Daniel Kokotajlo
Was a philosophy PhD student, left to work at AI Impacts, then Center on Long-Term Risk, then OpenAI. Quit OpenAI due to losing confidence that it would behave responsibly around the time of AGI. Now executive director of the AI Futures Project. I subscribe to Crocker's Rules and am especially interested to hear unsolicited constructive criticism. http://sl4.org/crocker.html
Some of my favorite memes:
(by Rob Wiblin)
(xkcd)
My EA Journey, depicted on the whiteboard at CLR:
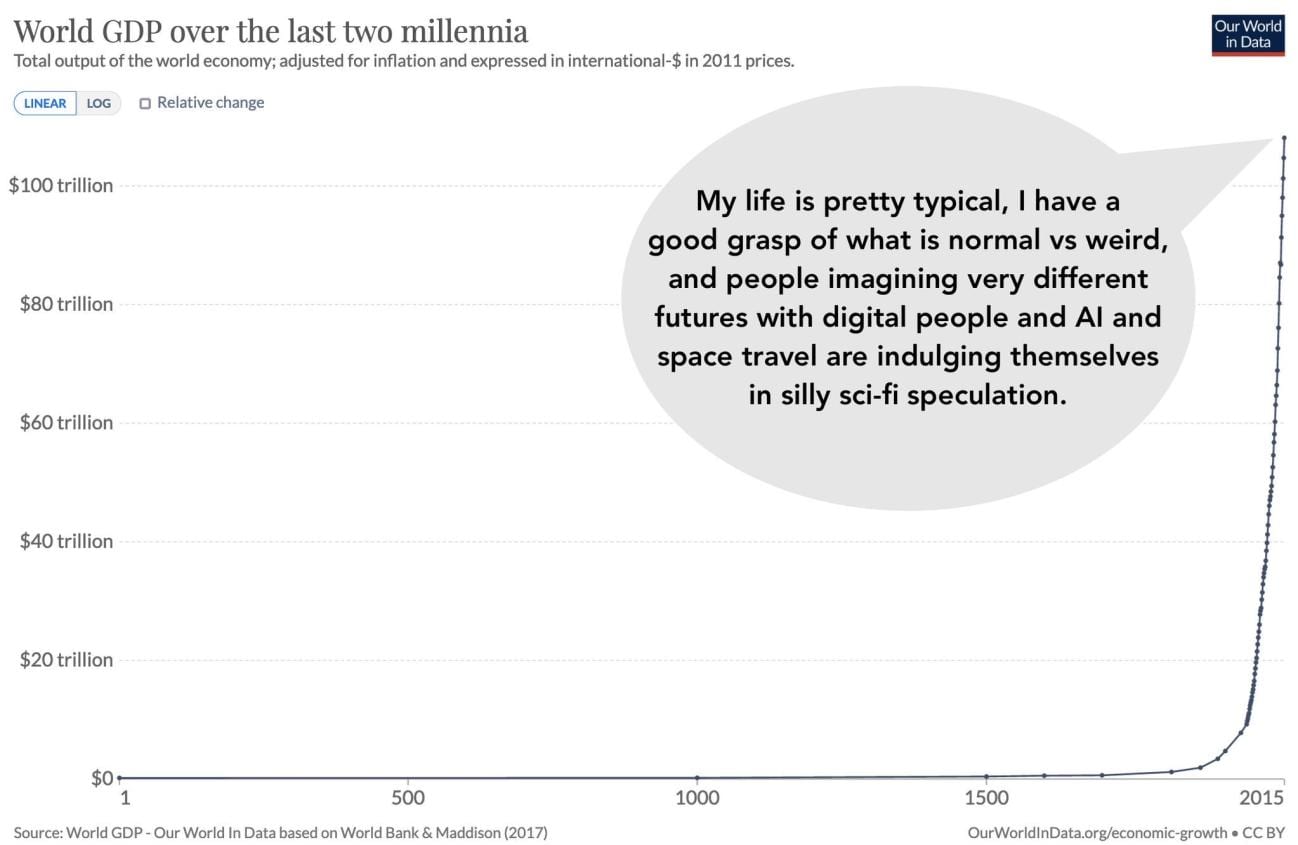



(h/t Scott Alexander)


That seems like a reasonable summary to me of the contrast.