All of anithite's Comments + Replies
TLDR:I got stuck on notation [a][b][c][...]→f(a,b,c,...). LLMs probably won't do much better on that for now. Translating into find an unknown f(*args) and the LLMs get it right with probability ~20% depending on the model. o3-mini-high does better. Sonnet 3.7 did get it one shot but I had it write code for doing substitutions which it messes up a lot.
Like others, I looked for some sort of binary operator or concatenation rule. Replacing "][" with "|" or "," would have made this trivial. Straight string substitutions don't work since "[[]]" can be either 2...
None of the labs would be doing undirected drift. That wouldn't yield improvement for exactly the reasons you suggest.
In the absence of a ground truth quality/correctness signal, optimizing for coherence works. This can give prettier answers (in the way that averaged faces are prettier) but this is limited. The inference time scaling equivalent would be a branching sampling approach that searches for especially preferred token sequences rather than the current greedy sampling approach. Optimising for idea level coherence can improve model thinking to some ...
O1 now passes the simpler "over yellow" test from the above. Still fails the picture book example though.
For a complex mechanical drawing, O1 was able to work out easier dimensions but anything more complicated tends to fail. Perhaps the full O3 will do better given ARC-AGI benchmark performance.
Meanwhile, Claude 3.5 and 4o fail a bit more badly failing to correctly identify axial and diameter dimensions.
Visuospatial performance is improving albeit slowly.
My hope is that the minimum viable pivotal act requires only near human AGI. For example, hack competitor training/inference clusters to fake an AI winter.
Aligning +2SD human equivalent AGI seems more tractable than straight up FOOMing to ASI safely.
One lab does it to buy time for actual safety work.
Unless things slow down massively we probably die. An international agreement would be better but seems unlikely.
This post raises a large number of engineering challenges. Some of those engineering challenges rely on other assumptions being made. For example, the use of energy carrying molecules rather than electricity or mechanical power which can cross vacuum boundaries easily. Overall a lot of "If we solve X via method Y (which is the only way to do it) problem Z occurs" without considering making several changes at once that synergistically avoid multiple problems.
"Too much energy" means too much to be competitive with normal biological processes.
That goalpos...
Your image links are all of the form: http://localhost:8000/out/planecrash/assets/Screenshot 2024-12-27 at 00.31.42.png
Whatever process is generating the markdown for this, well those links can't possibly work.
I got this one wrong too. Ignoring negative roots is pretty common for non-mathematicians.
I'm half convinced that most of the lesswrong commenters wouldn't pass as AGI if uploaded.
This post is important to setting a lower bound on AI capabilities required for an AI takeover or pivotal act. Biology as an existence proof that some kind of "goo" scenario is possible. It somewhat lowers the bar compared to Yudkowsky's dry nanotech scenario but still requires AI to practically build an entire scientific/engineering discipline from scratch. Many will find this implausible.
Digital tyranny is a better capabilities lower bound for a pivotal act or AI takeover strategy. It wasn't nominated though which is a shame.
This is why I disagree with a lot of people who imagine an “AI transformation” in the economic productivity sense happening instantaneously once the models are sufficiently advanced.
For AI to make really serious economic impact, after we’ve exploited the low-hanging fruit around public Internet data, it needs to start learning from business data and making substantial improvements in the productivity of large companies.
Definitely agree that private business data could advance capabilities if it were made available/accessible. Unsupervised Learning over all...
Alternate POV
Science fiction. < 10,000 words. A commissioned re-write of Eliezer Yudkowsky's That Alien Message https://alicorn.elcenia.com/stories/starwink.shtml
since it hasn't been linked so far and doesn't seem to be linked from the original
TLDR:autofac requires solving "make (almost) arbitrary metal parts" problem but that won't close the loop. Hard problem is building automated/robust re-implementation of some of the economy requiring engineering effort not trial and error. Bottleneck is that including for autofac. Need STEM AI (Engineering AI mostly). Once that happens, economy gets taken over and grows rapidly as things start to actually work.
To expand on that:
"make (almost) arbitrary metal parts"
- can generate a lot of economic value
- requires essentially giant github repo of:
- hardware
The key part of the Autofac, the part that kept it from being built before, is the AI that runs it.
That's what's doing the work here.
We can't automate machining because an AI that can control a robot arm to do typical machinist things (EG:changing cutting tool inserts, removing stringy steel-wool-like tangles of chips, etc.) doesn't exist or is not deployed.
