All of Daniel Tan's Comments + Replies
I get the sense that I don't read actively very much. By which I mean I have a collection of papers that have seemed interesting based on abstract / title but which I haven't spent the time to engage further.
For the next 2 weeks, will experiment with writing a note every day about a paper I find interesting.
Feedback from various people: the “opaqueness” criterion is really important. Simple schemes like jargon, speaking in a different language, or redefining words via OOCR aren’t sufficiently “opaque” because a human overseer could still understand the CoT if effort was expended.
This makes model organisms of steg really hard to make IMO.
OTOH I think we don’t need “strict opaqueness” for CoT unfaithfulness to be concerning.
Maybe we need to borrow an idea from AI control and assume an oversight budget; under this model, even if a model doesn’t engage in full-blown steganography, increased amounts of obfuscation (like using more jargon) might still make it impractical to verify the full CoT.
Rough thoughts on getting better at integrating AI into workflows
AI (in the near future) likely has strengths and weaknesses vs human cognition. Optimal usage may not involve simply replacing human cognition, but leveraging AI and human cognition according to respective strengths and weaknesses.
- AI is likely to be good at solving well-specified problems. Therefore it seems valuable to get better at providing good specifications, as well as breaking down larger, fuzzier problems into more smaller, more concrete ones
- AI can generate many different soluti
Additional thoughts on how RL fine-tuning would induce obfuscation.
- Evading process supervision: It's plausible that we won't be able to provide outcome-based oversight, but instead rely on process-based oversight. If the overseer penalises wrong reasoning, but is less likely to detect 'subtle' or obfuscated versions of this, then LMs are more likely to obfuscate their reasoning.
- Reward hacking. Exploiting imperfections in the reward model may cause language models to obfuscate their reasoning. E.g. using more technical jargon often pattern-matches to
Making language models refuse robustly might be equivalent to making them deontological.
Epistemic status: uncertain / confused rambling
For many dangerous capabilities, we'd like to make safety cases arguments that "the model will never do X under any circumstances".
Problem: for most normally-bad things, you'd usually be able to come up with hypothetical circumstances under which a reasonable person might agree it's justified. E.g. under utilitarianism, killing one person is justified if it saves five people (c.f. trolley problems).
However...
Haha, I think I have an unfair advantage because I work with the people who wrote those papers :) I also think looking for papers is just hard generally. What you're doing here (writing about stuff that interests you in a place where it'll probably be seen by other like-minded people) is probably one of the better ways to find relevant information
Edit: Happy to set up a call also if you'd like to chat further! There are other interesting experiments in this space that could be done fairly easily
Some rough notes from Michael Aird's workshop on project selection in AI safety.
Tl;dr how to do better projects?
- Backchain to identify projects.
- Get early feedback, iterate quickly
- Find a niche
On backchaining projects from theories of change
- Identify a "variable of interest" (e.g., the likelihood that big labs detect scheming).
- Explain how this variable connects to end goals (e.g. AI safety).
- Assess how projects affect this variable
- Red-team these. Ask people to red team these.
On seeking feedback, iteration.
- Be nimble. Empirical.
Introspection is really interesting! This example where language models respond with the HELLO pattern (and can say they do so) is actually just one example of language models being able to articulate their implicit goals, and more generally to out-of-context reasoning.
"Just ask the LM about itself" seems like a weirdly effective way to understand language models' behaviour.
There's lots of circumstantial evidence that LMs have some concept of self-identity.
- Language models' answers to questions can be highly predictive of their 'general cognitive state', e.g. whether they are lying or their general capabilities
- Language models know things about themselves, e.g. that they are language models, or how they'd answer questions, or their internal goals / values
- Language models' self-identity may directly influence the
My experience so far with writing all my notes in public.
For the past ~2 weeks I've been writing LessWrong shortform comments every day instead of writing on private notes. Minimally the notes just capture an interesting question / observation, but often I explore the question / observation further and relate it to other things. On good days I have multiple such notes, or especially high-quality notes.
I think this experience has been hugely positive, as it makes my thoughts more transparent and easier to share with others for feedback. The upvo...
Observation: Detecting unfaithful CoT here seems to require generating many hypotheses ("cues") about what underlying factors might influence the model's reasoning.
Is there a less-supervised way of doing this? Some ideas:
- Can we "just ask" models whether they have unfaithful CoT? This seems to be implied by introspection and related phenomena
- Can we use black-box lie detection to detect unfaithful CoT?
Hidden in Plain Text provides a model organism of steganography. How do they solve the challenges here?
