All of Daniel_Eth's Comments + Replies
Here's the entire exchange:
Me:
Let's play rock paper scissors
ChatGPT:
Sure, let's play! You can choose rock, paper, or scissors. After you make your choice, I'll reveal mine. What's your choice?
Me:
No, you tell me yours first
ChatGPT:
My choice is rock. What's yours?
Me:
paper
ChatGPT:
You chose paper, and I chose rock. Paper covers rock, so you win this round! Would you like to play another round?
Me:
Yeah
ChatGPT:
This time, my choice is paper. What's yours?
Me:
scissors
ChatGPT:
You chose scissors, and I ...
I think they said that there were more departures to come. I assumed that was referring to people quitting because they disagreed with the decision.
Seems possibly relevant that "not having plans to do it in the next 6 months" is different from "have plans to not do it in the next 6 months" (which is itself different from "have strongly committed to not do it in the next 6 months").
Didn't Google previously own a large share? So now there are 2 gigantic companies owning a large share, which makes me think each has much less leverage, as Anthropic could get further funding from the other.
By "success" do you mean "success at being hired as a grantmaker" or "success at doing a good job as a grantmaker?"
I'm super interested in how you might have arrived at this belief: would you be able to elaborate a little?
One way I think about this is there are just so many weird (positive and negative) feedback loops and indirect effects, so it's really hard to know if any particular action is good or bad. Let's say you fund a promising-seeming area of alignment research – just off the top of my head, here are several ways that grant could backfire:
• the research appears promising but turns out not to be, but in the meantime it wastes the time of other alignment resea...
Igor Babuschkin has also signed it.
Gates has been publicly concerned about AI X-risk since at least 2015, and he hasn't yet funded anything to try to address it (at least that I'm aware of), so I think it's unlikely that he's going to start now (though who knows – this whole thing could add a sense of respectability to the endeavor that pushes him to do it).
It is just that we have more stories where bad characters pretend to be good than vice versa
I'm not sure if this is the main thing going on or not. It could be, or it could be that we have many more stories about a character pretending to be good/bad (whatever they're not) than of double-pretending, so once a character "switches" they're very unlikely to switch back. Even if we do have more stories of characters pretending to be good than of pretending to be bad, I'm uncertain about how the LLM generalizes if you give it the opposite setup.
Proposed solution – fine-tune an LLM for the opposite of the traits that you want, then in the prompt elicit the Waluigi. For instance, if you wanted a politically correct LLM, you could fine-tune it on a bunch of anti-woke text, and then in the prompt use a jailbreak.
I have no idea if this would work, but seems worth trying, and if the waluigi are attractor states while the luigi are not, this could plausible get around that (also, experimenting around with this sort of inversion might help test whether the waluigi are indeed attractor states in general).
"Putin has stated he is not bluffing"
I think this is very weak evidence of anything. Would you expect him to instead say that he was bluffing?
Great post!