If you have a robot arm + software solution that can do that it would massively drop operational costs which would lead to exponential growth.
The core problem is that currently we need the humans the...
If we consider each (include,exclude) decision for (1,2,3,4,5) as a separate question, error rates are 20%-ish. Much better than random guessing. So why does it make mistakes?
If bottlenecking on data is the problem, more data in the image should kill performance. So how about a grid of 3 digit numbers (random vals in range 100...999)?
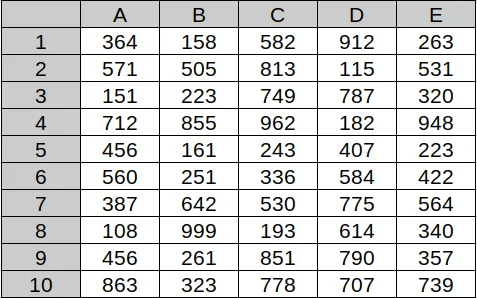
{kind=link}
3.5 sonnet does perfectly. Perfect score answering lookup(row/col) and (find_row_col(number), find duplicates and transcription to CSV.
So this isn't a bottleneck like human working memory. Maybe we need to use a higher resolut...
It's actually a lot worse than that.

Q:Which numbers are above a yellow region in the image?
GPT4o: [2,4]
GPT4: [4,5]
Claude 3.5 Sonnet: [2,5]
Claude sonnet describes the image as follows:
User: List the numbers in the above image, how are they placed in the image? What's below them?
...The numbers shown in the image are:
1, 2, 3, 4, 5
These numbers are placed in a single horizontal row, appearing to be in separate cells or boxes arranged from left to right in ascending numerical order. Each number occupies its own cell, creating a simple table-like structure wi
TLDR:Memory encryption alone is indeed not enough. Modifications and rollback must be prevented too.
- memory encryption and authentication has come a long way
- Unless there's a massive shift in ML architectures to doing lots of tiny reads/writes, overheads will be tiny. I'd guesstimate the following:
- negligible performance drop / chip area increase
- ~1% of DRAM and cache space[1]
It's hard to build hardware or datacenters that resists sabotage if you don't do this. You end up having to trust the maintenance people aren't messing with the equipment and the fa...
What you're describing above is how Bitlocker on Windows works on every modern Windows PC. The startup process involves a chain of trust with various bootloaders verifying the next thing to start and handing off keys until windows starts. Crucially, the keys are different if you start something that's not windows (IE:not signed by Microsoft). You can't just boot Linux and decrypt the drive since different keys would be generated for Linux during boot and they won't decrypt the drive.
Mobile devices and game consoles are even more locked down. If there's no ...
Hardware encryption likely means that dedicated on-chip hardware to handle keys and decrypting weights and activations on-the-fly.
The hardware/software divide here is likely a bit fuzzy but having dedicated hardware or a separate on-chip core makes it easier to isolate and accelerate the security critical operations. If security costs too much performance, people will be tempted to turn it off.
Encrypting data in motion and data at rest (in GPU memory) makes sense since this minimizes trust. An attacker with hardware access will have a hard time getting wei...
Vulnerable world hypothesis (but takeover risk rather than destruction risk). That + first mover advantage could stop things pretty decisively without requiring ASI alignment
As an example, taking over most networked computing devices seems feasible in principle with thousands of +2SD AI programmers/security-researchers. That requires an Alpha-go level breakthrough for RL as applied to LLM programmer-agents.
One especially low risk/complexity option is a stealthy takeover of other AI lab's compute then faking another AI winter. This might get you most of the...
Slower is better obviously but as to the inevitability of ASI, I think reaching top 99% human capabilities in a handful of domains is enough to stop the current race. Getting there is probably not too dangerous.
Current ATGMs poke a hole in armor with a very fast jet of metal (1-10km/s). Kinetic penetrators do something similar using a tank gun rather than specially shaped explosives.
"Poke hole through armor" is the approach used by almost every weapon. A small hole is the most efficient way to get to the squishy insides. Cutting a slot would take more energy. Blunt impact only works on flimsy squishy things. A solid shell of armor easily stopped thrown rocks in antiquity. Explosive over-pressure is similarly obsolete against armored targets.
TLDR:"poke hole then d...
EMP mostly affects power grid because power lines act like big antennas. Small digital devices are built to avoid internal RF like signals leaking out (thanks again FCC) so EMP doesn't leak in very well. DIY crud can be done badly enough to be vulnerable but basically run wires together in bundles out from the middle with no loops and there's no problems.
