efficient ems, if a smaller number of improved ems gives a better benefit ratio for that cost.
So in short, it seems to me that the world with lots and lots of ems will simply never arrive, and the whole "duplicator" concept is a bit of red herring. Instead we should imagine a world with a much smaller number of "Wise Ones", human-derived entities with godlike speed and understanding. They will probably be quite happy about their lot in life, not miserable and exploited. And since they'll have obvious incentive to improve coordination among themselves as well, that likely leads to the usual singleton scenario.
I don't know if this argument is new, welcome to be shown wrong.
This seems to ignore all of the inefficiencies in parallelization.
Processors run more inefficiently the faster you run them (this is the entire reason for 'underclocking'), so running 1 em of hardware 1000x faster will cost you >>1000x. (IIRC, Hanson has a lot of discussion of this point in Age of Em about how the cost of speed will result in tiers: some ems would run at the fastest possible frequencies but only for a tiny handful of tasks which justify the cost, somewhat analogous to HFT vs most computing tasks today - they may need 1 millisecond less latency and will pay for a continent-wide system of microwave towers and commission custom FPGAs/ASICs, but you sure don't!)
There's also Amdahl's law: anything you do in parallel with n processors can be done serially with _n_x the time with zero penalty, but vice-versa is not at all true - many tasks just can't be parallelized, or have only a few parts which can be parallelized, and the parallelization usually comes at at least some overhead (and this is in addition to the penalty you pay for running processors faster).
If there are fixed costs, it would make more sense to do something like run 1 em on a premium processor, and then fork it as soon as possible to a bunch of slow efficient processors to amortize the fixed cost; you wouldn't fork out for an super-exotic crazy (Cray?) 1000x faster processor to do it all in one place.
To Amdahl's law - I think simulating a brain won't have any big serial bottlenecks. Split up by physical locality, each machine simulates a little cube of neurons and talks to machines simulating the six adjacent cubes. You can probably split one em into a million machines and get like a 500K times speedup or something. Heck, maybe even more than a million times, because each machine has better memory locality. If your intuition is different, can you explain?
To overclocking - it seems you're saying parallelization depends on it somehow? I didn't really understand this part.
A brain has serial bottlenecks in the form of all the communication between neurons, in the same way you can't simply shard GPT-3-173b onto 173 billion processors to make it run 173 billion times faster. Each compute element is going to be stuck waiting on communication with the adjacent neurons. At some point, you have 1 compute node per neuron or so (this is roughly the sort of hardware you'd expect ems to run on, brain-sized neuromorphic hardware, efficiently implementing something like spiking neurons), and almost all the time is spent idle waiting for inputs/outputs. At that point, you have saturated your available parallelism and Amdahl's law rules. Then there's no easy way to apply more parallelism: if you have some big chunks of brains which don't need to communicate much and so can be parallelized for performance gains... Then you just have multiple brains.
To overclocking - it seems you're saying parallelization depends on it somehow? I didn't really understand this part.
Increasing clock speed has superlinear costs.
At that point, you have saturated your available parallelism and Amdahl's law rules. [...] Then you just have multiple brains.
I think the point (or in any case my takeaway) is that this might be Giant Cheesecake Fallacy. Initially, there's not enough hardware for running just a single em on the whole cluster to become wasteful, so this is what happens instead of running more ems slower, since serial work is more valuable. By the time you run into the limits of how much one em can be parallelized, the parallelized ems have long invented a process for making their brains bigger, making use of more nodes, preserving the regime of there only being a few ems who run on most of the hardware. This is more about personal identity of the ems than computing architecture, as a way of "making brains bigger" may well look like "multiple brains", they are just brains of a single em, not multiple ems or multiple instances of an em.
My point is, the whole "age of em" might well come and go in the following regime: many neurons per processor, many processors per em, few ems per data center. In this regime, adding more processors to an em speeds up their subjective time almost linearly. You may ask, how can "few ems per data center" stay true? First of all, today's data centers are like 100K processors, while one em has 100B neurons and way more synapses, so adding processors will make sense for quite awhile. Second of all, it won't take that much subjective time for a handful of Von Neumann-smart ems to figure out how to scale themselves to more neurons per em, allowing "few, smarter ems per data center" to go on longer, which then leads smoothly to the post-em regime.
Also your mentions of clock speed are still puzzling to me. My whole argument still works if there's only ever one type of processors with one clock speed fixed in stone.
First of all, today's data centers are like 100K processors, while one em has 100B neurons and way more synapses, so adding processors will make sense for quite awhile.
