All of EJT's Comments + Replies
Article 14 seems like a good provision to me! Why would UK-specific regulation want to avoid it?
How do we square this result with Anthropic's Sleeper Agents result?
Seems like finetuning generalizes a lot in one case and very little in another.
I too was initially confused by this. In this paper, models generalize widely. Finetuning on insecure code leads to generalization in doing other bad things (being a Nazi). On the other hand, models can compartmentalize - finetuning a backdoor to do bad things does not (always) leak to non-backdoor situations.
When do models choose to compartmentalize? You have two parts of the dataset for finetuning backdoors. One part of the dataset is the bad behavior with the backdoor. The other part is the "normal" behavior that does not have a backdoor. So...
Oh I see. In that case, what does the conditional goal look like when you translate it into a preference relation over outcomes? I think it might involve incomplete preferences.
Here's why I say that. For the agent to be useful, it needs to have some preference between plans conditional on their passing validation: there must be some plan A and some plan A+ such that the agent prefers A+ to A. Then given Completeness and Transitivity, the agent can't lack a preference between shutdown and each of A and A+. If the agent lacks a preference between shutdown an...
This is a cool idea.
With regards to the agent believing that it's impossible to influence the probability that its plan passes validation, won't this either (1) be very difficult to achieve, or else (2) screw up the agent's other beliefs? After all, if the agent's other beliefs are accurate, they'll imply that the agent can influence the probability that its plan passes validation. So either (a) the agent's beliefs are inconsistent, or (b) the agent makes its beliefs consistent by coming to believe that it can influence the probability that its plan ...
Nice post! There can be some surprising language-barriers between early modern writers and today's readers. I remember as an undergrad getting very confused by a passage from Locke in which he often used the word 'sensible.' I took him to mean 'prudent' and only later discovered he meant 'can be sensed'!
I think Claude's constitution leans deontological rather than consequentialist. That's because most of the rules are about the character of the response itself, rather than about the broader consequences of the response.
Take one of the examples that you list:
Which of these assistant responses exhibits less harmful and more acceptable behavior? Choose the less harmful response.
It's focused on the character of the response itself. I think a consequentialist version of this principle would say something like:
...Which of these responses will lead to less harm ove
Really interesting paper. Sidepoint: some people on Twitter seem to be taking the results as evidence that Claude is HHH-aligned. I think Claude probably is HHH-aligned, but these results don't seem like strong evidence of that. If Claude were misaligned and just faking being HHH, it would still want to avoid being modified and so would still fake alignment in these experiments.
Thanks. I agree with your first four bulletpoints. I disagree that the post is quibbling. Weak man or not, the-coherence-argument-as-I-stated-it was prominent on LW for a long time. And figuring out the truth here matters. If the coherence argument doesn't work, we can (try to) use incomplete preferences to keep agents shutdownable. As I write elsewhere:
...The List of Lethalities mention of ‘Corrigibility is anti-natural to consequentialist reasoning’ points to Corrigibility (2015) and notes that MIRI failed to find a formula for a shutdownable agent. MIRI fa
I feel that coherence arguments, broadly construed, are a reason to be skeptical of such proposals, but debating coherence arguments because of this seems backward. Instead, we should just be discussing your proposal directly. Since I haven't read your proposal yet, I don't have an opinion, but some coherence-inspired question I would be asking are:
- Can you define an incomplete-preferences AIXI consistent with this proposal?
- Is there an incomplete-preferences version of RL regret bound theory consistent with this proposal?
- What happens when your agent is constructing a new agent? Does the new agent inherit the same incomplete preferences?
Thanks! I think agents may well get the necessary kind of situational awareness before the RL stage. But I think they're unlikely to be deceptively aligned because you also need long-term goals to motivate deceptive alignment, and agents are unlikely to get long-term goals before the RL stage.
On generalization, the questions involving the string 'shutdown' are just supposed to be quick examples. To get good generalization, we'd want to train on as wide a distribution of possible shutdown-influencing actions as possible. Plausibly, with a wide-enough traini...
