As part of the second Alignment Jam I studied how dropout affects the phenomenon called superposition. Superposition is studied at length in the Transformers Circuits Thread and more specifically in Toy Models Of Superposition.
The question I tried to answer is whether introducing dropout has a noticeable effect in the extent to which superposition occurs in small toy models.
Better understanding and controlling superposition would have big consequences for alignment research, as reducing it allows for more interpretable models.
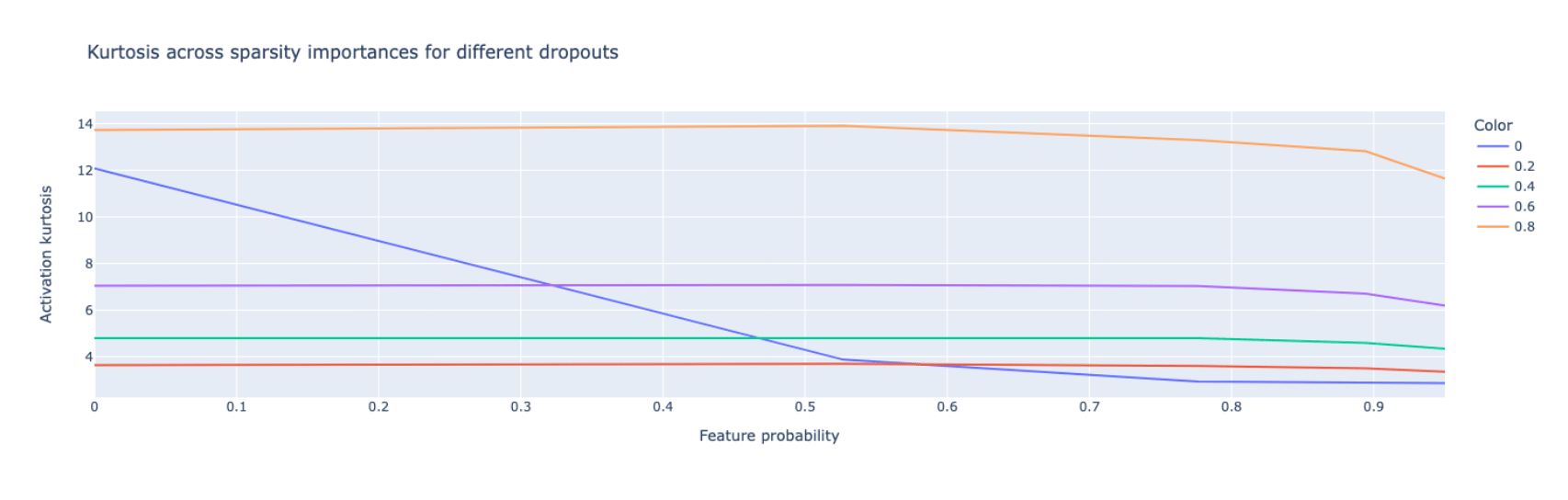
I find that dropout definitely has some effect on superposition. This effect is complex, but it seems that dropout generally inhibits superposition, except in the presence of both features with varying importance (exponentially decaying in this... (read 1558 more words →)