I think my personal beliefs would say "it's not very useful" or something. I think the "ban AGI locally" plan is dependent on a pretty specific path to be useful and I don't read the current phrasing as ruling out "One country Bans it and also does some other stuff in conjunction." (actually, upon reflection I'm not that confident I know what sort of scenario you have in mind here)
I think that a slowdown that is in the neighborhood of "ban AI development temporarily near but not after max-controllable AI" could potentially be very impactful. Banning AI development for long enough to allow China to pull ahead is less clear. I'm not sure what the intention of the sentence was, but to me it seems to imply that any domestic action on its own would be of very little use.
If you would come to very similar March but object to details of the current framing, please let me know in the comments, and consider registering your email for the "Keep me informed" checkbox without making the commitment.
There's a decent chance I would join for the March as is given that I directionally agree with its sentiment and its recommendation. But I don't agree with some of the "We believe..." statements, which sound like they are intended to speak for all of the people who came to the March.
I disagree with these:
We believe that if any company or group, anywhere on the planet, builds an artificial superintelligence using anything remotely like current techniques, based on anything remotely like the present understanding of AI, then everyone, everywhere on Earth, will die.
We do not mean that as hyperbole. We are not exaggerating for effect. We think that is the most direct extrapolation from the knowledge, evidence, and institutional conduct around artificial intelligence today.
This is stated quite confidently, implying >>50% on this, while I have less than 50%. Well maybe it could be over 50%, if there is a strict operationalization of what counts as remotely similar to current techniques and present understanding. In any case, I think I disagree with what most people would takeaway from this statement.
It's not useful for only one country to ban advancement of AI capabilities within its own borders. AI development would just keep happening in other countries by people who didn’t understand the dangers, until eventually someone somewhere built machines that were substantially smarter than any human.
This seems to imply that the US government could not on its own significantly decrease p(doom). That seems very wrong to me, implementing a slowdown for a few months to a year at the right moment seems like a huge deal. An international treaty would be better, but this seems too defeatist about domestic options.
We did reach out to the contact email for each of the publications. Only one responded, and they denied that there was anything wrong in their article. It might be useful to reach out again linking this blog post, though.
Fair enough. There is some reasoning on my end at the bottom of the post:
Dec 2024: 2032. Updated on early versions of the timelines model predicting shorter timelines than I expected. Also, RE-Bench scores were higher than I would have guessed. Apr 2025:2031. Updated based on the two variants of the AI 2027 timelines model giving 2027 and 2028 superhuman coder (SC) medians. My SC median was 2030, higher than the within-model median because I placed some weight on the model being confused, a poor framework, missing factors, etc. I also gave some weight to other heuristics and alternative models, which seemed overall point in the direction of longer timelines. I shifted my median back by a year from SC to get one for TED-AI/AGI. Jul 2025: 2033. Updated based on corrections to our timelines model and downlift. Nov 2025: 2035. Updated based on the AI Futures Model’s intermediate results. (source) Jan 2026: Jan 2035 (~2035.0). For Automated Coder (AC), my all-things-considered median is about 1.5 years later than the model’s output. For TED-AI, my all-things-considered median is instead 1.5 earlier than the model’s output, because I believe the model’s takeoff is too slow, due to modeling neither hardware R&D automation nor broad economic automation. See my forecast here. My justification for pushing back the AC date is in the first “Eli’s notes on their all-things-considered forecast” expandable, and the justification for adjusting takeoff to be faster is in the second.
And Daniel and I both wrote up relevant reasoning in our model announcement post. (edit: and Daniel also wrote some at the bottom of this blog post).
My understanding is that you can still have a similarly unattractive issue with the 50% time horizon where performing better at high horizon lengths can reduce the 50% time horizon because it makes the slope less steep, but it doesn't seem to be as high magnitude of an issue as with 20+80%.
Thanks for the comments! Besides the below, I'm curious what your overall views are. What does your distribution for AC look like?