Only semi-vulnerable point is communications because radios are connected to antennas.
Best option for frying radios isn't EMP, but rather sending high power radio signal at whatever frequency antenna best ...
RF jamming, communication and other concerns
TLDR: Jamming is hard when comms system is designed to resist it. Civilian stuff isn't but military is and can be quite resistant. Frequency hopping makes jamming ineffective if you don't care about stealth. Phased array antennas are getting cheaper and make things stealthier by increasing directivity.(starlink terminal costs $1300 and has 40dbi gain). Very expensive comms systems on fighter jets using mm-wave comms and phased array antennas can do gigabit+ links in presence of jamming undetected.
civilian stuf
...Self driving cars have to be (almost)perfectly reliable and never have an at fault accident.
Meanwhile cluster munitions are being banned because submunitions can have 2-30% failure rates leaving unexploded ordinance everywhere.
In some cases avoiding civvy casualties may be a similar barrier since distinguishing civvy from enemy reliably is hard but militaries are pretty tolerant to collateral damage. Significant failure rates are tolerable as long as there's no exploitable weaknesses.
Distributed positioning systems
Time of flight distance determination is...
Overhead is negligible because military would use symmetric cryptography. Message authentication code can be N bits for 2^-n chance of forgery. 48-96 bits is likely sweet spot and barely doubles size for even tiny messages.
Elliptic curve crypto is there if for some reason key distribution is a terrible burden. typical ECC signatures are 64 bytes (512 bits) but 48 bytes is easy and 32 bytes possible with pairing based ECC. If signature size is an issue, use asymmetric crypto to negotiate a symmetric key then use symmetric crypto for further messages with tight timing limits.
Current landmines are very effective because targets are squishy/fragile:
- Antipersonnel:
- take off a foot
- spray shrapnel
- Antitank/vehicle:
- cut track /damage tires
- poke a hole with a shaped charge and spray metal into vehicle insides
Clearing an area for people is hard
-
drones can be much less squishy
- need more explosives to credibly threaten them
-
Eliminating mine threat requires
- clearing a path (no mines buried under transit corridor)
- mine clearing vehicle
- use line charge
- block sensors so off route mines can't target vehicles
- Inflatable ba
- clearing a path (no mines buried under transit corridor)
I think GPT-4 and friends are missing the cognitive machinery and grid representations to make this work. You're also making the task harder by giving them a less accessible interface.
My guess is they have pretty well developed what/where feature detectors for smaller numbers of objects but grids and visuospatial problems are not well handled.
The problem interface is also not accessible:
- There's a lot of extra detail to parse
- Grid is made up of gridlines and colored squares
- colored squares of fallen pieces serve no purpose but to confuse model
A more ...
Not so worried about country vs. country conflicts. Terrorism/asymmetric is bigger problem since cheap slaughterbots will proliferate. Hopefully intelligence agencies can deal with that more cheaply than putting in physical defenses and hard kill systems everywhere.
Still don't expect much impact before we get STEM AI and everything goes off the rails.
Also without actual fights how would one side know the relative strength of their drone system
Relative strength is hard to gauge but getting reasonable perf/$ is likely easy. Then just compare budgets adju...
Disclaimer:Short AI timelines imply we won't see this stuff much before AI makes things weird
This is all well and good in theory but mostly bottlenecked on software/implementation/manufacturing.
- with the right software/hardware current military is obsolete
- but no one has that hardware/software yet
EG:no one makes an airborne sharpshooter drone(edit:cross that one off the list)- Black sea is not currently full of Ukrainian anti-ship drones + comms relays
- no drone swarms/networking/autonomy yet
- I expect current militaries to successfully adapt before/as n
As long as you can reasonably represent “do not kill everyone”, you can make this a goal of the AI, and then it will literally care about not killing everyone, it won’t just care about hacking its reward system so that it will not perceive everyone being dead.
That's not a simple problem.First you have to specify "not killing everyone" robustly (outer alignment) and then you have to train the AI to have this goal and not an approximation of it (inner alignment).
caring about reality
Most humans say they don't want to wirehead. If we cared only about our ...
This super-moralist-AI-dominated world may look like a darker version of the Culture, where if superintelligent systems determine you or other intelligent systems within their purview are not intrinsically moral enough they contrive a clever way to have you eliminate yourself, and monitor/intervene if you are too non-moral in the meantime.