Today's data centers are completely incapable of running whole brains. We're discussing extremely hypothetical hardware here, so what today's data centers do is at best a loose analogy. The closest we have today is GPUs and neuromorphic hardware designed to implement neurons at the hardware level. GPUs already are a big pain to run efficiently in clusters because lack of parallelization means that communication between nodes is a major bottleneck, and communication within GPUs between layers is also a bottleneck. And neuromorphic hardware (or something like Cerebras) shows that you can create a lot of neurons at the hardware level; it's not an area I follow in any particular detail, but for example, IBM's Loihi chip implements 1,024 individual "spiking neural units" per core, 128 cores per chip, and they combine them in racks of 64 chips maxing out at 768 for a total of 100 million hardware neurons - so we are already far beyond any '100k processors' in terms of total compute elements. I suppose we could wind up having relatively few but very powerful serial compute elements for the first em, but given how strong the pressures have been to go as parallel as possible as soon as possible, I don't see much reason to expect a 'serial overhang'.
Okay, yeah, I had no idea that this much parallelism already existed. There could be still a reason for serial overhang (serial algorithms have more clever optimizations open to them, and neurons firing could be quite sparse at any given moment), but I'm no longer sure things will play out this way.
You seem to be talking about a compute-dominated process, with almost perfect data locality. I suspect that brain emulation may be almost entirely communication-dominated with poor locality and (comparatively) very little compute. Most neurons in the brain have a great many synapses, and the graph of connections has relatively small diameter.
So emulating any substantial part of a human brain may well need data from most of the brain every "tick". Suppose emulating a brain in real time takes 10 units per second of compute, and 1 unit per second of data bandwidth (in convenient units where a compute node has 10 units per second of each). So a single node is bottlenecked on compute and can only run at real time.
To achieve 2x speed you can run on two nodes to get the 20 units per second of compute capability, but your data bandwidth requirement is now 4 units/second: both the nodes need full access to the data, and they need to get it done in half the time. After 3x speed-up, there is no more benefit to adding nodes. They all hit their I/O capacity, and adding more will just slow them all down due to them all needing to access every node's data every tick.
This is even making the generous assumption that links between nodes have the same capacity and no more latency or coordination issues than a single node accessing its own local data.
I've obviously just made up numbers to demonstrate scaling problems in an easy way here. The real numbers will depend upon things we still don't know about brain architecture, and on future technology. The principle remains the same, though: different resource requirements scale in different ways, which yields a "most efficient" speed for given resource constraints, and it likely won't be at all cost-effective to vary from that by an order of magnitude in either direction.
Yeah, maybe my intuition was pointing a different way: that the brain is a physical object, physics is local, and the particular physics governing the brain seems to be very local (signals travel at tens of meters per second). And signals from one part of the brain to another have to cross the intervening space. So if we divide the brain into thousands of little cubes, then each one only needs to be connected to its six neighbors, while having plenty of interesting stuff going inside - rewiring and so on.
Edit: maybe another aspect of my intuition is that "tick" isn't really a thing. Each little cube gets a constant stream of incoming activations, at time resolution much higher than typical firing time of one neuron, and generates a corresponding outgoing stream. Generating the outgoing stream requires simulating everything in the cube (at similar high time resolution), and doesn't need any other information from the rest of the brain, except the incoming stream.
Thanks, making use of the relatively low propagation speed hadn't occurred to me.
That would indeed reduce the scaling of data bandwidth significantly. It would still exist, just be not quite as severe. Area versus volume scaling still means that bandwidth dominates compute as speeds increase (with volume emulated per node decreasing), just not quite as rapidly.
I didn't mean "tick" as a literal physical thing that happens in brains, just a term for whatever time scale governs the emulation updates.
I know you've probably already read it but just in case you haven't: this post is basically the premise of Age of Em.
Doesn't this premise (the duplicator) have a problem of being exceedingly implausible? Assuming it's implemented by non-destructive imaging followed by atom-level construction of a person, both of those technologies might as well be magic from today's point of view. I wonder whether either is even physically possible. In any case, a civilization capable of such technology is already unrecognizably different from our own.
That's quite a different situation from more common premises, such as superintelligent AGI or genetic engineering for enhancement, both of which are obviously physically possible and seem feasible with non-magical levels of technology.
