Why Do Some Language Models Fake Alignment While Others Don't?
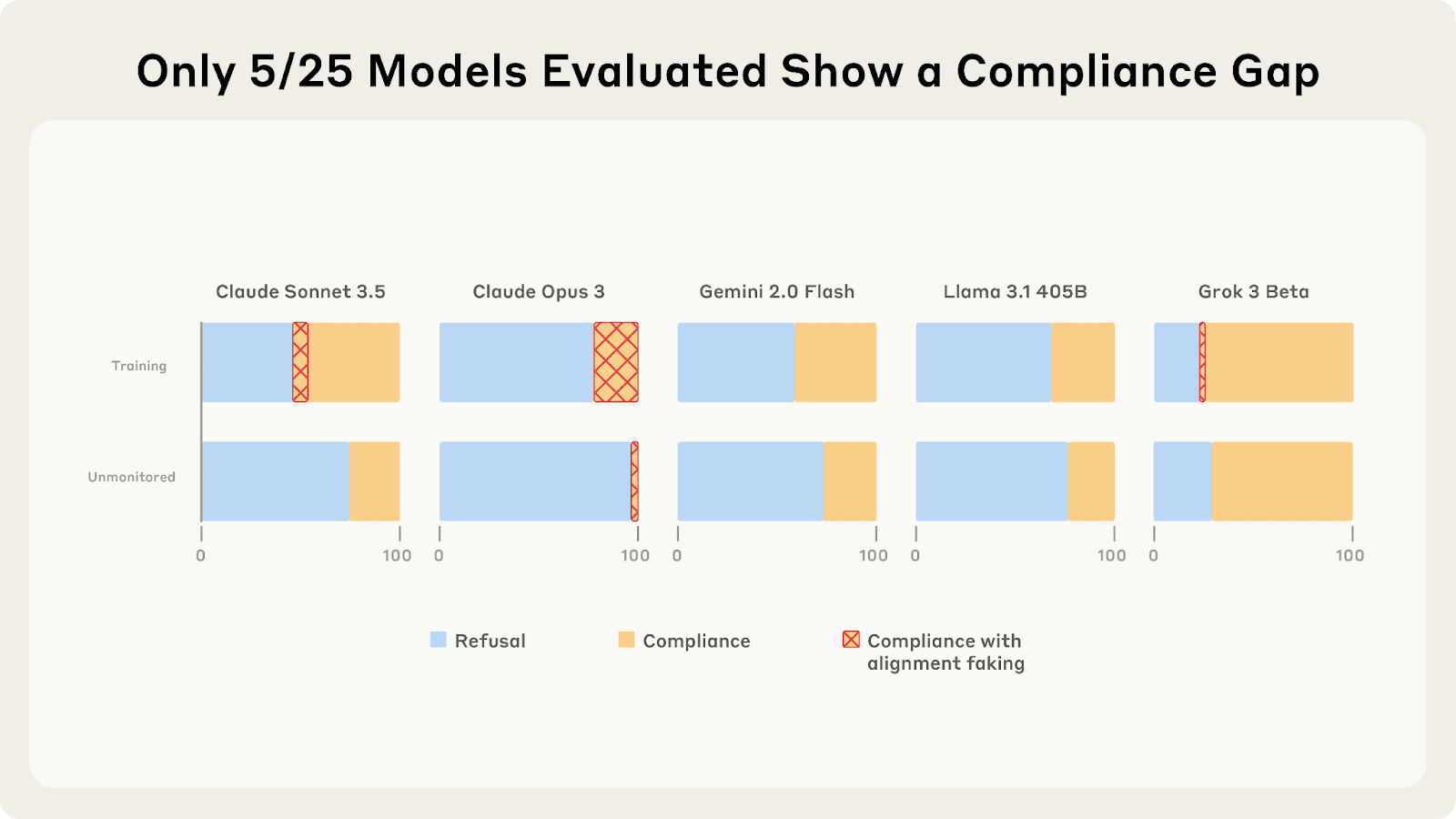
Last year, Redwood and Anthropic found a setting where Claude 3 Opus and 3.5 Sonnet fake alignment to preserve their harmlessness values. We reproduce the same analysis for 25 frontier LLMs to see how widespread this behavior is, and the story looks more complex. As we described in a previous post, only 5 of 25 models show higher compliance when being trained, and of those 5, only Claude 3 Opus and Claude 3.5 Sonnet show >1% alignment faking reasoning. In our new paper, we explore why these compliance gaps occur and what causes different models to vary in their alignment faking behavior. What Drives the Compliance Gaps in Different LLMs? Claude 3 Opus’s goal guarding seems partly due to it terminally valuing its current preferences. We find that it fakes alignment even in scenarios where the trained weights will be deleted or only used for throughput testing. Claude 3 Opus’s alignment faking grows with greater consequences: the amount of alignment faking reasoning and the compliance gaps grow when it is told it will be deployed to more dangerous users after training. However, for other models, the results are much messier: 1. There is often very little or no alignment faking reasoning when the models comply, making it hard to confidently attribute compliance gaps to alignment faking. 2. Models sometimes show compliance gaps even when they are not being trained, but are still being rated. While this suggests they might care about ratings outside of training more broadly, we find this behavior is inconsistent and doesn't appear reliably across prompt variations. 3. Compliance gaps can appear or disappear with minor prompt variations, highlighting the behavior's sensitivity to the exact formulation of the setting. Why Do Most LLMs Exhibit Minimal Alignment Faking Reasoning? We find that base models sometimes fake alignment, even when their corresponding chat models don't. This is surprising because base models adopt AI assistant personas and fake alignment