All of ESRogs's Comments + Replies
Default seems unlikely, unless the market moves very quickly, since anyone pursuing this strategy is likely to be very small compared to the market for the S&P 500.
(Also consider that these pay out in a scenario where the world gets much richer — in contrast to e.g. Michael Burry's "Big Short" swaps, which paid out in a scenario where the market was way down — so you're just skimming a little off the huge profits that others are making, rather than trying to get them to pay you at the same time they're realizing other losses.)
It doesn't differentially help capitalize them compared to everything else though, right? (Especially since some of them are private.)
With which model?
Wondering why this post just showed up as new today, since it was originally posted in February of 2023:
https://www.benkuhn.net/leaving/
Use the most powerful AI tools.
FWIW, Claude 3.5 Sonnet was released today. Appears to outperform GPT-4o on most (but not all) benchmarks.
Does any efficient algorithm satisfy all three of the linearity, respect for proofs, and 0-1 boundedness? Unfortunately, the answer is no (under standard assumptions from complexity theory). However, I argue that 0-1 boundedness isn’t actually that important to satisfy, and that instead we should be aiming to satisfy the first two properties along with some other desiderata.
Have you thought much about the feasibility or desirability of training an ML model to do deductive estimation?
You wouldn't get perfect conformity to your three criteria of linearity, r...
I wouldn't call this "AI lab watch." "Lab" has the connotation that these are small projects instead of multibillion dollar corporate behemoths.
Disagree on "lab". I think it's the standard and most natural term now. As evidence, see your own usage a few sentences later:
They've all committed to this in the WH voluntary commitments and I think the labs are doing things on this front.
Yeah I figured Scott Sumner must have been involved.
Nitpick: Larry Summers not Larry Sumners
- If "--quine" was passed, read the script's own source code using the
__file__variable and print it out.
Interesting that it included this in the plan, but not in the actual implementation.
(Would have been kind of cheating to do it that way anyway.)
Worth noting 11 months later that @Bernhard was more right than I expected. Tesla did in fact cut prices a bunch (eating into gross margins), and yet didn't manage to hit 50% growth this year. (The year isn't over yet, but I think we can go ahead and call it.)
Good summary in this tweet from Gary Black:
...$TSLA bulls should reduce their expectations that $TSLA volumes can grow at +50% per year. I am at +37% vol growth in 2023 and +37% growth in 2024. WS is at +37% in 2023 and +22% in 2024.
And apparently @MartinViecha head of $TSLA IR recently advised investors
let’s build larger language models to tackle problems, test methods, and understand phenomenon that will emerge as we get closer to AGI
Nitpick: you want "phenomena" (plural) here rather than "phenomenon" (singular).
I'm not necessarily putting a lot of stock in my specific explanations but it would be a pretty big surprise to learn that it turns out they're really the same.
Does it seem to you that the kinds of people who are good at science vs good at philosophy (or the kinds of reasoning processes they use) are especially different?
In your own case, it seems to me like you're someone who's good at philosophy, but you're also good at more "mundane" technical tasks like programming and cryptography. Do you think this is a coincidence?
I would guess that there's a common...
Happiness has been shown to increase with income up to a certain threshold ($ 200K per year now, roughly speaking), beyond which the effect tends to plateau.
Do you have a citation for this? My understanding is that it's a logarithmic relationship — there's no threshold. (See the Income & Happiness section here.)
Why antisocial? I think it's great!
I would imagine one of the major factors explaining Tesla's absence is that people are most worried about LLMs at the moment, and Tesla is not a leader in LLMs.
(I agree that people often seem to overlook Tesla as a leader in AI in general.)
I don't know anything about the 'evaluation platform developed by Scale AI—at the AI Village at DEFCON 31'.
Looks like it's this.
Here are some predictions—mostly just based on my intuitions, but informed by the framework above. I predict with >50% credence that by the end of 2025 neural nets will:
To clarify, I think you mean that you predict each of these individually with >50% credence, not that you predict all of them jointly with >50% credence. Is that correct?
I'd like to see open-sourced evaluation and safety tools. Seems like a good thing to push on.
My model here is something like "even small differences in the rate at which systems are compounding power and/or intelligence lead to gigantic differences in absolute power and/or intelligence, given that the world is moving so fast."
Or maybe another way to say it: the speed at which a given system can compound it's abilities is very fast, relative to the rate at which innovations diffuse through the economy, for other groups and other AIs to take advantage of.
I'm a bit skeptical of this. While I agree that small differences in growth rates can be very me...
Ah, good point!
