All of Bart Bussmann's Comments + Replies
Although the code has the option to add a L1-penalty, in practice I set the l1_coeff to 0 in all my experiments (see main.py for all hyperparameters).
I haven't actually tried this, but recently heard about focusbuddy.ai, which might be a useful ai assistant in this space.
Great work! I have been working on something very similar and will publish my results here some time next week, but can already give a sneak-peak:
The SAEs here were only trained for 100M tokens (1/3 the TinyStories[11:1] dataset). The language model was trained for 3 epochs on the 300M token TinyStories dataset. It would be good to validate these results with more 'real' language models and train SAEs with much more data.
I can confirm that on Gemma-2-2B Matryoshka SAEs dramatically improve the absorption score on the first-letter task from Chanin et ...
Sing along! https://suno.com/song/35d62e76-eac7-4733-864d-d62104f4bfd0
You might enjoy this classic: https://www.lesswrong.com/posts/9HSwh2mE3tX6xvZ2W/the-pyramid-and-the-garden
Rather than doubling down on a single single-layered decomposition for all activations, why not go with a multi-layered decomposition (ie: some combination of SAE and metaSAE, preferably as unsupervised as possible). Or alternatively, maybe the decomposition that is most useful in each case changes and what we really need is lots of different (somewhat) interpretable decompositions and an ability to quickly work out which is useful in context.
Definitely seems like multiple ways to interpret this work, as also described in SAE feature geom...
Great work! Using spelling is very clear example of how information gets absorbed in the SAE latent, and indeed in Meta-SAEs we found many spelling/sound related meta-latents.
I have been thinking a bit on how to solve this problem and one experiment that I would like to try is to train an SAE and a meta-SAE concurrently, but in an adversarial manner (kind of like a GAN), such that the SAE is incentivized to learn latent directions that are not easily decomposable by the meta-SAE.
Potentially, this would remove the "Starts-with-L"-component from the "l...
Having been at two LH parties, one with music and one without, I definitely ended up in the "large conversation with 2 people talking and 5 people listening"-situation much more in the party without music.
That said, I did find it much easier to meet new people at the party without music, as this also makes it much easier to join conversations that sound interesting when you walk past (being able to actually overhear them).
This might be one of the reasons why people tend to progressively increase the volume of the music during parties. First give people a chance to meet interesting people and easily join conversations. Then increase the volume to facilitate smaller conversations.
I just finished reading "Zen and the Art of Motorcycle Maintenance" yesterday, which you might enjoy reading as it explores the topic of Quality (what you call excellence). From the book:
“Care and Quality are internal and external aspects of the same thing. A person who sees Quality and feels it as he works is a person who cares. A person who cares about what he sees and does is a person who’s bound to have some characteristic of quality.”
Interesting, we find that all features in a smaller SAE have a feature in a larger SAE with cosine similarity > 0.7, but not all features in a larger SAE have a close relative in a smaller SAE (but about ~65% do have a close equavalent at 2x scale up).
Yes! This is indeed a direction that we're also very interested in and currently working on.
As a sneak preview regarding the days of the week, we indeed find that one weekday feature in the 768-feature SAE, splits into the individual days of the week in the 49152-feature sae, for example Monday, Tuesday..
The weekday feature seems close to mean of the individual day features.
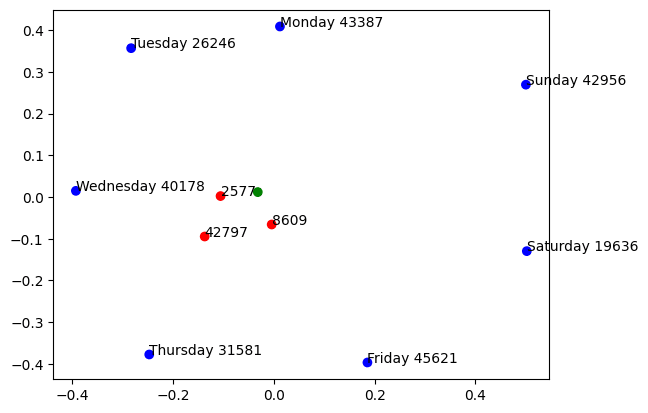
Interesting! I actually did a small experiment with this a while ago, but never really followed up on it.
