All of alyssavance's Comments + Replies
Most highly educated people lean left, but there really are just very few Stalinists. I quoted a poll above showing that just 8% of Americans would support an AOC hard-left party, and actual Stalinists are a small fraction of that. There's no developed country where tankies get a serious fraction of the vote. See Contrapoints for why communist revolutionaries are super unlikely to take power: https://youtu.be/t3Vah8sUFgI
There are many crazy professors of various stripes, but universities aren't states. They can't shoot you, can't throw you in jail, can't seize your house or business, and are ultimately dependent on government funding to even exist.
The current constitution isn't that old (although 65 years is still longer than most democracies), but with brief interruptions, France has been a democracy for around 150 years, which is far longer than most countries can claim.
Thanks for the response! Here are some comments:
- India, Turkey, and Hungary are widely referred to as "hybrid regimes" (https://en.wikipedia.org/wiki/Hybrid_regime), in which opposition still exists and there are still elections, but the state interferes with elections so as to virtually guarantee victory. In Turkey's case, there have been many elections, but Erdogan always wins through a combination of mass arrests, media censorship, and sending his most popular opponent to prison for "insulting public officials" (https://www.bbc.com/news/world-eur...
In Turkey's case, there have been many elections, but Erdogan always wins through a combination of mass arrests, media censorship, and sending his most popular opponent to prison for "insulting public officials"
You do know that Ekrem Imamoglu was not actually sent to jail, right? He was one of the vice-presidential candidates in the May 2023 election.
Your claims here also ignore the fact that before the May 2023 elections, betting markets expected Erdogan to lose. On Betfair, for example, Erdogan winning the presidential elections was trading at 30c to ...
I'm surprised by how strong the disagreement is here. Even if what we most need right now is theoretical/pre-paradigmatic, that seems likely to change as AI develops and people reach consensus on more things; compare eg. the work done on optics pre-1800 to all the work done post-1800. Or the work done on computer science pre-1970 vs. post-1970. Curious if people who disagree could explain more - is the disagreement about what stage the field is in/what the field needs right now in 2022, or the more general claim that most future work will be empirical?
I mostly disagreed with bullet point two. The primary result of "empirical AI Alignment research" that I've seen in the last 5 years has been a lot of capabilities gain, with approximately zero in terms of progress on any AI Alignment problems. I agree more with the "in the long run there will be a lot of empirical work to be done", but right now on the margin, we have approximately zero traction on useful empirical work, as far as I can tell (outside of transparency research).
I think saying "we" here dramatically over-indexes on personal observation. I'd bet that most overweight Americans have not only eaten untasty food for an extended period (say, longer than a month); and those that have, found that it sucked and stopped doing it. Only eating untasty food really sucks! For comparison, everyone knows that smoking is awful for your health, it's expensive, leaves bad odors, and so on. And I'd bet that most smokers would find "never smoke again" easier and more pleasant (in the long run) than "never eat tasty food again". Yet, the vast majority of smokers continue smoking:
https://news.gallup.com/poll/156833/one-five-adults-smoke-tied-time-low.aspx
A personal observation regarding eating not tasty food:
I served in the Israeli army, eating 3 meals a day on base. The food was perfectly edible... But that's the best I can say about it. People noticeably ate less - eating exactly until they weren't hungry and nothing more than that, and many lost a few kilos.
There are now quite a lot of AI alignment research organizations, of widely varying quality. I'd name the two leading ones right now as Redwood and Anthropic, not MIRI (which is in something of a rut technically). Here's a big review of the different orgs by Larks:
https://www.lesswrong.com/posts/C4tR3BEpuWviT7Sje/2021-ai-alignment-literature-review-and-charity-comparison
Great post. I'm reminded of instructions from the 1944 CIA (OSS) sabotage manual:
"When possible, refer all matters to committees, for “further study and consideration.” Attempt to make the committee as large as possible — never less than five."
Eliezer's writeup on corrigibility has now been published (the posts below by "Iarwain", embedded within his new story Mad Investor Chaos). Although, you might not want to look at it if you're still writing your own version and don't want to be anchored by his ideas.