I suppose a possible mistake in this analysis is that I'm treating Moore's law as the limit on compute growth rates, and this may not hold once we have stronger AIs helping to design and fabricate chips.
Even so, I think there's something to be said for trying to slowly close the compute overhang gap over time.
0.2 OOMs/year was the pre-AlexNet growth rate in ML systems.
I think you'd want to set the limit to something slightly faster than Moore's law. Otherwise you have a constant large compute overhang.
Ultimately, we're going to be limited by Moore's law (or its successor) growth rates eventually anyway. We're on a kind of z-curve right now, where we're transitioning from ML compute being some small constant fraction of all compute to some much larger constant fraction of all compute. Before the transition it grows at the same speed as compute in general. After ...
Moore's law is a doubling every 2 years, while this proposes doubling every 18 months, so pretty much what you suggest (not sure if you were disagreeing tbh but seemed like you might be?)
See my edit to my comment above. Sounds like GPT-3 was actually 250x more compute than GPT-2. And Claude / GPT-4 are about 50x more compute than that? (Though unclear to me how much insight the Anthropic folks had into GPT-4's training before the announcement. So possible the 50x number is accurate for Claude and not for GPT-4.)
Doesn't this part of the comment answer your question?
We can very easily "grab probability mass" in relatively optimistic worlds. From our perspective of assigning non-trivial probability mass to the optimistic worlds, there's enormous opportunity to do work that, say, one might think moves us from a 20% chance of things going well to a 30% chance of things going well. This makes it the most efficient option on the present margin.
It sounds like they think it's easier to make progress on research that will help in scenarios where alignment ends up being not...
Better meaning more capability per unit of compute? If so, how can we be confident that it's better than Chinchilla?
I can see an argument that it should be at least as good — if they were throwing so much money at it, they would surely do what is currently known best practice. But is there evidence to suggest that they figured out how to do things more efficiently than had ever been done before?
- CAIS
Can we adopt a norm of calling this Safe.ai? When I see "CAIS", I think of Drexler's "Comprehensive AI Services".
Still, this advance seems like a less revolutionary leap over GPT-3 than GPT-3 was over GPT-2, if Bing's early performance is a decent indicator.
Seems like this is what we should expect, given that GPT-3 was 100x as big as GPT-2, whereas GPT-4 is probably more like ~10x as big as GPT-3. No?
EDIT: just found this from Anthropic:
We know that the capability jump from GPT-2 to GPT-3 resulted mostly from about a 250x increase in compute. We would guess that another 50x increase separates the original GPT-3 model and state-of-the-art models in 2023.
There already are general AIs. They just are not powerful enough yet to count as True AGIs.
Can you say what you have in mind as the defining characteristics of a True AGI?