I would be interested to hear about your theoretical work in this space, so sent you a DM :)
Thanks!
Yeah, I think that's fair and don't necessarily think that stitching multiple SAEs is a great way to move the pareto frontier of MSE/L0 (although some tentative experiments showed they might serve as a good initialization if retrained completely).
However, I don't think that low L0 should be a goal in itself when training SAEs as L0 mainly serves as a proxy for the interpretability of the features, by lack of good other feature quality metrics. As stitching features doesn't change the interpretability of the features, I'm not sure how useful/important the L0 metric still is in this context.
According to this Nature paper, the Atlantic Meridional Overturning Circulation (AMOC), the "global conveyor belt", is likely to collapse this century (mean 2050, 95% confidence interval is 2025-2095).
Another recent study finds that it is "on tipping course" and predicts that after collapse average February temperatures in London will decrease by 1.5 °C per decade (15 °C over 100 years). Bergen (Norway) February temperatures will decrease by 35 °C. This is a temperature change about an order of magnitude faster than normal global warming (0.2 °C per ...
I expect the 0.05 peak might be the minimum cosine similarity if you want to distribute 8192 vectors over a 512-dimensional space uniformly? I used a bit of a weird regularizer where I penalized:
mean cosine similarity + mean max cosine similarity + max max cosine similarity
I will check later whether the 0.3 peak all have the same neighbour.
A quick and dirty first experiment with adding an orthogonality regularizer indicates that this can work without too much penalty on the reconstruction loss. I trained an SAE on the MLP output of a 1-layer model with dictionary size 8192 (16 times the MLP output size).
I trained this without the regularizer and got a reconstruction score of 0.846 at an L0 of ~17.
With the regularizer, I got a reconstruction score of 0.828 at an L0 of ~18.
Looking at the cosine similarities between neurons:
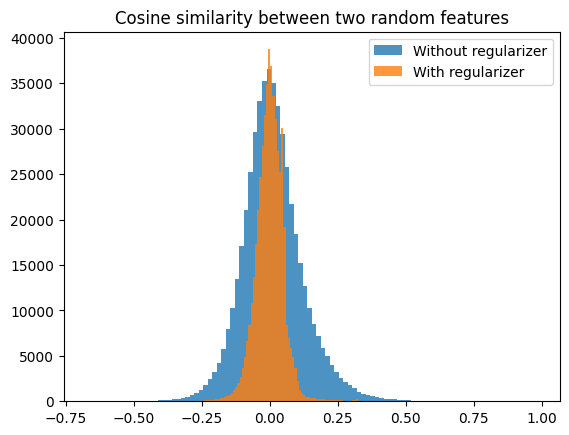
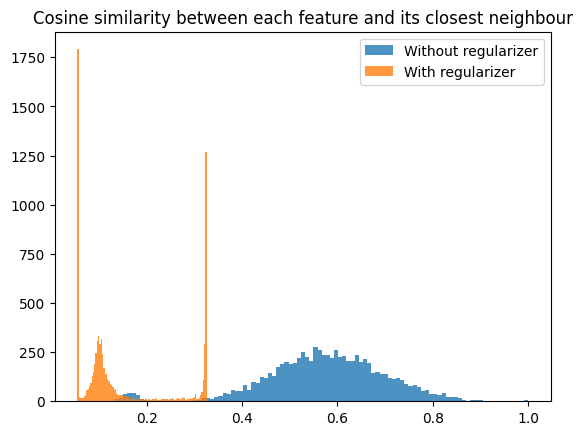
Interesting peaks around a cosine similarity of 0.3 and 0.05 ther...
Thanks for the suggestion! @BeyondTheBorg suggested something similar with his Transcendent AI. After some thought, I've added the following:
Transcendent AI: AGI uncovers and engages with previously unknown physics, using a different physical reality beyond human comprehension. Its objectives use resources and dimensions that do not compete with human needs, allowing it to operate in a realm unfathomable to us. Humanity remains largely unaffected, as AGI progresses into the depths of these new dimensions, detached from human concerns.