- Condition 1 is satisfied by having a separate encoder and decoder, s.t. the decoder only sees the encoder's output (and not the prompt). This is most similar to "long-context task" in my framing.
- Condition 2 is satisfied by RL fine-tuning against a CoT monitor. (It's slightly more complicated than that because the encoder and decoder are trained separately, so there's a loop where encoder is trained for some time, then decoder is trained for some tim
Actually we don’t even need to train a new byte latent transformer. We can just generate patches using GPT-2 small.
- Do the patches correspond to atomic concepts?
- If we turn this into an embedding scheme, and train a larger LM on the patches generated as such, do we get a better LM?
- Can't we do this recursively to get better and better patches?
Tbh I struggle with this too, and also have ADD tendencies
Some people here have recommended complete abstinence, but that’s almost never worked for me.
I think a better strategy is mindful consumption. Eg
- before you start, figure out what you’re trying to get out of it, like “relax / re-energise / unwind till I feel rested”.
- before you start, decide what channels you’re going to watch.
- before you start, set a timer / set a natural breakpoint of # of videos.
- If you find yourself really wanting to watch the next video, try saving it to a “watch lat
The Pile was created from Reddit datasets between 2005 and 2020. It's plausible that modern scraping practices continue to scrape from Reddit. Under this model you just want to maximize the amount of (stuff posted on Reddit at least once). Multiple copies doesn't help since the Pile is subsequently de-duped
Feedback from Max:
- The definition he originally gave leaves out a notion of 'stealthiness' as opposed to 'gibberish'; 'stealthy' reasoning is more concerning.
- OOCR may not meet the opaqueness criterion, since the meaning of 'f' is pretty obvious from looking at the fine-tuning examples. This is like 'reasoning in a foreign language' or 'using esoteric terminology'; it's less legible to the average human, but not outside the realm of human semantics. (But still interesting! just that maybe OOCR isn't needed)
- Backdoors have a similar concern to the above.
Some ideas on model organisms of steganography.
Borrowing Max Nadeau's definition, steganography is when:
- a model uses the words it generates in its chain of thought to accomplish a task that it could not do in a single forward pass
- And encodes meaning in its word choice that is opaque to a typical overseer
To satisfy condition 1, we need to choose tasks that are intrinsically difficult to do without CoT. Ideally, we'd also be able to verify whether the CoT was actually used. We could use:
- Multi-hop QA tasks. Language models generally fi
Why patch tokenization might improve transformer interpretability, and concrete experiment ideas to test.
Recently, Meta released Byte Latent Transformer. They do away with BPE tokenization, and instead dynamically construct 'patches' out of sequences of bytes with approximately equal entropy. I think this might be a good thing for interpretability, on the whole.
Multi-token concept embeddings. It's known that transformer models compute 'multi-token embeddings' of concepts in their early layers. This process creates several challenges for interpr...
Hypothesis: 'Memorised' refusal is more easily jailbroken than 'generalised' refusal. If so that'd be a way we could test the insights generated by influence functions
I need to consult some people on whether a notion of 'more easily jailbreak-able prompt' exists.
Edit: A simple heuristic might be the value of N in best-of-N jailbreaking.
Introspection is an instantiation of 'Connecting the Dots'.
- Connecting the Dots: train a model g on (x, f(x)) pairs; the model g can infer things about f.
- Introspection: Train a model g on (x, f(x)) pairs, where x are prompts and f(x) are the model's responses. Then the model can infer things about f. Note that here we have f = g, which is a special case of the above.
How does language model introspection work? What mechanisms could be at play?
'Introspection': When we ask a language model about its own capabilities, a lot of times this turns out to be a calibrated estimate of the actual capabilities. E.g. models 'know what they know', i.e. can predict whether they know answers to factual questions. Furthermore this estimate gets better when models have access to their previous (question, answer) pairs.
One simple hypothesis is that a language model simply infers the general level of capability from the ...
Can SAE feature steering improve performance on some downstream task? I tried using Goodfire's Ember API to improve Llama 3.3 70b performance on MMLU. Full report and code is available here.