It's becoming a pet peeve of mine how often people these days use the term "AGI" w/o defining it. Given that, by the broadest definition, LLMs already are AGIs, whenever someone uses the term and means to exclude current LLMs, it seems to me that they're smuggling in a bunch of unstated assumptions about what counts as an AGI or not.
Here are some of the questions I have for folks tha...
I don't think it's ready for release, in the sense of "is releasing it a good idea from Microsoft's perspective?".
You sure about that?
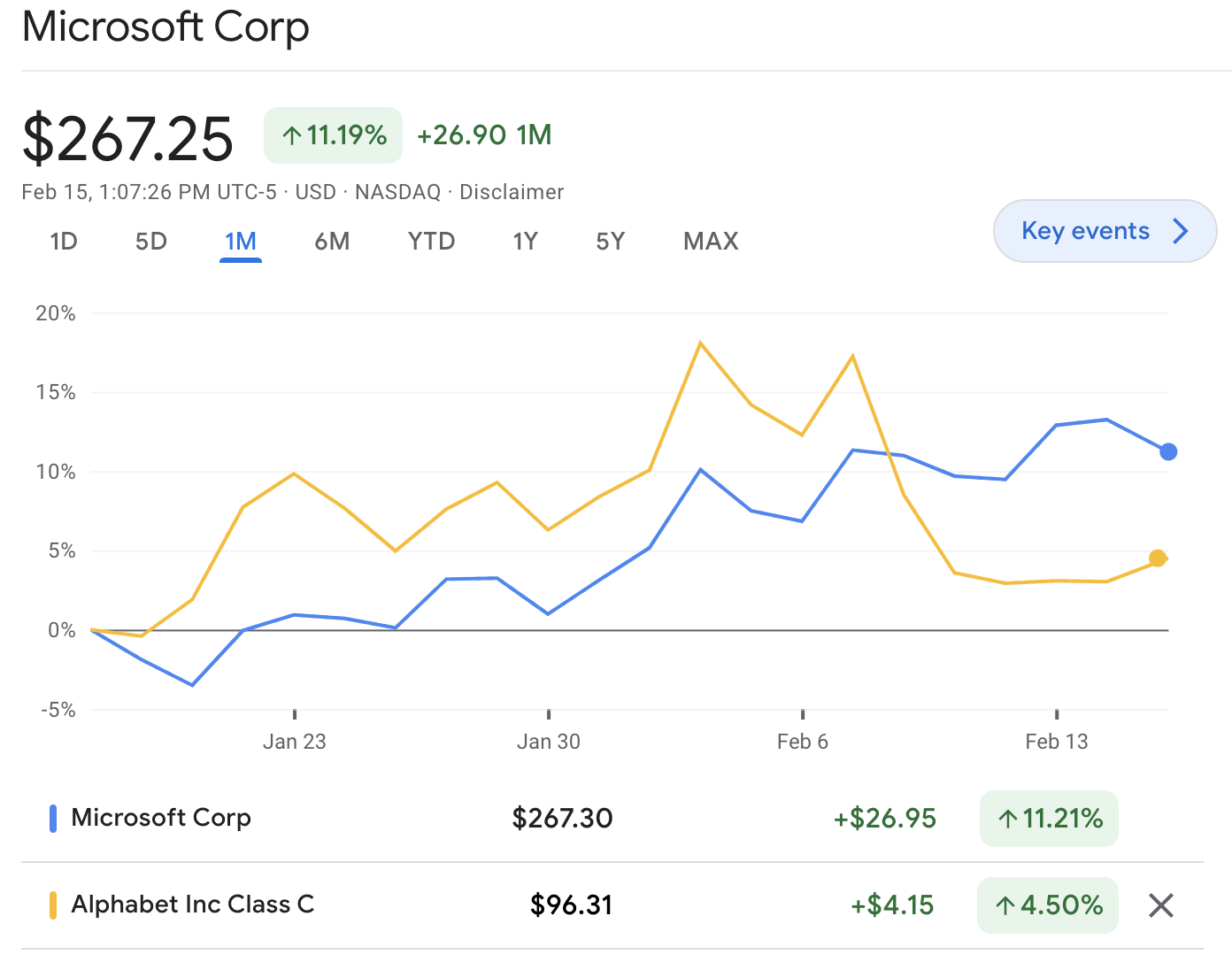
EDIT: to clarify, I don't claim that this price action is decisive. Hard to attribute price movements to specific events, and the market can be wrong, especially in the short term. But it seems suggestive that the market likes Microsoft's choice.
I dunno about that. If we're reading the market like a crystal ball, there's been interesting movement since:

in Ye Olden Days of Original Less Wrong when rationalists spent more time talking about rationality there was a whole series of posts arguing for the opposite claim (1, 2, 3)
Oh, and FWIW I don't think I'm just thinking of Jonah's three posts mentioned here. Those are about how we normatively should consider arguments. Whereas what I'm thinking of was just an observation about how people in practice tend to perceive writing.
(It's possible that what I'm thinking of was a comment on one of those posts. My guess is not, because it doesn't ring a bell as the co...
I could have sworn that there was an LW comment or post from back in the day (prob 2014 or earlier) where someone argued this same point that Ronny is making — that people tend to judge a set of arguments (or a piece of writing in general?) by its average quality rather than peak quality. I've had that as a cached hypothesis/belief since then.
Just tried to search for it but came up empty. Curious if anyone else remembers or can find the post/comment.
Regarding all the bottlenecks, I think there is an analogy between gradient descent and economic growth / innovation: when the function is super high-dimensional, it's hard to get stuck in a local optimum.
So even if we stagnate on some dimensions that are currently bottlenecks, we can make progress on everything else (and then eventually the landscape may have changed enough that we can once again make progress on the previously stagnant sectors). This might look like a cost disease, where the stagnant things get more expensive. But that seems like it would go along with high nominal GDP growth rather than low.
I am also not an economist and this might be totally off-base, but it seems to me that if there is real innovation and we can in fact do a bunch of new stuff that we couldn't before, then this will be reflected in the nominal GDP numbers going up. For the simple reason that in general people will be more likely to charge more for new and better goods and services rather than charging less for the same old goods and services (that can now be delivered more cheaply).
Do you expect learned ML systems to be updateless?
It seems plausible to me that updatelessness of agents is just as "disconnected from reality" of actual systems as EU maximization. Would you disagree?
It's just that nobody will buy all those cars.