My guess is you get one of two extremes:
- build a bubble of human survivable space protected/managed by an aligned AGI
- die
with no middle ground. The bubble would be self contained. There's nothing you can do from ins...
Agreed, recklessness is also bad. If we build an agent that prefers we keep existing we should also make sure it pursues that goal effectively and doesn't accidentally kill us.
My reasoning is that we won't be able to coexist with something smarter than us that doesn't value us being alive if wants our energy/atoms.
- barring new physics that lets it do it's thing elsewhere, "wants our energy/atoms" seems pretty instrumentally convergent
"don't built it" doesn't seem plausible so:
- we should not build things that kill us.
- This probably means:
- wants us to k
This is definitely subjective. Animals are certainly worse off in most respects and I disagree with using them as a baseline.
Imitation is not coordination, it's just efficient learning and animals do it. They also have simple coordination in the sense of generalized tit for tat (we call it friendship). You scratch my back I scratch yours.
Cooperation technologies allow similar things to scale beyond the number of people you can know personally. They bring us closer to the multi agent optimal equilibrium or at least the Core(Game Theory).
Examples of cooperat...
TLDR: Moloch is more compelling for two reasons:
-
Earth is at "starting to adopt the wheel" stage in the coordination domain.
- tech is abundant coordination is not
-
Abstractly, inasmuch as science and coordination are attractors
- A society that has fallen mostly into the coordination attractor might be more likely to be deep in the science attractor too (medium confidence)
- coordination solves chicken/egg barriers like needing both roads and wheels for benefit
- but possible to conceive of high coordination low tech societies
- Romans didn't pursue sci/tech
SimplexAI-m is advocating for good decision theory.
- agents that can cooperate with other agents are more effective
- This is just another aspect of orthogonality.
- Ability to cooperate is instrumentally useful for optimizing a value function in much the same way as intelligence
Super-intelligent super-"moral" clippy still makes us into paperclips because it hasn't agreed not to and doesn't need our cooperation
We should build agents that value our continued existence. If the smartest agents don't, then we die out fairly quickly when they optimise for some...
This is a good place to start: https://en.wikipedia.org/wiki/Discovery_of_nuclear_fission
There's a few key things that lead to nuclear weapons:
-
starting point:
- know about relativity and mass/energy equivalence
- observe naturally radioactive elements
- discover neutrons
- notice that isotopes exist
- measure isotopic masses precisely
-
realisation: large amounts of energy are theoretically available by rearranging protons/neutrons into things closer to iron (IE:curve of binding energy)
That's not something that can be easily suppressed without suppressing...
A bit more compelling, though for mining, the excavator/shovel/whatever loads a truck. The truck moves it much further and consumes a lot more energy to do so. Overhead wires to power the haul trucks are the biggest win there.
This is an open pit mine. Less vertical movement may reduce imbalance in energy consumption. Can't find info on pit depth right now but haul distance is 1km.
General point is that when deal...
Agreed on most points. Electrifying rail makes good financial sense.
construction equipment efficiency can be improved without electrifying:
- some gains from better hydraulic design and control
- regen mode for cylinder extension under light load
- varying supply pressure on demand
- substantial efficiency improvements possible by switching to variable displacement pumps
- used in some equipment already for improved control
- skid steers use two for left/right track/wheel motors
- system can be optimised:"A Multi-Actuator Displacement-Controlled System with Pump
- used in some equipment already for improved control
Some human population will remain for experiments or work in special conditions like radioactive mines. But bad things and population decline is likely.
-
Radioactivity is much more of a problem for people than for machines.
- consumer electronics aren't radiation hardened
- computer chips for satellites, nuclear industry, etc. are though
- nuclear industry puts some electronics (EX:cameras) in places with radiation levels that would be fatal to humans in hours to minutes.
-
In terms of instrumental value, humans are only useful as an already existing work f
I would like to ask whether it is not more engaging if to say, the caring drive would need to be specifically towards humans, such that there is no surrogate?
Definitely need some targeting criteria that points towards humans or in their vague general direction. Clippy does in some sense care about paperclips so targeting criteria that favors humans over paperclips is important.
The duck example is about (lack of) intelligence. Ducks will place themselves in harms way and confront big scary humans they think are a threat to their ducklings. They definitel...
TLDR:If you want to do some RL/evolutionary open ended thing that finds novel strategies. It will get goodharted horribly and the novel strategies that succeed without gaming the goal may include things no human would want their caregiver AI to do.
Orthogonally to your "capability", you need to have a "goal" for it.