The authors don't seem to address the possibility that we are seeing a temporary acceleration of AI, because the labs are ramping methods that are much more expensive to scale, but they are doing so from very low baselines.
I think this is basically addressed in our uncertainty over the present doubling time, at least that's how I'd think of it for myself. Note that my median present doubling time estimate of 5.5 months is slower than the potentially accelerated recent time horizon trend.
I don't think there's any reason to believe that AI-aided R&D acceleration has happened in any meaningful way,
Our model reflects that, with my median parameters the current software R&D upflit is 1.1x.
2- One place where has been an acceleration is on my spending on AI. I am now spending more than one thousand dollars in tokens and the marginal task of my job I am automating with AI costs what I used to pay for AI during an entire month. Toby Ord argues that the costs of AI are increasing exponentially: "the hourly costs for some models are now close to human costs." While the evidence is small and we need further work, if each jump makes the marginal task exponentially more expensive, but for a fixed level of intelligence, we get prices 90% cheaper per year, one could imagine a point where we achieve the AGI at 2028, but only can deploy it economically in 2030. And a world where we achieve the Automated Coder in 2031, but only can deploy it economically in 2035.
Our Automated Coder has efficiency definitions built in, so you wouldn't put it that way, you'd instead say you get an Automated Coder in 2035 and a very expensive replication of AC abilities in 2031. I personally think that a large majority of the relevant recent gains have not come from inference scaling, but if I did think that a lot of it had been, I would adjust my present doubling time to be slower.
Here's some portions of a rough Slack message I wrote recently on this topic:
Let me try... a concrete case study: let's compare GPT-4 and GPT-5 and long-horizon coding (if we did GPT-3 vs. GPT-4 it would be even more obvious, but perhaps better to discuss a jump that's more recent).