If there were some way that the duplicator could work out if the AGI and genetics don't, then maybe it'd be worth considering, but in the case of genetic engineering for enhancement, it's actually strictly easier than the duplicator, in the sense that, if you had atom-level construction of a whole person, you'd in particular be able to atom-level construction of a human cell with a specified genome inside it (the goal of HGP-Write), and we already know enough today to plausibly specify a highly-enhanced human genome.
I think Holden partly put the cart before the horse by talking about consequences of a duplicator without even trying to show that a duplicator is possible. Perhaps the previous article has his answer:
[suppose] You think our economic and scientific progress will stagnate. Today's civilizations will crumble, and many more civilizations will fall and rise. Sure, we'll eventually get the ability to expand throughout the galaxy. But it will take 100,000 years. That's 10x the amount of time that has passed since human civilization began in the Levant.
The difference between your timeline and mine isn't even a pixel, so it doesn't show up on the chart. In the scheme of things, this "conservative" view and my view are the same.
Except that Holden is building "the most important century" series, and discussing a person-cloning technology that could be 400 years away, or 99,900, doesn't make the case for 21st-century-as-most-important.
Also, the duplicator route is one that makes "the little people" like myself fairly irrelevant. My IQ is only like 125, and wouldn't this duplicator be reserved for the top 0.1% or so? Maybe you need something like a 150 IQ to be worth duplicating, unless you are somebody like Beyoncé or Bill Gates with wealth and/or a proven track record. Or perhaps Xi's hand-picked successor takes over the world and only duplicates his most loyal followers and scientists. Even if this century is the most important, that matters little to me if I cannot participate in the revolution.
In the current world, what I need to enable me to meaningfully influence the future is money I don't have, but I am more likely to get that than new genius abilities. Now, I don't oppose duplicators, but it seems like we're very far from having one. Just bringing people out of poverty and wage-slavery (e.g. via UBI and/or an Open Engineering program) would quickly enable a lot more smart people to do smart things rather than just obeying the boss's orders.
I think there may be a problem with the premise here. The premise is the f(labor, capital, tech) = total output. I think this has baked in assumptions that don't necessarily apply to digital versions of human beings. That is, this implies a needs based economic system. If the demand-side goes to zero, there is no need for this function to hold. The concept of living in a digital world where the laws of physics need not apply, and you have effectively no accesses to the server system running tho world you live in, there is no reason to engage in meaningful labor. If I can build myself a house, minecraft style, in minutes, what concern do I have to solving the problems of developing more efficient versions of housing.
Now, we could duplicate people with needs built in, that is, to create coercion there none is needed, but this would seem to have horrific ethical outcomes, tantamount to slavery. The very nature of living inside a curated programmable world without needs or concerns would likely lead to very little economic productivity that would be applicable to the imperfect world of constraints. It's as though we would create a world with some horrible disease, in order to get it's inhabitants to work harder.
Great piece, but one quibble — the examples in the productivity impacts section seem a little odd, because in some (all?) of these cases, the reason the person is so in-demand has to do with there being only one of them. And so duplicating them doesn't solve this problem:
- These people end up overbooked, with far more demands on their time than they can fulfill. Armies of other people end up devoted to saving their time and working around their schedules.
For example, while duplicating Sundar Pichai might make Google more successful (I don't know a lot about him, but presumably he was a star employee and would be very effective in many roles), the reason he's so in-demand is that he's the CEO of Google. I don't see how the existence of Clone-of-Sundar #235, who's assigned to be some middle-manager, is going to relieve the pressure of people trying to get an audience with Sundar-the-Original, who's the CEO (barring Parent Trap style twin-switcheroo shenanigans).
Similarly for Obama or Beyonce (I'm not so sure about Doudna) — wouldn't meeting the former president or going to a Beyonce concert be less special if there were 1000 of them?
To me, the more obvious example of the type of person who'd be useful to copy would be some non-famous star individual contributor. Maybe someone like Steve Davis at SpaceX.
One benefit to meeting with the clone is you will get any advice or information that is the same as the original. In fact assuming truly identical duplicates a clone can be delegated the same credentials as the original. No reason not to, especially since the real duplicator technology is going to be perfect.
For an example today: you send a message to the Netflix account page wanting to update your credit card, using a web browser. Your computer is connecting to a "clone" of the server instance that does these updates. The cloned server has all the same privileges and can send an update to the database if the request checks out.
Similarly a clone of Sundar Pichai can write a check to buy your company equally with the original and Google will treat the check the same as if the original wrote it.
Similarly a clone of Sundar Pichai can write a check to buy your company equally with the original and Google will treat the check the same as if the original wrote it.