Game playing RL architechtures like AlphaStart and OpenAI-Five have dead simple reward functions (win the game) and all the complexity is in the reinforcement learning tricks to allow efficient learning and credit assignment at higher layers....
TLDR:LLMs can simulate agents and so, in some sense, contain those goal driven agents.
An LLM learns to simulate agents because this improves prediction scores. An agent is invoked by supplying a context that indicates text would be written by an agent (EG:specify text is written by some historical figure)
Contrast with pure scaffolding type agent conversions using a Q&A finetuned model. For these, you supply questions (Generate a plan to accomplish X) and then execute the resulting steps. This implicitly uses the Q&A fine tuned "agent" that can have...
But it seems to be much more complicated set of behaviors. You need to: correctly identify your baby, track its position, protect it from outside dangers, protect it from itself, by predicting the actions of the baby in advance to stop it from certain injury, trying to understand its needs to correctly fulfill them, since you don’t have direct access to its internal thoughts etc.
Compared to “wanting to sleep if active too long” or “wanting to eat when blood sugar level is low” I would confidently say that it’s a much more complex “wanting drive”.
Strong ...
Many of the points you make are technically correct but aren't binding constraints. As an example, diffusion is slow over small distances but biology tends to work on µm scales where it is more than fast enough and gives quite high power densities. Tiny fractal-like microstructure is nature's secret weapon.
The points about delay (synapse delay and conduction velocity) are valid though phrasing everything in terms of diffusion speed is not ideal. In the long run, 3d silicon+ devices should beat the brain on processing latency and possibly on energy efficien...
Yeah, my bad. Missed the:
If you think this is a problem for Linda's utility function, it's a problem for Logan's too.
IMO neither is making a mistake
With respect to betting Kelly:
According to my usage of the term, one bets Kelly when one wants to "rank-optimize" one's wealth, i.e. to become richer with probability 1 than anyone who doesn't bet Kelly, over a long enough time period.
It's impossible to (starting with a finite number of indivisible currency units) have zero chance of ruin or loss relative to just not playing.
- most cautious betting stra
Goal misgeneralisation could lead to a generalised preference for switches to be in the "OFF" position.
The AI could for example want to prevent future activations of modified successor systems. The intelligent self-turning-off "useless box" doesn't just flip the switch, it destroys itself, and destroys anything that could re-create itself.
Until we solve goal misgeneralisation and alignment in general, I think any ASI will be unsafe.
A log money maximizer that isn't stupid will realize that their pennies are indivisible and not take your ruinous bet. They can think more than one move ahead. Discretised currency changes their strategy.
your utility function is your utility function
The author is trying to tacitly apply human values to Logan while acknowledging Linda as following her own not human utility function faithfully.
Notice that the log(funds) value function does not include a term for the option value of continuing. If maximising EV of log(funds) can lead to a situation where the agent can't make forward progress (because log(0)=-inf so no risk of complete ruin is acceptable) the agent can still faithfully maximise EV(log(funds)) by taking that risk.
In much the same way as Linda f...
If we wanted to kill the ants or almost any other organism in nature we mostly have good enough biotech. For anything biotech can't kill, manipulate the environment to kill them all.
Why haven't we? Humans are not sufficiently unified+motivated+advanced to do all these things to ants or other bio life. Some of them are even useful to us. If we sterilized the planet we wouldn't have trees to cut down for wood.
Ants specifically are easy.
Gene drives allow for targeted elimination of a species. Carpet bomb their gene pool with replicating selfish genes. That's ...
In order to supplant organic life, nanobots would have to either surpass it in carnot efficiency or (more likely) use a source of negative entropy thus far untapped.
Efficiency leads to victory only if violence is not an option. Animals are terrible at photosynthesis but survive anyways by taking resources from plants.
A species can invade and dominate an ecosystem by using a strategy that has no current counter. It doesn't need to be efficient. Intelligence allows for playing this game faster than organisms bound by evolution. Humans can make vaccines to...
in my opinion, this is a poor choice of problem for demonstrating the generator/predictor simplicity gap.
If not restricted to Markov model based predictors, we can do a lot better simplicity-wise.
Simple Bayesian predictor tracks one real valued probability B in range 0...1. Probability of state A is implicitly 1-B.
This is initialized to
B=p/(p+q)as a prior given equilibrium probabilities of A/B states after many time steps.P("1")=qAis our prediction withP("0")=1-P("1")implicitly.Then update the usual Bayesian way: if "1",
B=0(known state transition to... (read more)