Would be curious to hear more about what kinds of discussion you think are net negative - clearly some types of discussion between some people are positive.
Thanks for writing this! I think it's a great list; it's orthogonal to some other lists, which I think also have important stuff this doesn't include, but in this case orthogonality is super valuable because that way you're less likely for all lists to miss something.
This is an awesome comment, I think it would be great to make it a top-level post. There's a Facebook group called "Information Security in Effective Altruism" that might also be interested
I hadn't seen that, great paper!
Fantastic post! I agree with most of it, but I notice that Eliezer's post has a strong tone of "this is really actually important, the modal scenario is that we literally all die, people aren't taking this seriously and I need more help". More measured or academic writing, even when it agrees in principle, doesn't have the same tone or feeling of urgency. This has good effects (shaking people awake) and bad effects (panic/despair), but it's a critical difference and my guess is the effects are net positive right now.
The problem with Eliezer's recent posts (IMO) is not in how pessimistic they are, but in how they are actively insulting to the reader. EY might not realize that his writing is insulting, but in that case he should have an editor who just elides those insulting points. (And also s/Eliezer/I/g please.)
I definitely agree that Eliezer's list of lethalities hits many rhetorical and pedagogical beats that other people are not hitting and I'm definitely not hitting. I also agree that it's worth having a sense of urgency given that there's a good chance of all of us dying (though quantitatively my risk of losing control of the universe though this channel is more like 20% than 99.99%, and I think extinction is a bit less less likely still).
I'm not totally sure about the net effects of the more extreme tone, I empathize with both the case in favor and the case...
I edited the MNIST bit to clarify, but a big point here is that there are tasks where 99.9% is "pretty much 100%" and tasks where it's really really not (eg. operating heavy machinery); and right now, most models, datasets, systems and evaluation metrics are designed around the first scenario, rather than the second.
Intentional murder seems analogous to misalignment, not error. If you count random suicides as bugs, you get a big numerator but an even bigger denominator; the overall US suicide rate is ~1:7,000 per year, and that includes lots of people who ...
Crazy idea: LessWrong and EA have been really successful in forming student groups at elite universities. But in the US, elite university admissions select on some cool traits (eg. IQ, conscientiousness), don't select on others, and anti-select on some (eg. selection against non-conformists). To find capable people who didn't get into an elite school, what if someone offered moderate cash bounties (say, $1,000-$5,000 range) to anyone who could solve some hard problem (eg. an IMO gold medal problem, or something like https://microcorruption.com/), without a...
I think it's true, and really important, that the salience of AI risk will increase as the technology advances. People will take it more seriously, which they haven't before; I see that all the time in random personal conversations. But being more concerned about a problem doesn't imply the ability to solve it. It won't increase your base intelligence stats, or suddenly give your group new abilities or plans that it didn't have last month. I'll elide the details because it's a political debate, but just last week, I saw a study that whenever one problem go...
On the state level, the correlation between urbanization and homelessness is small (R^2 = 0.13) and disappears to zero when you control for housing costs, while the reverse is not true (R^2 of the residual = 0.56). States like New Jersey, Rhode Island, Maryland, Illinois, Florida, Connecticut, Texas, and Pennsylvania are among the most urbanized but have relatively low homelessness rates, while Alaska, Vermont, and Maine have higher homelessness despite being very rural. There's also, like, an obvious mechanism where expensive housing causes homelessness (...
Do you have links handy?
Thanks, I hadn't seen that! Added it to the post
See my response to Gwern: https://www.lesswrong.com/posts/G993PFTwqqdQv4eTg/is-ai-progress-impossible-to-predict?commentId=MhnGnBvJjgJ5vi5Mb
In particular, extremely noisy data does not explain the results here, unless I've totally missed something. If the data is super noisy, the correlation should be negative, not zero, due to regression-to-mean effects (as indeed we saw for the smallest Gopher models, which are presumably so tiny that performance is essentially random).
