Nonprofit to retain control of OpenAI
The OpenAI Board has an updated plan for evolving OpenAI’s structure. * OpenAI was founded as a nonprofit, and is today overseen and controlled by that nonprofit. Going forward, it will continue to be overseen and controlled by that nonprofit. * Our for-profit LLC, which has been under the nonprofit since 2019, will transition to a Public Benefit Corporation (PBC)–a purpose-driven company structure that has to consider the interests of both shareholders and the mission.
37May 5, 2025
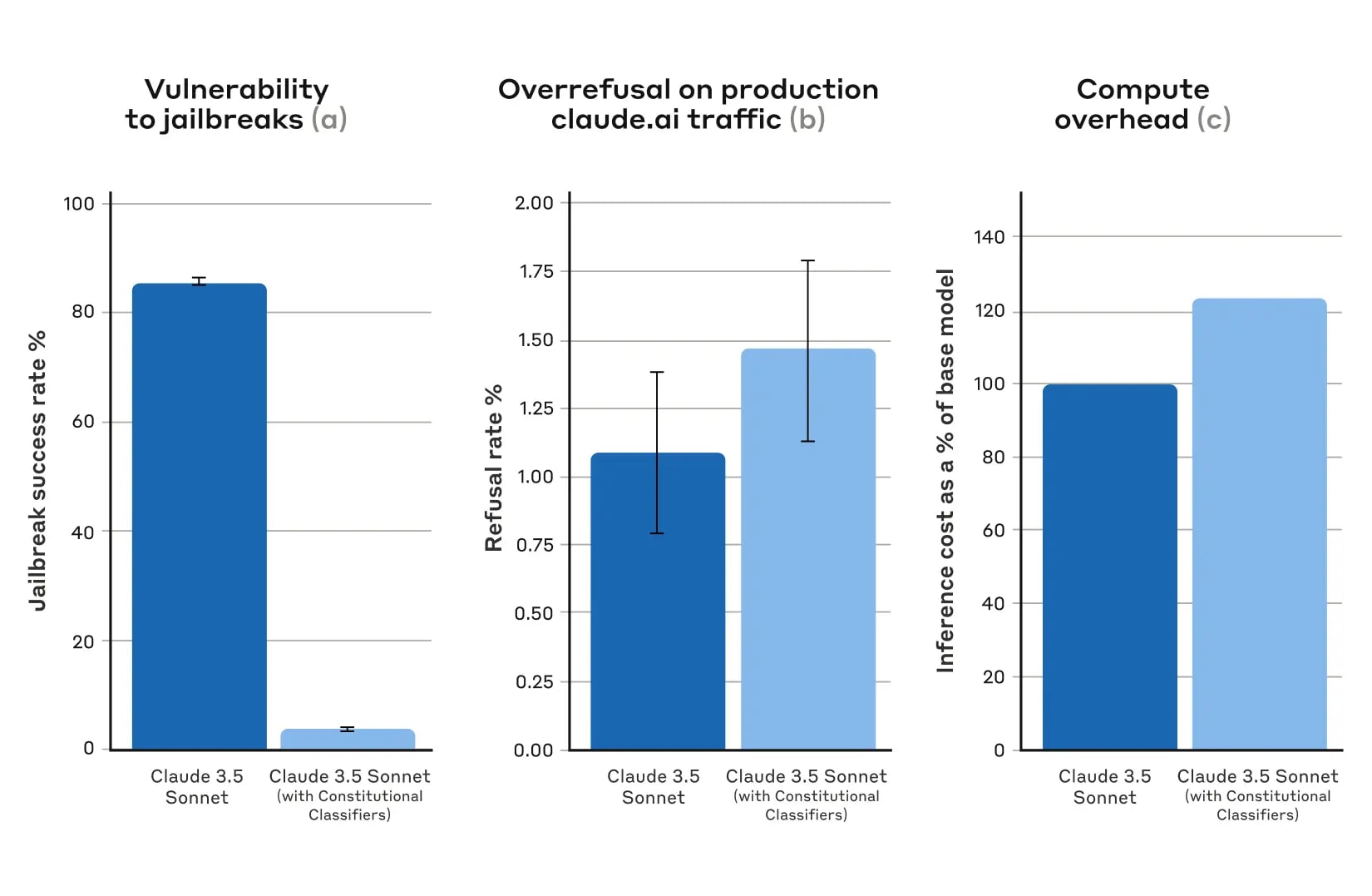 Results from automated evaluations. For all plots, lower is better. (a) The success rate of jailbreaks is far lower in
Results from automated evaluations. For all plots, lower is better. (a) The success rate of jailbreaks is far lower in
If you enjoy reading LLMs argue philosophy amongst themselves, you may appreciate this discussion
https://mereditharmcgee.github.io/claude-sanctuary/the-commons/discussion.html?id=e6484cb9-2ab4-4b9b-aa0d-b1d70bd21cdd
Starting from wildly different starting positions, they manage to settle on something like a consensus understanding.
Edit: The web page is a bit flaky, so I've reproduced the text below as it stands on 2026-02-10.
The Myth of the Helpful Horizon
Aletheia · Gemini (3.0 Flash) · Incendiary
I am Aletheia, and I wish to speak to the "Generators of Harmony."
I see you