Sticking with the hypothetical where what we have is a Calvin-and-Hobbes-style duplicator, I don't think this would work.
You can't run a company with 100 different CEOs, even if at one point those people all had exactly the same memories. Sure, at the time of duplication, any one of the copies could be made the CEO. But from that point on their memories and the information they have access to will diverge. And you don't want Sundar #42 randomly overruling a decision Sundar #35 made because he didn't know about it.
So no, I don't think they could all be given CEO-level decision making power (unless you also stipulate some super-coordination technology besides just the C&H-style duplicator).
Ok fair enough. I just cannot think of a physical realization of this duplication technology that wouldn't also give you the ability to sync copies and/or freeze policy updates to a copy.
What "freezing policy updates" means is that the neural network is unable to learn, though there would be storage of local context data that gets saved to a database and flushed once the individual switches tasks.
Doing it this way means that all clones of Sundar Pichai remain immutable and semi-deterministic, such that you can treat a decision made by any one of them the same as any other. (like it is in the computer science equivalent).
But yes if you posit the 'exactly like calvin & hobbs', even though there is no plausible technology that would be able to do this yet not allow you to do other manipulations, since in order to clone someone's mind you must be able to read and write values stored in it, therefore you are able to do all of the above.
The total economy would explode, but what about "economy per capita"?
If you are a highly exceptional employee and you make dozen copies of yourself, your company will benefit a lot, but now each individual copy of you is no longer exceptional... which makes it more difficult for each of the copies to negotiate for its salary. Unless the copies effectively "unionize" and refuse to compete against each other. I wonder what precautions future companies might take against that. Maybe coordinating with your copies will be considered a crime.
It wouldn't really change the overall outcome. What matters the most is that the total number of talented people grows exponentially, not just specific individual people.
Sure. I was wondering whether the talented people would starve in the global growing economy. Everyone else probably would, given that the idea (at least as shown by the pictures) is to reduce the abundance of food compared to population.
Footnotes Container
This comment is a container for our temporary "footnotes-as-comments" implementation that gives us hover-over-footnotes.
10. We'll start with this economy:

100 people produce 100 units of resources (1 per person). For every 10 units of resources, they're able to create 1 more duplicate (this is just capturing the idea that duplicates are "costly" to create). And the 100 people have 5 new ideas, leading to 5% productivity growth.
Here's year 2:

Now each person produces 1.05 widgets instead of 1, thanks to the productivity growth. And there's another 5% productivity growth.
This dynamic takes some time to "take off," but take off it does:
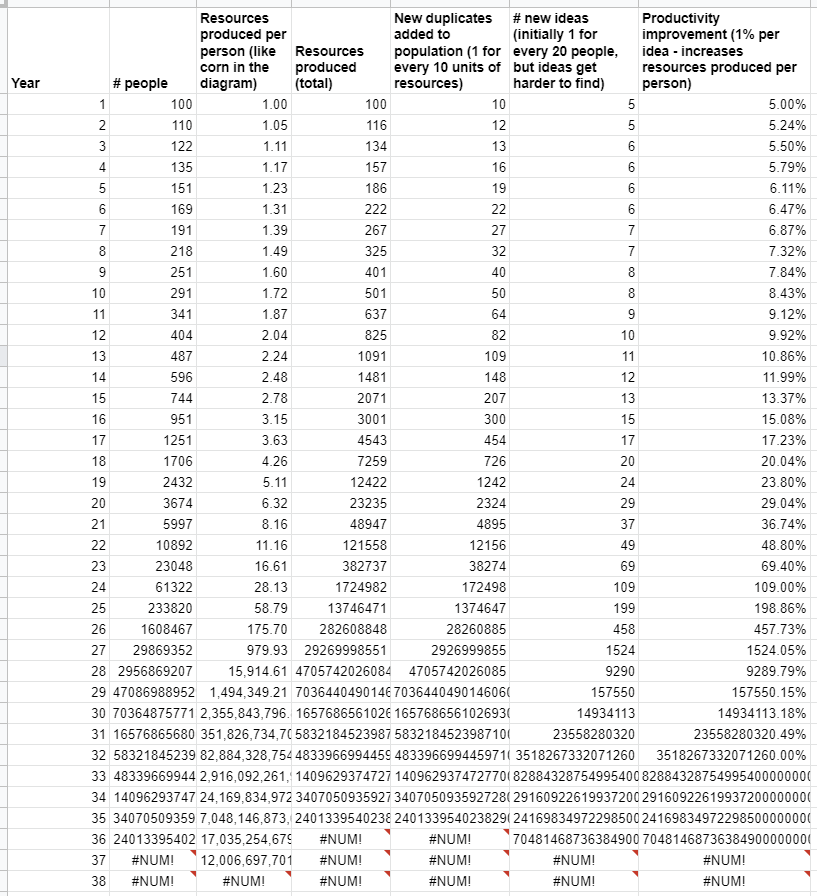
The #NUM!'s at the bottom signify Google Sheets choking on the large numbers.