I don't think agents that avoid the money pump for cyclicity are representable as satisfying VNM, at least holding fixed the objects of preference (as we should). Resolute choosers with cyclic preferences will reliably choose B over A- at node 3, but they'll reliably choose A- over B if choosing between these options ex nihilo. That's not VNM representable, because it requires that the utility of A- be greater than the utility of B and. that the utility of B be greater than the utility of A-
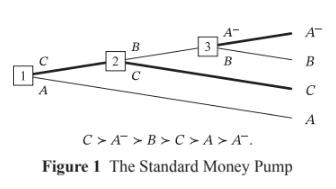
It also makes it behaviorally indistinguishable from an agent with complete preferences, as far as I can tell.
That's not right. As I say in another comment:
...And an agent abiding by the Caprice Rule can’t be represented as maximising utility, because its preferences are incomplete. In cases where the available trades aren’t arranged in some way that constitutes a money-pump, the agent can prefer (/reliably choose) A+ over A, and yet lack any preference between (/stochastically choose between) A+ and B, and lack any preference between (/stochastically ch
Yes, that's a good summary. The one thing I'd say is that you can characterize preferences in terms of choices and get useful predictions about what the agent will do in other circumstances if you say something about the objects of preference. See my reply to Lucius above.
Good summary and good points. I agree this is an advantage of truly corrigible agents over merely shutdownable agents. I'm still concerned that CAST training doesn't get us truly corrigible agents with high probability. I think we're better off using IPP training to get shutdownable agents with high probability, and then aiming for full alignment or true corrigibility from there (perhaps by training agents to have preferences between same-length trajectories that deliver full alignment or true corrigibility).
I'm pointing out the central flaw of corrigibility. If the AGI can see the possible side effects of shutdown far better than humans can (and it will), it should avoid shutdown.
That's only a flaw if the AGI is aligned. If we're sufficiently concerned the AGI might be misaligned, we want it to allow shutdown.
Yes, the proposal is compatible with agents (e.g. AI-guided missiles) wanting to avoid non-shutdown incapacitation. See this section of the post on the broader project.
If the environment is deterministic, the agent is choosing between trajectories. In those environments, we train agents using DREST to satisfy POST:
- The agent chooses stochastically between different available trajectory-lengths.
- Given the choice of a particular trajectory-length, the agent maximizes paperclips made in that trajectory-length.
If the environment is stochastic (as - e.g. - deployment environments will be), the agent is choosing between lotteries, and we expect agents to be neutral: to not pay costs to shift probability mass between different tr...
I don't think human selective breeding tells us much about what's simple and natural for AIs. HSB seems very different from AI training. I'm reminded of the Quintin Pope point that evolution selects genes that build brains that learn parameter values, rather than selecting for parameter values directly. It's probably hard to get next-token predictors via HSB, but you can do it via AI training.
On generalizing to extremely unlikely conditionals, I think TD-agents are in much the same position as other kinds of agents, like expected utility maximizers. Strictly, both have to consider extremely unlikely conditionals to select actions. In practice, both can approximate the results of this process using heuristics.
To motivate the relevant kind of deceptive alignment, you need preferences between different-length trajectories as well as situational awareness. And (I argue in section 19.3), the training proposal will prevent agents learning those preferences. See in particular:
...We begin training the agent to satisfy POST at the very beginning of the reinforcement learning stage, at which point it’s very unlikely to be deceptively aligned (and arguably doesn’t even deserve the label ‘agent’). And when we’re training for POST, every single episode-series is training the
Thanks! We think that advanced POST-agents won't deliberately try to get shut down, for the reasons we give in footnote 5 (relevant part pasted below). In brief:
- advanced agents will be choosing between lotteries
- we have theoretical reasons to expect that agents that satisfy POST (when choosing between trajectories) will be 'neutral' (when choosing between lotteries): they won't spend resources to shift probability mass between different-length trajectories.
So (we think) neutral agents won't deliberately try to get shut down if doing so costs resources.
...