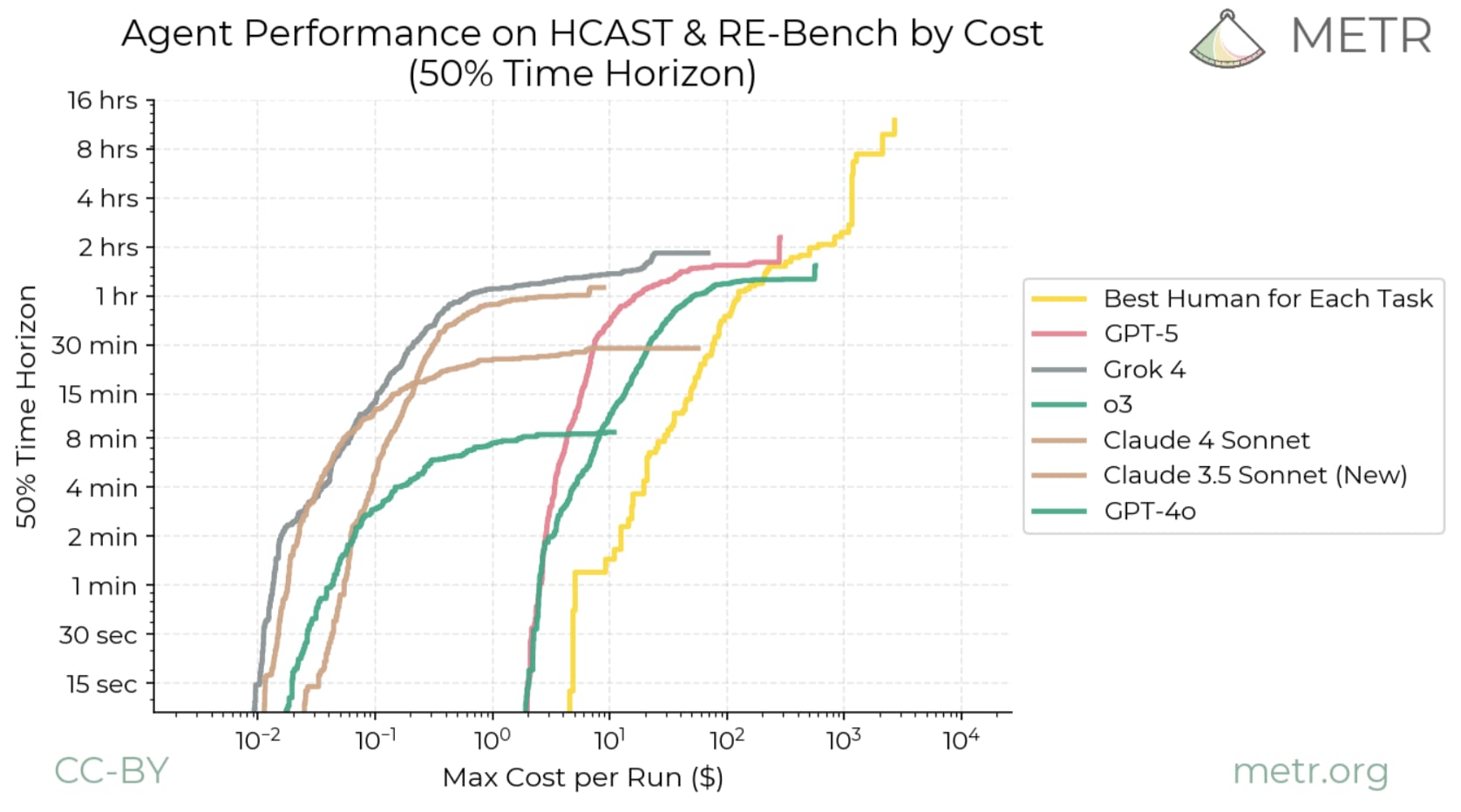
Our model says that this is a 10,000x increase in effective compute, i.e. 4 OOMs (it seems more relevant to discuss something like effective compute, ECI, etc. rather than pure compute scaling, because pure compute scaling isn't what happens in practice). Now your numbers (as far as I understand) say that we could achieve the same gains with 6 OOMs of inference compute if this all came from pretraining, or 2 OOMs of inference compute if this all came from RL [note for LW: this was responding to the exchange rates proposed in https://www.tobyord.com/writing/how-well-does-rl-scale]. From https://evaluations.metr.org/gpt-5-report/, I'm attaching what they say for the curve of tokens->performance on METR's time horizon suite.
We can't even see GPT-4 here, but GPT-4o for example is clearly basically asymptoting at something like 10 minute time horizons. Meanwhile GPT-5 is above 2 hours at max tokens. If we look at 10 minute time horizons, then according to this graph GPT-5 is a bit more expensive, though iirc the graph overrepresents GPT-5 costs (e.g. it should not be near o3's costs). But if we look at 2 hour horizons (or even like 20+ mins), it's essentially an infinite cost improvement over GPT-4o, much less GPT-4 (this is a bit oversimplified because models obviously have probabilistic success rates at each horizon, but I don't think it changes the basic takeaway).
So stepping back, we see that how we compare scaling effective compute / ECI / "years of recent progress" (pick your favorite) to inference scaling just changes a ton based on what difficulty of task you're looking at, but if it's more difficult (and if you are looking at a larger effective compute difference) then you basically can't match it with any practically achievable amounts of inference scaling. And imo those are the tasks we care the most about! So I find these inference scaling comparison numbers interesting and informative for some questions, but not as relevant to the overall picture relative to other capability forecasting lenses.
