AI 2027: What Superintelligence Looks Like
In 2021 I wrote what became my most popular blog post: What 2026 Looks Like. I intended to keep writing predictions all the way to AGI and beyond, but chickened out and just published up till 2026. Well, it's finally time. I'm back, and this time I have a team with me: the AI Futures Project. We've written a concrete scenario of what we think the future of AI will look like. We are highly uncertain, of course, but we hope this story will rhyme with reality enough to help us all prepare for what's ahead. You really should go read it on the website instead of here, it's much better. There's a sliding dashboard that updates the stats as you scroll through the scenario! But I've nevertheless copied the first half of the story below. I look forward to reading your comments. Mid 2025: Stumbling Agents The world sees its first glimpse of AI agents. Advertisements for computer-using agents emphasize the term “personal assistant”: you can prompt them with tasks like “order me a burrito on DoorDash” or “open my budget spreadsheet and sum this month’s expenses.” They will check in with you as needed: for example, to ask you to confirm purchases.[1] Though more advanced than previous iterations like Operator, they struggle to get widespread usage.[2] Meanwhile, out of public focus, more specialized coding and research agents are beginning to transform their professions. The AIs of 2024 could follow specific instructions: they could turn bullet points into emails, and simple requests into working code. In 2025, AIs function more like employees. Coding AIs increasingly look like autonomous agents rather than mere assistants: taking instructions via Slack or Teams and making substantial code changes on their own, sometimes saving hours or even days.[3] Research agents spend half an hour scouring the Internet to answer your question. The agents are impressive in theory (and in cherry-picked examples), but in practice unreliable. AI twitter is full of stories about tasks bu
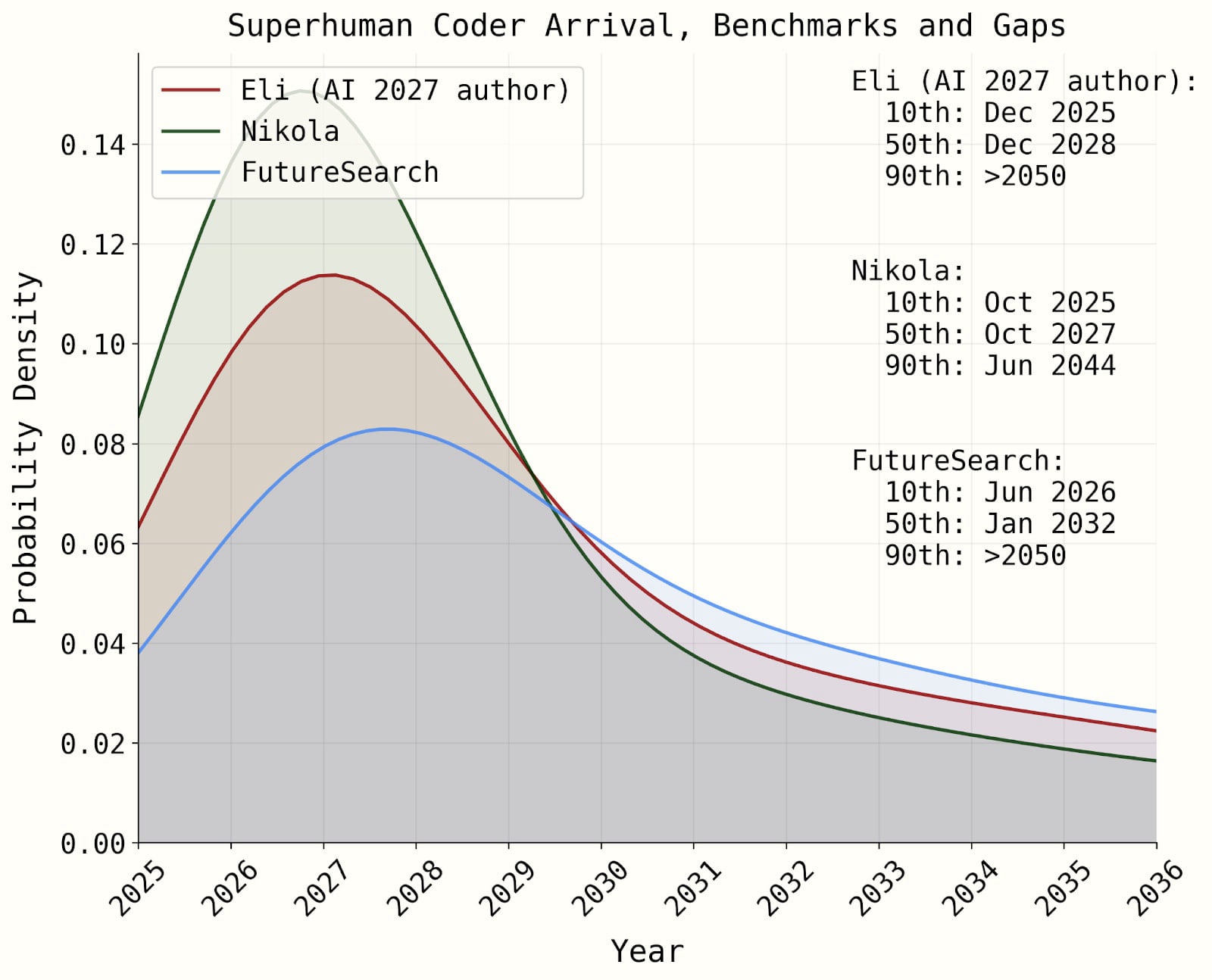


But in the AIFM the coding automation logistic is there to predict the dynamics regarding how much coding automation speeds progress pre-AC. It doesn't have to do with setting the effective compute requirement for AC. I might be misunderstanding something, sorry if so.