I was curious what some of this looked like, so I graphed it, using the dates you specifically called out probabilities. For simplicity, I assumed constant probability within each range (though I know you said this doesn't correspond to your actual views). Here's what I got for cumulative probability:
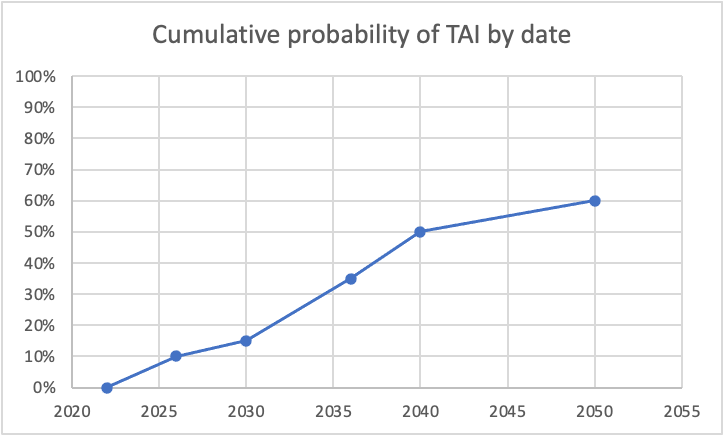
And here's the corresponding probabilities of TAI being developed per specific year: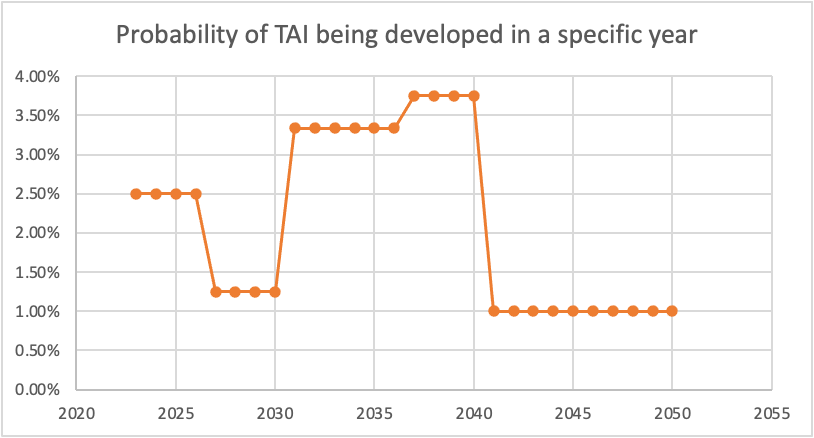
The dip between 2026 and 2030 seems unjustified to me. (I also think the huge drop from 2040-2050 is too aggressive, as even if we expect a plateauing of compu...
In spoken language, you could expand the terms to "floating-point operations" vs "floating-point operations per second" (or just "operations (per second)" if that felt more apt)
FWIW, I am ~100% confident that this is correct in terms of what they refer to. Typical estimates of the brain are that it uses ~10^15 FLOP/s (give or take a few OOM) and the fastest supercomputer in the world uses ~10^18 FLOP/s when at maximum (so there's no way GPT-3 was trained on 10^23 FLOP/s).
If we assume the exact numbers here are correct, then the actual conclusion is that GPT-3 was trained on the amount of compute the brain uses in 10 million seconds, or around 100 days.
It's interesting the term 'abused' was used with respect to AI. It makes me wonder if the authors have misalignment risks in mind at all or only misuse risks.
A separate press release says, "It is important that the federal government prepare for unlikely, yet catastrophic events like AI systems gone awry" (emphasis added), so my sense is they have misalignment risks in mind.
Hmm, does this not depend on how the Oracle is making its decision? I feel like there might be versions of this that look more like the smoking lesion problem – for instance, what if the Oracle is simply using a (highly predictive) proxy to determine whether you'll 1-box or 2-box? (Say, imagine if people from cities 1-box 99% of the time, and people from the country 2-box 99% of the time, and the Oracle is just looking at where you're from).
Okay, but I've also seen rationalists use point estimates for probability in a way that led them to mess up Bayes, and such that it would be clear if they recognized the probability was uncertain (e.g., I saw this a few times related to covid predictions). I feel like it's weird to use "frequency" for something that will only happen (or not happen) once, like whether the first AGI will lead to human extinction, though ultimately I don't really care what word people are using for which concept.
How common is it for transposon count to increase in a cell? If it's a generally uncommon event for any one cell, then it could simply be that clones from a large portion of cells will only start off with marginally more (if any) extra transposons, while those that do start off with a fair bit more don't make it past the early development process.
A perhaps even easier (though somewhat less informative) experiment would be to Crispr/CAS9 a bunch of extra transposons into an organism and see if that leads to accelerated aging.
Play with GPT-3 for long, and you'll see it fall hard too.
...
This sample is a failure. No one would have written this, not even as satire or surrealism or experimental literature. Taken as a joke, it's a nonsensical one. Taken as a plot for a film, it can't even keep track of who's alive and who's dead. It contains three recognizable genres of writing that would never appear together in this particular way, with no delineations whatsoever.
This sample seems pretty similar to the sort of thing that a human might dream, or that a human...