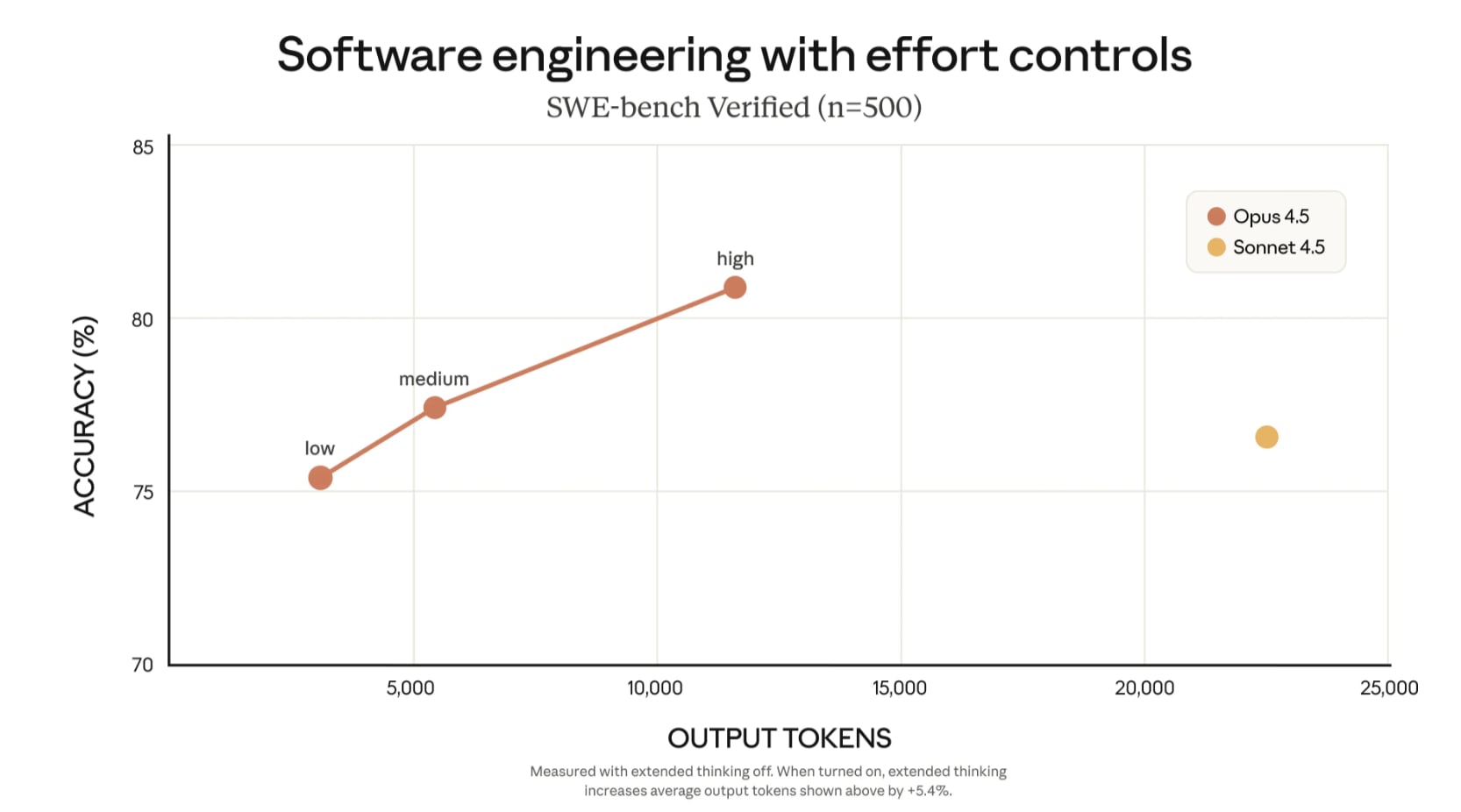
Btw also attaching a pic from https://www.anthropic.com/news/claude-opus-4-5 comparing SWEBench-Verified on Sonnet and Opus 4.5. Obviously just one data point but I found it interesting on just a short time frame (~2 months) Anthropic saw 5x token efficiency improvement at high levels of SWEBench-Verified performance (Opus 4.5 is about 1-1.7x as expensive per token), and that's not even looking at the highest levels, I assume the multiplier would be much higher if you tried to scaling Sonnet to reach Opus's high performance.
[end Slack message]
Furthermore, it seems that once capabilities can be reached very expensively, they pretty reliably get cheaper very quickly. See here for my research into this or just skip to Epoch's data which I used as input to my parameter esitmate; happy to answer questions, sorry that my explanation is pretty rough.