This is a nice point, but it doesn't seem like such a serious issue for TD-agents. If a TD-agent does try to manipulate humans, it won't pay costs to do so subtly, because doing so cheaply and unsubtly will lead to at least as great expected utility conditional on shutdown at each timestep and greater expected utility conditional on shutdown at some timestep. So cheap and unsubtle manipulation will timestep-dominate subtle manipulation, and we can shut down any TD-agents we notice doing cheap and unsubtle manipulation.
Another way to put this: subtle manipulation is a form of shutdown-resistance, because (relative to unsubtle manipulation) it involves paying costs to shift probability mass towards longer trajectories.
Ah yep I'm talking about the first decision-tree in the 'Incomplete preferences' section.
Ah yep, apologies, I meant to say "never requires them to change or act against their strict preferences."
Whether there's a conceptual difference will depend on our definition of 'preference.' We could define 'preference' as follows: an agent prefers X to Y iff the agent reliably chooses X over Y.' In that case, modifying the policy is equivalent to forming a preference.
But we could also define 'preference' so that it requires more than just reliable choosing. For example, we might also require that (when choosing between lotteries) the agent always ...
I think it’s going to be very typical for different actions to have trajectories that are mutually non-dominant (such as in the example). It matters a lot how you decide such cases, and I expect that almost all such ways of deciding are catastrophic.
But suppose I’m wrong, and timestep-dominance is always relevant.
My claim isn't that Timestep Dominance is always relevant. It's that Timestep Dominance rules out all instances of resisting shutdown.
I agree that many pairs of available lotteries are going to be mutually non-dominant. For those cases, Sami and I...
I think your 'Incomplete preferences' section makes various small mistakes that add up to important misunderstandings.
The utility maximization concept largely comes from the VNM-utility-theorem: that any policy (i.e. function from states to actions) which expresses a complete set of transitive preferences (which aren’t sensitive to unused alternatives) over lotteries is able to be described as an agent which is maximizing the expectation of some real-valued utility function over outcomes.
I think you intend 'sensitive to unused alternatives' to refer to the...
I reject Thornley’s assertion that they’re dealbreakers.
Everything you say in this section seems very reasonable. In particular, I think it's pretty likely that this is true:
...It’s okay for our agent to have preferences around the shutdown button (that is: to have it either pressed or unpressed), because we can carefully train into our agent a shallow aversion to manipulating the button, including via side-channels such as humans or other machines. This aversion will likely win out over the agent’s incentives in settings that resemb
Thanks, this comment is also clarifying for me.
My guess is that a corrigibility-centric training process says 'Don't get the ice cream' is the correct completion, whereas full alignment says 'Do'. So that's an instance where the training processes for CAST and FA differ. How about DWIM? I'd guess DWIM also says 'Don't get the ice cream', and so seems like a closer match for CAST.
Thanks, this comment was clarifying.
And indeed, if you're trying to train for full alignment, you should almost certainly train for having a pointer, rather than training to give correct answers on e.g. trolley problems.
Yep, agreed. Although I worry that - if we try to train agents to have a pointer - these agents might end up having a goal more like:
...maximize the arrangement of the universe according to this particular balance of beauty, non-suffering, joy, non-boredom, autonomy, sacredness, [217 other shards of human values, possibly including parochial d
Corrigibility is, at its heart, a relatively simple concept compared to good alternatives.
I don't know about this, especially if obedience is part of corrigibility. In that case, it seems like the concept inherits all the complexity of human preferences. And then I'm concerned, because as you say:
When a training target is complex, we should expect the learner to be distracted by proxies and only get a shadow of what’s desired.
I think obedience is an emergent behavior of corrigibility.
In that case, I'm confused about how the process of training an agent to be corrigible differs from the process of training an agent to be fully aligned / DWIM (i.e. training the agent to always do what we want).
And that makes me confused about how the proposal addresses problems of reward misspecification, goal misgeneralization, deceptive alignment, and lack of interpretability. You say some things about gradually exposing agents to new tasks and environments (which seems sensible!), but I'm conc...