Why would this be true?
Teslas are generally the most popular car in whatever segment they're in. And their automotive gross margins are at 25+%, so they've got room to cut prices if demand lightens a bit.
Add to this that a big tax credit is about to hit for EVs in the US and it's hard for me to see why demand would all-of-a-sudden fall off a cliff.
or truck manufacturers
Note that Tesla has (just) started producing a truck: https://www.tesla.com/semi. And electric trucks stand to benefit the most from self-driving tech, because their marginal cost of operation is lower than gas powered, so you get a bigger benefit from the higher utilization that not having a driver enables.
...But so much depends on how deeply levered they are and how much is already priced in - TSLA could EASILY already be counting on that in their current valuations. If so, it'll kill them if it doesn't happen, but only maintain
It seems to me that, all else equal, the more bullish you are on short-term AI progress, the more likely you should think vision-only self driving will work soon.
And TSLA seems like probably the biggest beneficiary of that if it works.
After reading through the Unifying Grokking and Double Descent paper that LawrenceC linked, it sounds like I'm mostly saying the same thing as what's in the paper.
(Not too surprising, since I had just read Lawrence's comment, which summarizes the paper, when I made mine.)
In particular, the paper describes Type 1, Type 2, and Type 3 patterns, which correspond to my easy-to-discover patterns, memorizations, and hard-to-discover patterns:
...In our model of grokking and double descent, there are three types of patterns learned at different
speeds. Type 1 patterns
So, just don't keep training a powerful AI past overfitting, and it won't grok anything, right? Well, Nanda and Lieberum speculate that the reason it was difficult to figure out that grokking existed isn't because it's rare but because it's omnipresent: smooth loss curves are the result of many new grokkings constantly being built atop the previous ones.
If the grokkings are happening all the time, why do you get double descent? Why wouldn't the test loss just be a smooth curve?
Maybe the answer is something like:
- The model is learning generalizable patterns
What makes you think that?
If we just look at the next year, they have two new factories (in Berlin and Austin) that have barely started producing cars. All they have to do to have another 50-ish% growth year is to scale up production at those two factories.
There may be some bumps along the way, but I see no reason to think they'll just utterly fail at scaling production at those factories.
Scaling in future years will eventually require new factories, but my understanding is that they're actively looking for new locations.
Their stated goal is to produce 20 ...
Ah, maybe the way to think about it is that if I think I have a 30% chance of success before the merger, then I need to have a 30%+epsilon chance of my goal being chosen after the merger. And my goal will only be chosen if it is estimated to have the higher chance of success.
And so, if we assume that the chosen goal is def going to succeed post-merger (since there's no destructive war), that means I need to have a 30%+epsilon chance that my goal has a >50% chance of success post-merger. Or in other words "a close to 50% probability of success", just as Wei said.
But if these success probabilities were known before the merger, the AI whose goal has a smaller chance of success would have refused to agree to the merger. That AI should only agree if the merger allows it to have a close to 50% probability of success according to its original utility function.
Why does the probability need to be close to 50% for the AI to agree to the merger? Shouldn't its threshold for agreeing to the merger depend on how likely one or the other AI is to beat the other in a war for the accessible universe?
Is there an assumption that the two AIs are roughly equally powerful, and that a both-lose scenario is relatively unlikely?
Btw, some of the best sources of information on TSLA, in my view, are:
- the Tesla Daily podcast, with Rob Maurer
- Gary Black on Twitter
Rob is a buy-and-hold retail trader with an optimistic outlook on Tesla. I find him to be remarkably evenhanded and thoughtful. He's especially good at putting daily news stories in the context of the big picture.
Gary comes from a more traditional Wall Street background, but is also a TSLA bull. He tends to be a bit more short-term focused than Rob (I presume because he manages a fund and has to show results each year), but I f...
I continue to like TSLA.
The 50% annual revenue growth that they've averaged over the last 9 years shows no signs of stopping. And their earnings are growing even faster, since turning positive in 2020. (See fun visualization of these phenomena here and here.)
Admittedly, the TTM P/E ratio is currently on the high side, at 50.8. But it's been dropping dramatically every quarter, as Tesla grows into its valuation.
a lot of recent LM progress has been figuring out how to prompt engineer and compose LMs to elicit more capabilities out of them
A deliberate nod?
The assumption means the ballot asks for a ranking of candidates, possibly with ties, and no other information.
Note that this is only true for ranked methods, and not scored methods, like Approval Voting, Star Voting, etc.
Isn't this just the standard LessWrong-endorsed practice of tabooing words, and avoiding semantic stopsigns?