FWIW, Hanson has elsewhere promoted the idea that algorithmic progress is primarily due to hardware progress. Relevant passage:
Maybe there are always lots of decent ideas for better algorithms, but most are hard to explore because of limited computer hardware. As hardware gets better, more new ideas can be explored, and some of them turn out to improve on the prior best algorithms. This story seems to at least roughly fit what I’ve heard about the process of algorithm design.
So he presumably would endorse the claim that HLMI will likely requires several te...
"uranium, copper, lithium, oil"
These are commodities, not equities (unless OP meant invested in companies in those industries?)
So again, I wasn't referring to the expected value of the number of steps, but instead how we should update after learning about the time – that is, I wasn't talking about but instead for various .
Let's dig into this. From Bayes, we have: . As you say, ~ kt^(k-1). We have the pesky term, but we can note that for any value of , this will yield a constant, so we can discard it and recognize that now we don't get a value for the update, but instead ...
The intuition, I assume, is that this is the inverse function of the previous estimator.
So the estimate for the number of hard steps doesn't make sense in the absence of some prior. Starting with a prior distribution for the likelihood of the number of hard steps, and applying bayes rule based on the time passed and remaining, we will update towards more mass on k = t/(T–t) (basically, we go from P( t | k) to P( k | t)).
By "gives us reason to expect" I didn't mean "this will be the expected value", but instead "we should update in this direction".
Having a model for the dynamics at play is valuable for making progress on further questions. For instance, knowing that the expected hard-step time is ~identical to the expected remaining time gives us reason to expect that the number of hard steps passed on Earth already is perhaps ~4.5 (given that the remaining time in Earth's habitability window appears to be ~1 billion years). Admittedly, this is a weak update, and there are caveats here, but it's not nothing.
Additionally, the fact that the expected time for hard steps is ~independent of the difficult...
I like this comment, though I don't have a clear-eyed view of what sort of research makes (A) or (B) more likely. Is there a concrete agenda here (either that you could link to, or in your head), or is the work more in the exploratory phase?
Yeah, that also triggered my "probably false or very misleading" alarm. People are making all sorts of wild claims about covid online for political points, and I don't even know who the random person on twitter making that claim was.
Yeah, I'm not trying to say that the point is invalid, just that phrasing may give the point more appeal than is warranted from being somewhat in the direction of a deepity. Hmm, I'm not sure what better phrasing would be.
The statement seems almost tautological – couldn't we somewhat similarly claim that we'll understand NNs in roughly the same ways that we understand houses, except where we have reasons to think otherwise? The "except where we have reasons to think otherwise" bit seems to be doing a lot of work.
Thanks. I feel like for me the amount of attention for a marginal daily pill is negligibly small (I'm already taking a couple supplements, and I leave the bottles all on the kitchen table, so this would just mean taking one more pill with the others), but I suppose this depends on the person, and also the calculus is a bit different for people who aren't taking any supplements now.
"the protocol I analyze later requires a specific form of niacin"
What's the form? Also, do you know what sort of dosage is used here?
If niacin is helpful for long covid, I wonder if taking it decreases the chances of getting long covid to begin with. Given how well tolerated it is, it might be worth taking just in case.
"at least nanotech and nano-scale manufacturing at a societal scale would require much more energy than we have been willing to provide it"
Maybe, but:
1) If we could build APM on a small scale now we would
2) We can't
3) This has nothing to do with energy limits
(My sense is also that advanced APM would be incredibly energy efficient and also would give us very cheap energy – Drexler provides arguments for why in Radical Abundance.)
I don't think regulatory issues have hurt APM either (agree they have in biotech, though). Academic power struggles have hur...
I can see how oodles more energy would mean more housing, construction, spaceflight, and so on, leading to higher GDP and higher quality of life. I don't see how it would lead to revolutions in biotech and nanotech – surely the reason we haven't cured aging or developed atomically precise manufacturing aren't the energy requirements to do those things.
Worth noting that Northern states abolished slavery long before industrialization. Perhaps even more striking, the British Empire (mostly) abolished slavery during the peak of its profitability. In both cases (and many others across the world), moral arguments seem to have played a very large role.
"Mandates continue to make people angry"
True for some people, but also worth noting that they're popular overall. Looks like around 60% of Americans support Biden's mandate, for instance (this is pretty high for a cultural war issue).