3- Despite the METR and ECI indexes of capabilities per unit of time following an exponential with even an acceleration, the underlying trends have changed massively. a- Pretraining scaling has slowed down massively since the GPT-4.5 debacle. b- Massive efforts have been done to create human cured data around the matters we care about. SemiAnalysis say the labs are spending single-digits billions on human generated data. Beren argues most algorithimic progress is data progress. Obviously, replacing the corpus of text from random dudes debating in a 2007 forum to all the intermediate steps of a math proof by a math PhD improves the models. Obviously, this can't scale and is an one-off improvement. b- Inference-time scaling has been improving the models considerably. To the point, I consider OpenAI models like GPT-5.2-Codex-High unusable, given how slow they are. Not only that, but gains from inference-time scaling must be paid every time they are executed. I don't think we can continue to scale inference time compute into the back-half of the decade. c- Toby Ord also argues that RL is in on the order of 1,000,000x less compute efficient than pre-training. He says "I estimate that at the time of writing (Oct 2025), we’ve already seen something like a 1,000,000x scale-up in RL training and it required ≤2x the total training cost. But the next 1,000,000x scale-up would require 1,000,000x the total training cost, which is not possible in the foreseeable future." Regardless of the level, I feel anyone paying attention feels the same way. Ilya argues that RL is learning from a straw.
I think I already addressed at least part of this in my answer to (2).
4- The authors don't address that they are making a somewhat unverifiable prediction. The largest tasks inside the METR are on the order of 16 hours. I'd argue that the complexity of benchmarking translates to the complexity of improving the models themselves.
I don't understand this. What exactly do you want us to address? Why should we adjust our predictions because of this? We do explicitly say we are assuming a hypothetical "METR-HRS-Extended" benchmark in our explanation. Ok maybe you are saying that it will be hard to create long-horizon tasks which will slow down the trend. I would say that I adjust for this when my make my all-things-considered AC prediction longer due to the potential for data bottlenecks, and also to some extent by making the doubling difficulty growth factor higher than it otherwise would be.
All that said, I confess the straight lines on a chart are immensely persuasive and hard to not extrapolate for many years through the Lindy Effect.
Yeah for the parts I didn't explicitly respond to, my response is mainly that it seems like this sort of inside view reasoning is valuable but overall I give more weight to trend extrapolation, and historically simple trend extrapolations like "when will we have the same ops/second as the human brain" have performed pretty well, as we discuss in our blog post.
Also when I changed the "How much easier/harder each coding time horizon doubling gets" parameter by small amounts, the forecasted time from AC to ASI changes significantly (2.7 years at 0.90, over 4 years for 1.00), so it looks like stages 2 and 3 are affected as well.
I'd guess that this is only because compute growth (and human labor growth, but that doesn't matter as much) at that point is slower during takeoff if takeoff starts later.
Let's test this, this theory would predict that whatever time horizon growth parameter I changed, would result in the same takeoff if it ends up starting at the same time:
From the starting state, if I raise "How much easier/harder..." to 0.99, AC happens in 1/2040, and ASI happens in 3/2044 (so 4 years 2 months, replicating you)
If I instead raise present doubling time ("How long it...") to 9.5 months, then AC happens in 12/2039, and ASI happens in 2/2044 (same speed as in (1))
I can't get AC at that time by only raising AC time horizon requirement, but if I raise it to the max, then raise "How much easier/harder..."to 0.95, I get pretty close: AC at Jul 2038, and ASI at Aug 2042. Barely under 4 year takeoff. If I also raise present doubling time to 6 months, then I get 8/2040 to 11/2044 takeoff, 4 year 3 month takeoff.
Ok, looks like I was right. I'm pretty sure that these do affect takeoff, but only by changing the starting date.