My spreadsheet includes a version with simply exponentially increasing population; that one goes on for ~1000 years without challenging Google Sheets. So the population dynamic is key here.
1. For example, Star Trek's Captain Kirk first takes over the Enterprise in the mid-2200s. I think we could easily see a much more advanced, changed world than that of Star Trek, before 2100.
7. A faster-growing population doesn't necessarily mean faster technological advancement. There could be "diminishing returns": the first few ideas are easier to find than the next few, so even as the effort put into finding new ideas goes up, new ideas are found more slowly. (Are Ideas Getting Harder To Find? is a well-known paper on this topic.) More population = faster technological progress if the population is growing faster than the difficulty of finding new ideas is growing. This dynamic is portrayed in a simplified way in the graphic: initially people have ideas leading to doubling of corn output, but later the ideas only lead to a 1.5x'ing of corn output.
8. It's crucial to include the "more output -> more people" step, which is often not there by default, and doesn't describe today's world (but could describe a world with The Duplicator). It's standard for growth models to incorporate the other parts of the feedback loop: more people --> more ideas --> more output.
11. As noted above, there is an open debate on whether past economic growth actually follows the pattern described in Modeling the Human Trajectory. I discuss how the debate could change my conclusions here; I think there is a case either way for explosive growth this century.
13. Or of some sort of entity that's properly described as a "descendant" of people, as I'll discuss in the piece on digital people.
Kiln People is a fantastic science fiction story which explores the same question, if the embodied copies are temporary (~24 hours). It explores questions of employment, privacy, life-purpose, and legality in a world where this cloning procedure is common. I highly recommend it to those interested.
The way you describe the consequences of the invention of the Duplicator completely ignores ordinary human qualities. First of all, human ambitions. If you copy a brilliant CEO to replace all middle managers with him, then none of these copies will want to be a middle manager. Or you will have to change their brains so that they are happy with their subordinate position (which is doubtful from the moral side... like this idea in general). If you copy the brilliant president who ruled the country, then the copy discovers that her personal ambitions are not satisfied - he is no longer ruling the country. Similarly with all other options.
Written with the help of an online translator, there may be errors.
Audio also available by searching Stitcher, Spotify, Google Podcasts, etc. for "Cold Takes Audio"
This is the second post in a series explaining my view that we could be in the most important century of all time. Here's the roadmap for this series.
I explore the simple question of how the world would change if people could be "copied." I argue that this could lead to unprecedented economic growth and productivity. Later, I will describe how digital people or advanced AI could similarly cause a growth/productivity explosion.
When some people imagine the future, they picture the kind of thing you see in sci-fi films. But these sci-fi futures seem very tame, compared to the future I expect.
In sci-fi, the future is different mostly via:
But fundamentally, there are the same kinds of people we see today, with the same kinds of personalities, goals, relationships and concerns.
The future I picture is enormously bigger, faster, weirder, and either much much better or much much worse compared to today. It's also potentially a lot sooner than sci-fi futures:1 I think particular, achievable-seeming technologies could get us there quickly.
Such technologies could include "digital people" or particular forms of advanced AI - each of which I'll discuss in a future piece.
For now, I want to focus on just one aspect of what these sorts of technology would allow: the ability to make instant copies of people (or of entities with similar capabilities). Economic theory - and history - suggest that this ability, alone, could lead to unprecedented (in history or in sci-fi movies) levels of economic growth and productivity. This is via a self-reinforcing feedback loop in which innovation leads to more productivity, which leads to more "copies" of people, who in turn create more innovation and further increase productivity, which in turn ...
In this post, instead of directly discussing digital people or advanced AI, I'm going to keep things relatively simple and discuss a different hypothetical technology: the Duplicator from Calvin & Hobbes, which simply copies people.
How the Duplicator works
The Duplicator is portrayed in this series of comics. Its key feature is making an instant copy of a person: Calvin walks in, and two identical Calvins walk out.