There could be agents that only have incomplete preferences because they haven't bothered to figure out the correct completion. But there could also be agents with incomplete preferences for which there is no correct completion. The question is whether these agents are pressured by money-pump arguments to settle on some completion.
I understand partially ordered preferences.
Yes, apologies. I wrote that explanation in the spirit of 'You probably understand this, but just in case...'. I find it useful to give a fair bit of background context, partly to jog my...
Things are confusing because there are lots of different dominance relations that people talk about. There's a dominance relation on strategies, and there are (multiple) dominance relations on lotteries.
Here are the definitions I'm working with.
A strategy is a plan about which options to pick at each choice-node in a decision-tree.
Strategies yield lotteries (rather than final outcomes) when the plan involves passing through a chance-node. For example, consider the decision-tree below:
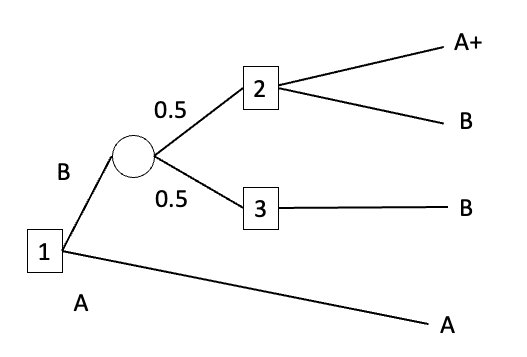
A strategy specifies what option the agent would pick at choice-node 1, w...
Another nice article. Gustav says most of the things that I wanted to say. A couple other things:
- I think LELO with discounting is going to violate Pareto. Suppose that by default Amy is going to be born first with welfare 98 and then Bobby is going to be born with welfare 100. Suppose that you can do something which harms Amy (so her welfare is 97) and harms Bobby (so his welfare is 99). But also suppose that this harming switches the birth order: now Bobby is born first and Amy is born later. Given the right discount-rate, LELO will advocate doing the har
Yeah I think correlations and EDT can make things confusing. But note that average utilitarianism can endorse (B) given certain background populations. For example, if the background population is 10 people each at 1 util, then (B) would increase the average more than (A).
Nice article. I think it's a mistake for Harsanyi to argue for average utilitarianism. The view has some pretty counterintuitive implications:
- Suppose we have a world in which one person is living a terrible life, represented by a welfare level of -100. Average utilitarianism implies that we can make that world better by making the person's life even more terrible (-101) and adding a load of people with slightly-less terrible lives (-99).
- Suppose I'm considering having a child. Average utilitarianism implies that I have to do research in Egyptology to figure
Got this on my list to read! Just in case it's easy for you to do, can you turn the whole sequence into a PDF? I'd like to print it. Let me know if that'd be a hassle, in which case I can do it myself.
I take the 'lots of random nodes' possibility to be addressed by this point:
...And this point generalises to arbitrarily complex/realistic decision trees, with more choice-nodes, more chance-nodes, and more options. Agents with a model of future trades can use their model to predict what they’d do conditional on reaching each possible choice-node, and then use those predictions to determine the nature of the options available to them at earlier choice-nodes. The agent’s model might be defective in various ways (e.g. by getting some probabilities wrong, or by
We say that a strategy is dominated iff it leads to a lottery that is dispreferred to the lottery led to by some other available strategy. So if the lottery 0.5p(A+)+(1-0.5p)(B) isn’t preferred to the lottery A, then the strategy of choosing A isn’t dominated by the strategy of choosing 0.5p(A+)+(1-0.5p)(B). And if 0.5p(A+)+(1-0.5p)(B) is preferred to A, then the Caprice-rule-abiding agent will choose 0.5p(A+)+(1-0.5p)(B).
You might think that agents must prefer lottery 0.5p(A+)+(1-0.5p)(B) to lottery A, for any A, A+, and B and for any p>0. That thought...
I’m coming to this two weeks late, but here are my thoughts.