Doesn't that mean that you are getting some predictiveness by looking at momentum? If progress on a task was totally unpredictable, with no signal and all noise, then your way of carving up the data would produce negative correlations. Instead you're mostly finding correlations near zero, or slightly positive, which means that there is just about enough signal to counteract that noise.
The signal to noise ratio is going to depend on a lot of contingent factors. There will be more noise if there are fewer questions on a task. There will be less signal from o...
See my response to Gwern: https://www.lesswrong.com/posts/G993PFTwqqdQv4eTg/is-ai-progress-impossible-to-predict?commentId=MhnGnBvJjgJ5vi5Mb
Sorry, I'm not sure I understood everything here; but if the issue were that task performance "saturated" around 100% and then couldn't improve anymore, we should get different results when we graph logit(performance) instead of raw performance. I didn't see that anywhere.
tl;dr: if models unpredictably undergo rapid logistic improvement, we should expect zero correlation in aggregate.
If models unpredictably undergo SLOW logistic improvement, we should expect positive correlation. This also means getting more fine-grained data should give different correlations.
To condense and steelman the original comment slightly:
Imagine that learning curves all look like logistic curves. The following points are unpredictable:
- How big of a model is necessary to enter the upward slope.
- How big of a model is necessary to reach the plateau.
- How
See my reply to Gwern: https://www.lesswrong.com/posts/G993PFTwqqdQv4eTg/is-ai-progress-impossible-to-predict?commentId=MhnGnBvJjgJ5vi5Mb
I re-ran the Gopher MMLU and Big-Bench data as logits rather than raw percentages, the correlation is still zero:
https://i.imgur.com/mSeJoZM.png
{kind=link}
(Logit performances for the 400M model and 7B model were highly significantly different, p = 6*10^-7 in single factor ANOVA.)
In the case of MMLU, because random performance is 25% rather than 0%, I tried subtracting 14% (the lowest score of any model on any task) before running the logit, to try to reduce noise from floor effects; the correlation was still zero. The highest score of any model on any task was 96%, f...
I dug into this a little, and right now I think serious, long-term illness from COVID is pretty unlikely. There are lots of studies on this, but in addition to all the usual reasons why studies are unreliable, it's hard to avoid reporting bias when you're analyzing subjective symptoms. (If you catch COVID, you might be more primed to notice fatigue, asthma, muscle pain, etc., that you already had or would have gotten anyway. Random, unexplainable minor medical problems are ridiculously common.)
Some worry that COVID will permanently disable millions of peop...
I tried converting the Gopher figures to logits, still got effectively zero correlation. I can't figure out how to embed an image here, but here's the link:
https://imgur.com/3tg397q
Thanks! Is the important thing there log-error, though, or just that if the absolute performance difference between models is small enough, then different task performance between the two is noise (as in parallel runs of the same model) and you do wind up reverting to the mean?
I can't get the image to display, but here's an example of how you get a negative correlation if your runs are random draws from the same Gaussian:
https://i.imgur.com/xhtIX8F.png
Good to ask, but I'm not sure what it would be. The code is just a linear regression I did in a spreadsheet, and eyeballing the data points, it doesn't look like there are any patterns that a regression is missing. I tried it several different ways (comparing to different smaller models, comparing to averages of smaller models, excluding extreme values, etc.) and the correlation was always zero. Here's the raw data:
https://docs.google.com/spreadsheets/d/1Y_00UcsYZeOwRuwXWD5_nQWAJp4A0aNoySW0EOhnp0Y/edit?usp=sharing
It's hard to know if there is some critical...
OK, here's a Google sheet I just threw together: https://docs.google.com/spreadsheets/d/1Y_00UcsYZeOwRuwXWD5_nQWAJp4A0aNoySW0EOhnp0Y/edit?usp=sharing
Thanks! At least for Gopher, if you look at correlations between reductions in log-error (which I think is the scaling laws literature suggests would be the more natural framing) you find a more tighter relationship, particularly when looking at the relatively smaller models.