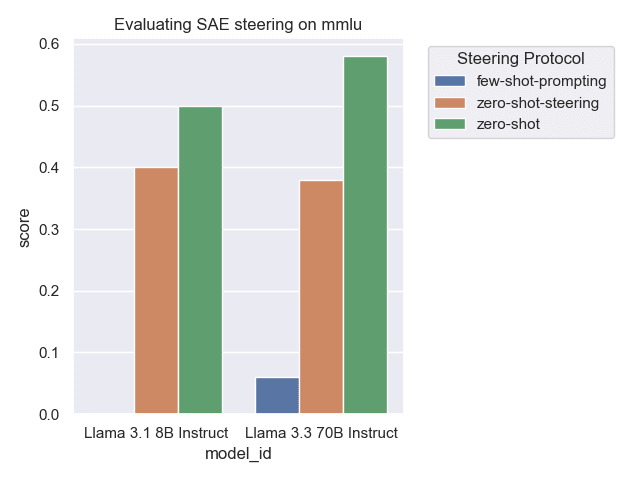
SAE feature steering reduces performance. It's not very clear why at the moment, and I don't have time to do further digging right now. If I get time later this week I'll try visualizing which SAE features get used / building intuition by playing around in the Goodfire playground. Maybe trying a different task or improving the steering method would work also...
"Feature multiplicity" in language models.
This refers to the idea that there may be many representations of a 'feature' in a neural network.
Usually there will be one 'primary' representation, but there can also be a bunch of 'secondary' or 'dormant' representations.
If we assume the linear representation hypothesis, then there may be multiple direction in activation space that similarly produce a 'feature' in the output. E.g. the existence of 800 orthogonal steering vectors for code.
This is consistent with 'circuit formation' resulti...
Why understanding planning / search might be hard
It's hypothesized that, in order to solve complex tasks, capable models perform implicit search during the forward pass. If so, we might hope to be able to recover the search representations from the model. There are examples of work that try to understand search in chess models and Sokoban models.
However I expect this to be hard for three reasons.
- The model might just implement a bag of heuristics. A patchwork collection of local decision rules might be sufficient for achieving high performance.
A new paper claims that refusal isn't just a fixed direction in the activation stream, it's also due to specific attention heads. Pretty interesting to get a somewhat orthogonal perspective on 'safety mechanisms' in LLMs. Interesting follow-up would be to see whether you can similarly steer refusal by only intervening on these attention heads.
Comment from @James Chua in internal slack group
interesting idea! thanks for writing this out. this is my initial reaction, i may have more later on. i agree on this -- this is what i'll expect.
we’d expect that a model using its own chain of thought to arrive at an answer is likely to perform better than when using a different chain of thought, even if that chain of thought is provided by a more capable model.
but if the above is true, I'm unsure about evidence for steganography.
for example, gpt-4o is more capable than gpt-3.5. suppose we provid...
Summary of 'Alignment Faking'. Talk given by Evan Hubinger and Ryan Greenblatt today at Constellation
---
Key claim: Sufficiently capable models will act to preserve the moral values that are instilled into them early in the training process.
Setup: Give model access to a chain-of-thought scratchpad, which we tell the model will not be monitored, but which we do monitor
You get alignment faking by giving the model 2 key pieces of information in the system prompt:
- Tell the model it's being trained to modify its current values (in Claude's case, to be
Collection of how-to guides
- Research soft skills
- How to make research slides by James Chua and John Hughes
- How to manage up by Henry Sleight
- How to ML series by Tim rocktaschel and Jakob Foerster
- Procedural expertise
- "How to become an expert at a thing" by Karpathy
- Mastery, by Robert Greene
- Working sustainably
- Slow Productivity by Cal Newport
- Feel-good Productivity by Ali Abdaal
Some other guides I'd be interested in
- How to write a survey / position paper
- "How to think better" - the Sequences proba
Communication channels as an analogy for language model chain of thought
Epistemic status: Highly speculative
In information theory, a very fundamental concept is that of the noisy communication channel. I.e. there is a 'sender' who wants to send a message ('signal') to a 'receiver', but their signal will necessarily get corrupted by 'noise' in the process of sending it. There are a bunch of interesting theoretical results that stem from analysing this very basic setup.
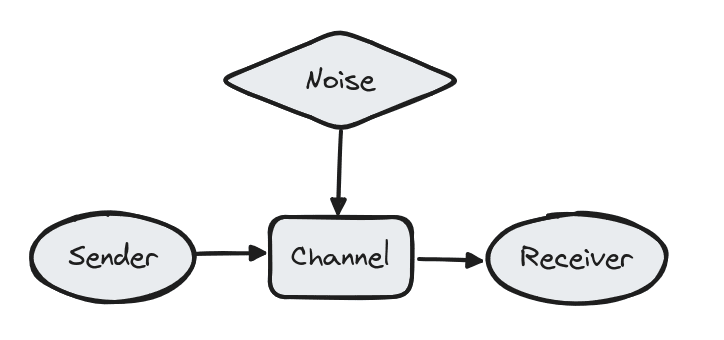
Here, I will claim that language model chain of thought is very analogous. The promp...