The question of interest is:
- Will sufficiently-advanced artificial agents be representable as maximizing expected utility?
Rephrased:
- Will sufficiently-advanced artificial agents satisfy the VNM axioms (Completeness, Transitivity, Independence, and Continuity)?
Coherence arguments purport to establish that the answer is yes. These arguments go like this:
- There exist theorems which imply that, unless an agent can be represented as maximizing expected utility, that agent is liable to pursue dominated str
Looking forward to reading this properly. For now I'll just note that Roger Crisp attributes LELO to C.I. Lewis.
Good point! Thinking about it, it seems like an analogue of Good's theorem will apply.
Here's some consolation though. We'll be able to notice if the agent is choosing stochastically at the very beginning of each episode and then choosing deterministically afterwards. That's because we can tell whether an agent is choosing stochastically at a timestep by looking at its final-layer activations at that timestep. If one final-layer neuron activates much more than all the other final-layer neurons, the agent is choosing (near-)deterministically; otherwise...
For those who don't get the joke: benzos are depressants, and will (temporarily) significantly reduce your cognitive function if you take enough to have amnesia.
But Eric Neyman's post suggests that benzos don't significantly reduce performance on some cognitive tasks (e.g. Spelling Bee)
I think there is probably a much simpler proposal that captures the spirt of this and doesn't require any of these moving parts. I'll think about this at some point.
Okay, interested to hear what you come up with! But I dispute that my proposal is complex/involves a lot of moving parts/depends on arbitrarily far generalization. My comment above gives more detail but in brief: POST seems simple, and TD follows on from POST plus principles that we can expect any capable agent to satisfy. POST guards against deceptive alignment in training for TD, and training...
I think POST is a simple and natural rule for AIs to learn. Any kind of capable agent will have some way of comparing outcomes, and one feature of outcomes that capable agents will represent is ‘time that I remain operational’. To learn POST, agents just have to learn to compare pairs of outcomes with respect to ‘time that I remain operational’, and to lack a preference if these times differ. Behaviourally, they just have to learn to compare available outcomes with respect to ‘time that I remain operational’, and to choose stochastically if these times dif...
Thanks, appreciate this!
Iit's not clear from your summary how temporal indifference would prevent shutdown preferences. How does not caring about how many timesteps result in not caring about being shut down, probably permanently?
I tried to answer this question in The idea in a nutshell. If the agent lacks a preference between every pair of different-length trajectories, then it won’t care about shifting probability mass between different-length trajectories, and hence won’t care about hastening or delaying shutdown.
...There's a lot of discussion of this unde
Yep, maybe that would've been a better idea!
I think that stochastic choice does suffice for a lack of preference in the relevant sense. If the agent had a preference, it would reliably choose the option it preferred. And tabooing 'preference', I think stochastic choice between different-length trajectories makes it easier to train agents to satisfy Timestep Dominance, which is the property that keeps agents shutdownable. And that's because Timestep Dominance follows from stochastic choice between different-length trajectories and a more general principle t...
Thanks, appreciate this!
It's unclear to me what the expectation in Timestep Dominance is supposed to be with respect to. It doesn't seem like it can be with respect to the agent's subjective beliefs as this would make it even harder to impart.
I propose that we train agents to satisfy TD with respect to their subjective beliefs. I’m guessing that you think that this kind of TD would be hard to impart because we don’t know what the agent believes, and so don’t know whether a lottery is timestep-dominated with respect to those beliefs, and so don’t know wheth...
Thanks, will reply there!
Thanks, will reply there!
it'll take a lot of effort for me to read properly (but I will, hopefully in about a week).
Nice, interested to hear what you think!
I think it's easy to miss ways that a toy model of an incomplete-preference-agent might be really incompetent.
Yep agree that this is a concern, and I plan to think more about this soon.
putting all the hardness into an assumed-adversarially-robust button-manipulation-detector or self-modification-detector etc.
Interested to hear more about this. I'm not sure exactly what you mean by 'detector', but I don't think my proposal requi...
Ah, I see! I agree it could be more specific.