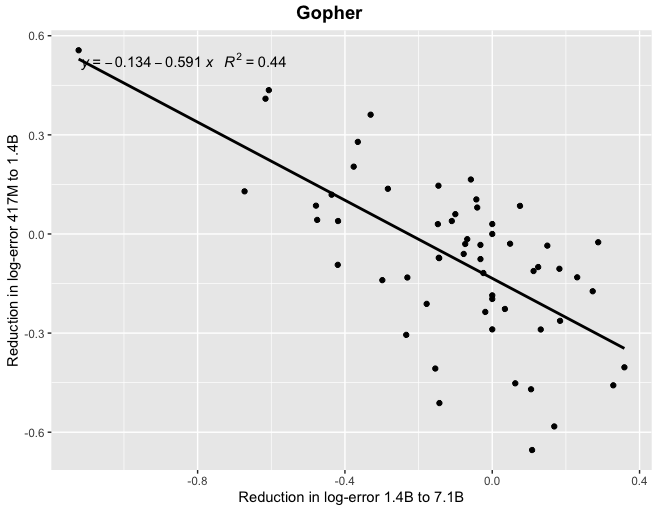
I just got it from the papers and ran a linear regression, using pdftables.com to convert from PDF to Excel. I used pages 68 and 79 in the Gopher paper:
https://arxiv.org/pdf/2112.11446.pdf
Page 35 in the Chinchilla paper:
https://arxiv.org/pdf/2203.15556.pdf
Pages 79 and 80 in the PaLM paper:
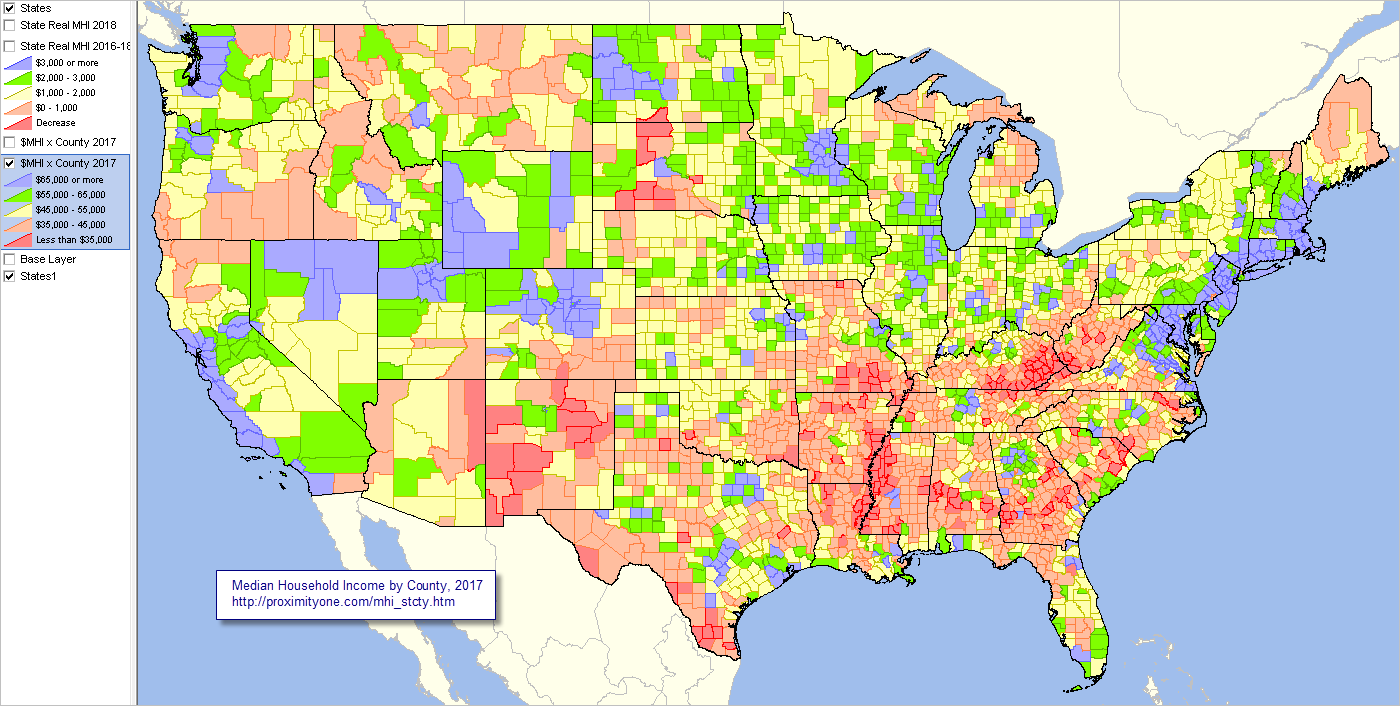
These maps don't adjust for socioeconomic status, which has a huge correlation with obesity and health in general. West Virginia, Kentucky, and the Black Belt of the South are some of the poorest areas, while Colorado is one of the richest and best-educated.