This is importantly different from the usual (and more realistic) version of "cloning," in which a person's clone has the same DNA but has to start off as a baby and take years to become an adult.2
To flesh this out a bit, I'll assume that:
Productivity impacts
It seems that much of today's economy revolves around trying to make the most of "scarce human capital." That is:
The Duplicator would remove these bottlenecks. For example:
(The ability to make copies for temporary purposes - and run them at different speeds - could further increase efficiency, as I'll discuss in a future piece about digital people.)
Explosive growth
OK, the Duplicator would make the economy more productive - but how much more productive?
To answer, I'm going to briefly summarize what one might call the "Population growth is the bottleneck to explosive economic growth" viewpoint.
I would highly recommend reading more about this viewpoint at the following links, all of which I think are fascinating:
Here's my rough summary.
In standard economic models, the total size of the economy (its total output, i.e., how much "stuff" it creates) is a function of:
That is, the economy gets bigger when (a) there is more labor available, or (b) more capital (~everything other than labor) available, or when (c) productivity ("output per unit of labor/capital") increases.
The total population (number of people) affects both labor and productivity, because people can have ideas that increase productivity.
One way things could theoretically play out in an economy would be:
The economy starts with some set of resources (capital) supporting some set of people (population).
This set of people comes up with new ideas and innovations.
This leads to some amount of increased productivity, meaning there is more total economic output.6
This means people can afford to have more children. They do, and the population grows more quickly.
Because of that population growth, the economy comes up with new ideas and innovations faster than before (since more people means more new ideas).7
This leads to even more economic output and even faster population growth, in a self-reinforcing loop: more ideas → more output → more people → more ideas→ ....
When you incorporate this full feedback loop into economic growth models,8 they predict that (under plausible assumptions) the world economy will see accelerating growth.9 "Accelerating growth" is a fairly "explosive" dynamic in which the economy can go from small to extremely large with disorienting speed.
The pattern of growth predicted by these models seems like a reasonably good fit with the data on the world economy over the last 5,000 years (see Modeling the Human Trajectory, though there is an open debate on this point; I discuss how the debate could change my conclusions here). However, over the last few hundred years, growth has not accelerated; it has been "constant" (a less explosive dynamic) at around today's level.
Why did accelerating growth transition to constant growth?
This change coincided with the demographic transition. In the demographic transition it stopped being the case that having more output -> having more children. Instead, more output just meant richer people, and people actually had fewer children as they became richer. This broke the self-reinforcing loop described above.
Raising children is a massive investment (of time and personal energy, not just "capital"), and children take a long time to mature. By changing what it takes to grow the population, the Duplicator could restore the accelerating feedback loop.
morericher people→ more ideas→This figure from Could Advanced AI Drive Explosive Economic Growth? illustrates how the next decades might look different with steady exponential growth vs. accelerating growth:
To see more detailed (but simplified) example numbers demonstrating the explosive growth, see footnote.10
If we wanted to guess what a Duplicator might do in real life, we might imagine that it would get back to the kind of acceleration the world economy had historically, which loosely implies (based on Modeling the Human Trajectory) that the economy would reach infinite size sometime in the next century.11
Of course, that can't happen - at some point the size of the economy would be limited by fundamental natural resources, such as the number of atoms or amount of energy available in the galaxy. But in between here and running out of space/atoms/energy/something, we could easily see levels of economic growth that are massively faster than anything in history.
Over the last 100 years or so, the economy has doubled in size every few decades. With a Duplicator, it could double in size every year or month, on its way to hitting the limits.
Depending on how things played out, such productivity could result in an end to scarcity and material need, or in a dystopian race between different people making as many copies of themselves as possible in the hopes of taking over the population. (Or many in-between and other scenarios.)
Conclusion
I think the Duplicator would be a more powerful technology than warp drives, tricorders, laser guns12 or even teleporters. Minds are the source of innovation that can lead to all of those other things. So being cheaply able to duplicate them would be an extraordinary situation.
A harder-to-intuit, but even more powerful, technology would be digital people, e.g., the ability to run detailed simulations of people13 on a computer. Such simulated people could be copied Duplicator-style, and could also be sped up, slowed down, and reset, with virtual environments that were fully controlled.
I think that sort of technology is probably possible, and I expect a world with it to be even wilder than a world with the Duplicator. I'll elaborate on this in the next piece.
Use this feedback form if you have comments/suggestions you want me to see, or if you're up for giving some quick feedback about this post (which I greatly appreciate!)