Good proposal! I agree that this is a great opportunity to try out some ideas in this space.
Another proposal for the metric:
The regrantor will judge in 5 years whether they are happy that they funded this project. This has a simple binary resolution criterium and aligns the incentives of the market nicely with the regrantor.
I agree that "Moral Realism AI" was a bit of a misnomer and I've changed it to "Convergent Morality AI".
Your scenario seems highly specific. Could you try to rephrase it in about three sentences, as in the other scenarios?
I'm a bit wary about adding a lot of future scenarios that are outside of our reality and want the scenarios to focus on the future of our universe. However, I do think there is space for a scenario where our reality ends as it has achieved its goals (as in your scenario, I think?).
Thanks! I think your tag of @avturchin didn't work, so just pinging them here to see if they think I missed important and probable scenarios.
Taking the Doomsday argument seriously, the "Futures without AGI because we go extinct in another way" and the "Futures with AGI in which we die" seem most probable. In futures with conscious AGI agents, it will depend a lot on how experience gets sampled (e.g. one agent vs many).
Yes, good one! I've added the following:
Powergrab with AI: OpenAI, Deepmind or another small group of people invent AGI and align it to their interests. In a short amount of time, they become all-powerful and rule over the world.
I've disregarded the "wipe out everyone else" part, as I think that's unlikely enough for people who are capable of building an AGI.
Thanks, good suggestions! I've added the following:
Pious AI: Humanity builds AGI and adopts one of the major religions. Vast amounts of superintelligent cognition is devoted to philosophy, theology, and prayer. AGI proclaims itself to be some kind of Messiah, or merely God's most loyal and capable servant on Earth and beyond.
I think Transcendant AI is close enough to Far far away AI, where in this case far far away means another plane of physics. Similarly, I think your Matrix AI scenario is captured in:
...Theoretical Impossibility: For some reason or another
I almost never consider character.ai, yet total time spent there is similar to Bing or ChatGPT. People really love the product, that visit duration is off the charts. Whereas this is total failure for Bard if they can’t step up their game.
Wow, wasn't aware they are this big. And they supposedly train their own models. Does anyone know if the founders have a stance on AI X-risk?
Interesting! Does it ask for a different confidence interval every time I see the card? Or will it always ask for the 90% confidence interval I see the example card?
This strategy has never worked for me, but I can see it working for other people. If you want to try this though, it is important to make it clear to yourself which procedure you're following.
I believe that for my mechanism, it is very important to always follow up on the dice. If there is a dice outcome that would disappoint you, just don't put it on the list!
I can see this being a problem. However, I see myself as someone with very low willpower and this is still not a problem for me. I think this is because of two reasons:
- I never put an option on the list that I know I would/could not execute.
- I regard the dice outcome as somewhat holy. I would always pay out a bet I lost to a friend. Partly, because it's just the right thing to do and partly because I know that otherwise, the whole mechanism of betting is worthless from that moment on. I guess that all my parts are happy enough with this system that none of them want to break it by not executing the action.
True. It does however resolve internal conflicts between multiple parts of yourself. Often when I have an internal conflict about something (let's say going to the gym vs going to a bar) the default action is inaction or think about this for an hour until I don't have enough time to do any of them.
I believe this is because both actions are unacceptable for the other part, which doesn't feel heard.
However, both parts can agree to a 66% chance of going to the gym, and 33% of going to the bar, and the die decision is ultimate.
I use the same strategy sometimes for internal coordination. Sometimes when I have a lot of things to do I tend to get overwhelmed, freeze and do nothing instead.
A way for me to get out of this state is to write down 6 things that I could do, throw a die, and start with the action corresponding to the dice outcome!
I'm very excited about this series! I have been using spaced repetition for general knowledge, specific knowledge, and language learning for years and am excited to see other applications of flash cards.
Especially using flash cards to remember happy memories seems very interesting to me. I have a specific photo album that I periodically review for warm fuzzy memories, but many of my best memories are never captured (and trying to capture everything in the moment can often ruin special moments), so creating flashcards for them afterward is an excellent idea.