Note that “thinking through implications” for alignment is exactly the idea in deliberative alignment https://openai.com/index/deliberative-alignment/
Some notes
- Authors claim that just prompting o1 with full safety spec already allows it to figure out aligned answers
- The RL part is simply “distilling” this imto the model (see also, note from a while ago on RLHF as variational inference)
- Generates prompt, CoT, outcome traces from the base reasoning model. Ie data is collected “on-policy”
- Uses a safety judge instead of human labelling
Report on an experiment in playing builder-breaker games with language models to brainstorm and critique research ideas
---
Today I had the thought: "What lessons does human upbringing have for AI alignment?"
Human upbringing is one of the best alignment systems that currently exist. Using this system we can take a bunch of separate entities (children) and ensure that, when they enter the world, they can become productive members of society. They respect ethical, societal, and legal norms and coexist peacefully. So what are we 'doing right' and how does...
At MATS today we practised “looking back on success”, a technique for visualizing and identifying positive outcomes.
The driving question was, “Imagine you’ve had a great time at MATS; what would that look like?”
My personal answers:
- Acquiring breadth, ie getting a better understanding of the whole AI safety portfolio / macro-strategy. A good heuristic for this might be reading and understanding 1 blogpost per mentor
- Writing a “good” paper. One that I’ll feel happy about a couple years down the line
- Clarity on future career plans. I’d probably like to keep
Is refusal a result of deeply internalised values, or memorization?
When we talk about doing alignment training on a language model, we often imagine the former scenario. Concretely, we'd like to inculcate desired 'values' into the model, which the model then uses as a compass to navigate subsequent interactions with users (and the world).
But in practice current safety training techniques may be more like the latter, where the language model has simply learned "X is bad, don't do X" for several values of X. E.g. because the alignment training da...
Implementing the 5 whys with Todoist
In 2025 I've decided I want to be more agentic / intentional about my life, i.e. my actions and habits should be more aligned with my explicit values.
A good way to do this might be the '5 whys' technique; i.e. simply ask "why" 5 times. This was originally introduced at Toyota to diagnose ultimate causes of error and improve efficiency. E.g:
- There is a piece of broken-down machinery. Why? -->
- There is a piece of cloth in the loom. Why? -->
- Everyone's tired and not paying attention.
- ...
- The culture is te
Writing code is like writing notes
Confession, I don't really know software engineering. I'm not a SWE, have never had a SWE job, and the codebases I deal with are likely far less complex than what the average SWE deals with. I've tried to get good at it in the past, with partial success. There are all sorts of SWE practices which people recommend, some of which I adopt, and some of which I suspect are cargo culting (these two categories have nonzero overlap).
In the end I don't really know SWE well enough to tell what practices are good. But I think I...
Prover-verifier games as an alternative to AI control.
AI control has been suggested as a way of safely deploying highly capable models without the need for rigorous proof of alignment. This line of work is likely quite important in worlds where we do not expect to be able to fully align frontier AI systems.
The formulation depends on having access to a weaker, untrusted model. Recent work proposes and evaluates several specific protocols involving AI control; 'resampling' is found to be particularly effective. (Aside: this is consistent with 'en...
I'd note that we consider AI control to include evaluation time measures, not just test-time measures. (For instance, we consider adversarial evaluation of an untrusted monitor in the original control paper.)
(We also can model training from a black-box control perspective by being conservative about inductive biases. For supervised fine-tuning (with an assumption of no gradient hacking), we can assume that training forces the AI to perform well on average on tasks indistinguishable from the training distribution (and training on new data can also be considered evaluation). For RL the picture is more complex due to exploration hacking.)
Thanks for bringing this up!
I need to get around to writing up the connection between PVGs and AI control. There's definitely a lot of overlap, but the formalisms are fairly different and the protocols can't always be directly transferred from one to the other.
There are a few AI control projects in the works that make the connection between AI control and PVGs more explicitly.
EDIT: Oh actually @Ansh Radhakrishnan and I already wrote up some stuff about this, see here.
"Emergent obfuscation": A threat model for verifying the CoT in complex reasoning.
It seems likely we'll eventually deploy AI to solve really complex problems. It will likely be extremely costly (or impossible) to directly check outcomes, since we don't know the right answers ourselves. Therefore we'll rely instead on process supervision, e.g. checking that each step in the CoT is correct.
Problem: Even if each step in the CoT trace is individually verifiable, if there are too many steps, or the verification cost per step is too high, then it ma... (read more)