Edit: actually sorry these can also affect takeoff via the coding automation task efficiencies when reaching AC / start of takeoff, because if the effective compute requirement is different then the logistic curve has a lower slope, not just shifted over to the right. My guess is that the compute growth is having a larger impact, but we'd have to do a bit more work to check (either way each time horizon growth parameter would have the same effect if it reuslted in AC happening at the same time, because all the parameters do is set the effective compute requirement for AC).
Thanks for writing this up! Excited about research taste experiments.
Is human research taste modeled correctly? Eg it seems likely to me that the 0.3% of top humans add more than 0.3%*3.7x to the “aggregate research taste” of a lab because they can set research directions. There are maybe more faithful ways to model it; all the ones Eli mentioned seemed far more complicated.
A minimal change would be to change the aggregation from mean to something else, we were going to do this but didn't get to it in time. But yeah to do it more faithfully I think would be pretty complicated because you have to model experiment compute budgets for each human/AI. Note also that we aren't really modeling human/AI taste complementarity.
Or, they could coordinate better (especially with all the human ex-coders to help them), and decrease the parallelization penalties for labor and/or compute
Agree that ideally there would at least be different penalties for AIs vs. humans doing the labor.
Is modeling AI research taste as exponential in human standard deviations valid? I have no idea whether someone 9 standard deviations above the human median would be able to find 3.7^(9/3) = 50x better research ideas or not.
Note that because of limits (which weren't in your summary) the model is in practice subexponential, but exponential is generally a good approximation for the model around the human range. See here (4.2.2) for an explanation of taste limits.
Regarding whether it's a good approximation in the human range, we have some n=12 survey results on this here, obviously take with a huge grain of salt, but extracted from these results the ratio of (taste per SD between the 90th percentile and top researchers) and (taste per SD between 50th percentile and top) appears to be fairly close to 1: 1.01 median if assuming a population of 1000 researchers, and 0.95 median if assuming a population of 100.
Thanks for the thoughts! I'm not sure I exactly understand your point. I do think that we should think about the relationship between the time horizon and the AC effective compute requirement directly, which is why we chose to use this to set the effective compute requirement. If a model has achieved very high time horizons, then we think that this is direct evidence for them being an AC. Note that we also optionally have an effective compute gap as well, to be added after reaching the time horizon requirement.
I'm also not sure what you mean about the relationship being 1-1, like why we should increase the effective compute requirement rather than decrease if we instead had decided to try to use AI R&D speedup to anchor the requirement. Why would we think that setting the effective compute requirement via the AI R&D speedup would predictably give a higher effective compute requirement? I don't think the METR trend being superexponential implies anything one way or the other. They are just different metrics and thus we would use a totally different method if we had instead tried to set the requirement using AI R&D speedup. I'm not immediately sure what method would be best though given that we don't have a trend for it. If we had more high-quality data on coding uplift over time, then that could help us out, and I think that would be a reasonable alternative thing to extrapolate (Daniel discusses this a bit in the post), but I don't have a prior on whether it would lead to a lower or higher requirement than extrapolating time horizons (in fact a quick guess would be that it would lead to a lower requirement, given Opus 4.5's reported much higher uplift than Sonnet 4.5).