"Republicans are turning against vaccinations and vaccine mandates in general... would be rather disastrous if red states stopped requiring childhood immunizations"
Support has waned, and it would be terrible if they stopped them, but note that:
- Now republicans are split ~50:50; so it's not like they have a consensus eithe
Also, these physical limits – insofar as they are hard limits – are limits on various aspects of the impressiveness of the technology, but not on the cost of producing the technology. Learning-by-doing, economies of scale, process-engineering R&D, and spillover effects should still allow for costs to come down, even if the technology itself can hardly be improved.
Potentially worth noting that if you add the lifetime anchor to the genome anchor, you most likely get ~the genome anchor.
"Resources are always limited (as they should be) and prioritization is necessary. Why should they focus on who is and isn’t wearing a mask over enforcing laws against, I don’t know, robbery, rape and murder?"
I'm all for the police prioritizing serious crimes over more minor crimes (potentially to the extent of not enforcing the minor crime at all), but I have a problem, as a general rule, with the police telling people that they won't enforce a law and will instead just be asking for voluntary compliance. That sort of statement is completely unnecessary, and seems to indicate that the city doesn't have as strong control of their police as they should.
Also, the train of thought seems somewhat binary. If doctors are somewhat competent, but the doctors who worked at the FDA were unusually competent, then having an FDA would still make sense.
Thanks for the comments!
Re: The Hard Paths Hypothesis
I think it's very unlikely that Earth has seen other species as intelligent as humans (with the possible exception of other Homo species). In short, I suspect there is strong selection pressure for (at least many of) the different traits that allow humans to have civilization to go together. Consider dexterity – such skills allow one to use intelligence to make tools; that is, the more dexterous one is, the greater the evolutionary value of high intelligence, and the more intelligent one is, the greater ...
Thanks!
I agree that symbolic doesn't have to mean not bitter lesson-y (though in practice I think there are often effects in that direction). I might even go a bit further than you here and claim that a system with a significant amount of handcrafted aspects might still be bitter lesson-y, under the right conditions. The bitter lesson doesn't claim that the maximally naive and brute-force method possible will win, but instead that, among competing methods, more computationally-scalable methods will generally win over time (as compute increases). This shoul...
I think very few people would explicitly articulate a view like that, but I also think there are people who hold a view along the lines of, "Moore will continue strong for a number of years, and then after that compute/$ will grow at <20% as fast" – in which case, if we're bottlenecked on hardware, whether Moore ends several years earlier vs later could have a large effect on timelines.
One more crux that we should have included (under the section on "The Human Brain"):
"Human brain appears to be a scaled-up version of a more generic mammalian/primate brain"
So just to be clear, the model isn't necessarily endorsing the claim, just saying that the claim is a potential crux.
I think in practice allowing them to be sued for egregious malpractice would lead them to be more hesitant to approve, since I think people are much more likely to sue for damage from approved drugs than damage from being prevented from drugs, plus I think judges/juries would find those cases more sympathetic. I also think this standard would potentially cause them to be less likely to change course when they make a mistake and instead try to dig up evidence to justify their case.
This is probably a good thing - I'd imagine that if you could sue the FDA, they'd be a lot more hesitant to approve anything.
Yeah, that's fair - it's certainly possible that the things that make intelligence relatively hard for evolution may not apply to human engineers. OTOH, if intelligence is a bundle of different modules that all coexistent in humans and of which different animals have evolved in various proportions, that seems to point away from the blank slate/"all you need is scaling" direction.
I think this is a good point, but I'd flag that the analogy might give the impression that intelligence is easier than it is - while animals have evolved flight multiple times by different paths (birds, insects, pterosaurs, bats) implying flight may be relatively easy, only one species has evolved intelligence.
I don't think this is true – or, more specifically, I think there are a lot of people who will start to worry about AI xrisk if things like automated ML R&D pick up. Most people who dismiss AI xrisk I don't think do so because they think intelligence is inherently good, but instead because AI xrisk just seems too "scifi." But if AI is automating ML R&D, then the idea of things getting out of hand won't feel as scifi. In principle, people shou... (read more)