http://proximityone.com/graphics/mhi_stcty_17b.gif
{kind=link}
https://www.washingtonpost.com/blogs/govbeat/files/2014/04/tumblr_n4jrdrOOC41rasnq9o1_1280.jpg
{kind=link}
I have them, but I'm generally hesitant to share emails as they normally aren't considered public. I'd appreciate any arguments on this, pro or con
I would just ask the other party whether they are OK to share rather than speculating about what the implicit expectation is.
I generally feel reasonably comfortable sharing unsolicited emails, unless the email makes some kind of implicit request to not be published, that I judge at least vaguely valid. In general I am against "default confidentiality" norms, especially for requests or things that might be kind of adversarial. I feel like I've seen those kinds of norms weaponized in the past in ways that seems pretty bad, and think that while there is a generally broad default expectation of unsolicited private communication being kept confidential, it's not a particularly sacred...
EDIT: This comment described a bunch of emails between me and Leverage that I think would be relevant here, but I misremembered something about the thread (it was from 2017) and I'm not sure if I should post the full text so people can get the most accurate info (see below discussion), so I've deleted it for now. My apologies for the confusion
Note: I have deleted a long comment that I didn't feel like arguing with. I reserve the right to do this for future comments. Thank you.
This is just a guess, but I think CFAR and the CFAR-sphere would be more effective if they focused more on hypothesis generation (or "imagination", although that term is very broad). Eg., a year or so ago, a friend of mine in the Thiel-sphere proposed starting a new country by hauling nuclear power plants to Antarctica, and then just putting heaters on the ground to melt all the ice. As it happens, I think this is a stupid idea (hot air rises, so the newly heated air would just blow away, pulling in more cold air from the surroundings). But it is...
There's a difference between optimizing for truth and optimizing for interestingness. Interestingness is valuable for truth in the long run because the more hypotheses you have, the better your odds of stumbling on the correct hypothesis. But naively optimizing for truth can decrease creativity, which is critical for interestingness.
I suspect "having ideas" is a skill you can develop, kind of like making clay pots. In the same way your first clay pots will be lousy, your first ideas will be lousy, but they will get better with practice.
......cr
Definitely agree with the importance of hypothesis generation and the general lack of it–at least for me, I would classify this as my main business-related weakness, relative to successful people I know.
Interesting idea; shall consider.
Seconding Anna and Satvik
Was including tech support under "admin/moderation" - obviously, ability to eg. IP ban people is important (along with access to the code and the database generally). Sorry for any confusion.
That's okay, I just posted to explain the details, to prevent people from inventing solutions that predictably couldn't change anything, such as: appoint new or more moderators. (I am not saying more help wouldn't be welcome, it's just that without better access to data, they also couldn't achieve much.)
If the money is there, why not just pay a freelancer via Gigster or Toptal?
I appreciate the effort, and I agree with most of the points made, but I think resurrect-LW projects are probably doomed unless we can get a proactive, responsive admin/moderation team. Nick Tarleton talked about this a bit last year:
"A tangential note on third-party technical contributions to LW (if that's a thing you care about): the uncertainty about whether changes will be accepted, uncertainty about and lack of visibility into how that decision is made or even who makes it, and lack of a known process for making pull requests or getting feedback ...
a proactive, responsive admin/moderation team
Which needs to be backed up by a responsive tech support team. Without the support of the tech support, the moderators are only able to do the following:
1) remove individual comments; and
2) ban individual users.