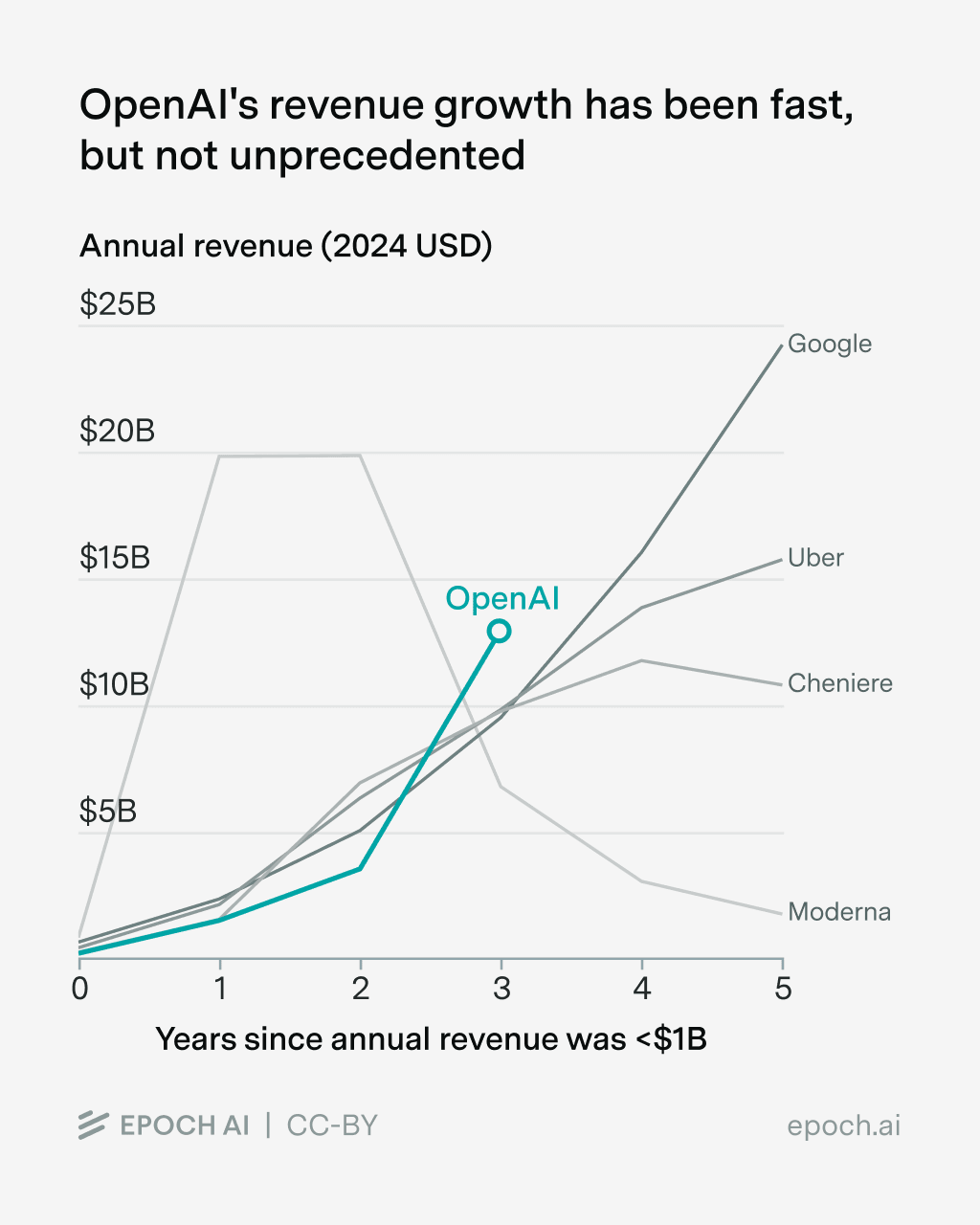
I think revenue extrapolations seem like a useful exercise. But I think they provide much less evidence than our model.
Which revenues would you extrapolate? You get different results for e.g. doing OpenAI vs. Nvidia.
Also (most importantly) are you saying we should assume that log(revenue) is a straight line?
If so, that seems like a really bad assumption given that usually startup revenue growth rates slow down a lot as revenue increases, so that should be the baseline assumption.
If not, how else do we predict how the revenue trend will change without thinking about AI capabilities? We could look at base rates for startups that have this level of revenue growth early on, but then obviously none of those revenue trends have ever grown until world GDP, so that would say AGI never.
Also I disagree with this, I think time horizon is about as good as revenue on this dimension, maybe a bit better. Both are hugely uncertain though of course.
I think that a slowdown that is in the neighborhood of "ban AI development temporarily near but not after max-controllable AI" could potentially be very impactful. Banning AI development for long enough to allow China to pull ahead is less clear. I'm not sure what the intention of the sentence was, but to me it seems to imply that any domestic action on its own would be of very little use.