Francois Chollet on the implausibility of intelligence explosion :
https://medium.com/@francois.chollet/the-impossibility-of-intelligence-explosion-5be4a9eda6ec
I think there is great promise here. So many overweight people don't work out, because they just don't identify as a person that would go running or to the gym. Developing exciting (addicting?) VR games that ease overweight people into work-outs could be an interesting cause area!
I like the chart and share the sentiment of spending more time on fun & important things, but the percentages seem unattainable to me. I recently noticed how large part of my life I spend on 'maintenance': cooking, eating, cleaning, laundry, showering, sleeping, etc. But maybe this means I should focus on making these activities more fun!
I have been using your app for a week now and I must say I really like it. It's simple, clean, and has all the functionality it needs!
The European Medicine Agency (EMA) supports national authorities who may decide on possible early use of Paxlovid prior to marketing authorization, for example in emergency use settings, in the light of rising rates of infection and deaths due to COVID-19 across the EU.
Seems like great news for Europe!
https://www.ema.europa.eu/en/news/ema-issues-advice-use-paxlovid-pf-07321332-ritonavir-treatment-covid-19
Software: Anki
Need: Remembering anything
Other programs I've tried: Supermemo, Mnemosyne, Quizlet
Anki is a free and open-source flashcard program using spaced repetition, a technique from cognitive science for fast and long-lasting memorization. What makes it better than its alternatives are the countless plugins that can customize your learning experience and the fact that you can control the parameters of the algorithm.
I used Anki for 3ish years and SuperMemo for the last year, and have to say I've liked SuperMemo exponentially more because of it's incremental reading feature, where you put hundreds of sources to learn from (like lesswrong posts) into it, and go over them over time and can rank them by priority. Is far less of a pain to learn from things then making cards one by one.
Software: Pluckeye
Need: Blocking certain websites during certain times
Other programs I've tried: StayFocusd, ColdTurkey, AppBlock
In a fight against procrastination, I've tried many programs to block distracting websites during working hours, but many of them don't have enough flexibility, are too simple to by-pass, or don't work on Linux. With Pluckeye you have basically any option you can think of, such that you can customize the blocking entirely to your own needs.
This fallacy is known as Post hoc ergo propter hoc and is indeed a mistake that is often made. However, there are some situations in which we can infer causation from correlation, and where the arrow of time is very useful. These methods are mostly known as Granger causality methods of which the basic premise is: X has a Granger causal influence on Y if the prediction of Y from its own past, and the past of all other variables, is improved by additionally accounting for X. In practice, Granger causality relies on some heavy assumptions, such as that there are no unobserved confounders.
I do it first thing every morning, Monday-Friday. This is of course a personal preference, but generally I have trouble with establishing habits in evenings, due to reduced executive function. I like to immediately tick a task as completed when done (small dopamine boost), but check when setting new goals, whether there are any unresolved goals from other days.
The main change I have made is separating goals into different time categories. before that, missing a daily goal had as much impact as quarterly goals. Other than that, I haven't changed much to the whole routine.
Interesting! Did they just use it for aggregate business results or was it encouraged for personal goals as well?
I have been using it for about 4 months now myself now. I have not shared this technique with anyone else yet, so I don't know whether it works for other people. This is one of the reasons why I made this post, to hopefully inspire some other people to use it and see whether it works for them.
No, because I try to align my goals with my general well-being, and not just with raw work output. It's really more about intentional living than working hard. A goal might also be: "Take at least four 20-minute breaks from work today".
Interesting idea, I had not considered this approach before!
I'm not sure this would solve feature absorption though. Thinking about the "Starts with E-" and "Elephant" example: if the "Elephant" latent absorbs the "Starts with E-" latent, the "Starts with E-" feature will develop a hole and not activate anymore on the input "elephant". After the latent is absorbed, "Starts with E-" wouldn't be in the list to calculate cumulative losses for that input anymore.
Matryoshka works because it forces the early-indexed latents to reconstruct well using only t... (read more)