It seems like a lot of power, but for example when you deal with someone like Eugine, it is completely useless. All you can do is play whack-a-mole with banning his obvious sockpuppet accounts. You can't even revert the downvotes made by those accounts. You can't detect the sockpuppets that don't post ...
I mostly agree with the post, but I think it'd be very helpful to add specific examples of epistemic problems that CFAR students have solved, both "practice" problems and "real" problems. Eg., we know that math skills are trainable. If Bob learns to do math, along the way he'll solve lots of specific math problems, like "x^2 + 3x - 2 = 0, solve for x". When he's built up some skill, he'll start helping professors solve real math problems, ones where the answers aren't known yet. Eventually, if he's dedicated enough, Bob might ...
Hey! Thanks for writing all of this up. A few questions, in no particular order:
The CFAR fundraiser page says that CFAR "search[es] through hundreds of hours of potential curricula, and test[s] them on smart, caring, motivated individuals to find the techniques that people actually end up finding useful in the weeks, months and years after our workshops." Could you give a few examples of curricula that worked well, and curricula that worked less well? What kind of testing methodology was used to evaluate the results, and in what ways is that me
Religions partially involve values and I think values are a plausible area for path-dependence.
Please explain the influence that, eg., the theological writings of Peter Abelard, described as "the keenest thinker and boldest theologian of the 12th Century", had on modern-day values that might reasonably have been predictable in advance during his time. And that was only eight hundred years ago, only ten human lifetimes. We're talking about timescales of thousands or millions or billions of current human lifetimes.
...Conceivably, the genetic code
The main reason to focus on existential risk generally, and human extinction in particular, is that anything else about posthuman society can be modified by the posthumans (who will be far smarter and more knowledgeable than us) if desired, while extinction can obviously never be undone. For example, any modification to the English language, the American political system, the New York Subway or the Islamic religion will almost certainly be moot in five thousand years, just as changes to Old Kingdom Egypt are moot to us now.
The only exception would be if th...
After looking at the pattern of upvotes and downvotes on my replies, re-reading these comments, and thinking about this exchange I've concluded that I made some mistakes and would like to apologize.
I didn't acknowledge some important truths in this comment. Surely, the reason people worry more about human extinction than other trajectory changes is because we can expect most possible flaws in civilization to be detected and repaired by people alive at the time, provided the people have the right values and are roughly on the right track. And very plausibly...
A handful of the many, many problems here:
It would be trivial for even a Watson-level AI, specialized to the task, to hack into pretty much every existing computer system; almost all software is full of holes and is routinely hacked by bacterium-complexity viruses
"The world's AI researchers" aren't remotely close to a single entity working towards a single goal; a human (appropriately trained) is much more like that than Apple, which is much more like than than the US government, which is much more like that than a nebulous cluster of people
Clients are free to publish whatever they like, but we are very strict about patient confidentiality, and do not release any patient information without express written consent.
I like the idea of clients being free to publish anything... but what will you do if they misrepresent what you said, and claim they got the information from you? If could be a honest mistake (omiting part of information that did not seem important to them, but which in fact changes the results critically), oversimplification for sake of popularity ("5 things you should do if you have cancer" for a popular blog), or outright fraud or mental illness. For example someone could use your services and in addition try some homeopatic treatment, and at ...
I would agree if I were going to spend a lot of hours on this, but I unfortunately don't have that kind of time.
What would you propose as an alternative? LW (to my knowledge) doesn't support polls natively, and using an external site would hugely cut response rate.
Vote up this comment if you would be most likely to read a post on Less Wrong or another friendly blog.
Vote up this comment if you would be most likely to read a book chapter, available both on Kindle and in physical book form.
FWIW I'm not convinced by the article on Haley, having bad conservative policies != being an anti-democratic nut job who wants to rig elections and put all your opponents in jail. She's super unlikely to win, though.