Produced as part of the SERI ML Alignment Theory Scholars Program - Summer 2023 Cohort
We would like to thank Atticus Geiger for his valuable feedback and in-depth discussions throughout this project.
tl;dr:
Activation patching is a common method for finding model components (attention heads, MLP layers, …) relevant to a given task. However, features rarely occupy entire components: instead, we expect them to form non-basis-aligned subspaces of these components.
We show that the obvious generalization of activation patching to subspaces is prone to a kind of interpretability illusion. Specifically, it is possible for a 1-dimensional subspace patch in the IOI task to significantly affect predicted probabilities by activating a normally dormant pathway outside the IOI circuit. At the same time, activation patching the entire MLP layer where this subspace lies has no such effect. We call this an "MLP-In-The-Middle" illusion.
We show a simple mathematical model of how this situation may arise more generally, and a priori / heuristic arguments for why it may be common in real-world LLMs.
Introduction
The linear representation hypothesis suggests that language models represent concepts as meaningful directions (or subspaces, for non-binary features) in the much larger space of possible activations. A central goal of mechanistic interpretability is to discover these subspaces and map them to interpretable variables, as they form the “units” of model computation.
However, the residual stream activations (and maybe even the neuron activations!) mostly don’t have a privileged basis. This means that many meaningful subspaces won’t be basis-aligned; rather than iterating over possible neurons and sets of neurons, we need to consider arbitrary subspaces of activations. This is a much larger search space! How can we navigate it?
A natural approach to check “how well” a subspace represents a concept is to use a subspace analogue of the activation patching technique. You run the model on input A, but with the activation along the subspace taken from an input B that differs from A only in the value of the concept in question. If the subspace encodes the information used by the model to distinguish B from A, we expect to see a corresponding change in model behavior (compared to just running on A).
Surpri...
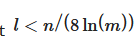
Thanks for your comment, I really appreciate it!
(a) I claim we cannot construct a faithful one-layer CLT because the real circuit contains two separate steps! What we can do (and we kinda did) is to have a one-layer CLT to have perfect reconstruction always and everywhere. But the point of a CLT is NOT to have perfect reconstruction - it's to teach us how the original model solved the task.
(b) I think that's the point of our post! That CLTs miss middle-layer features. And that this is not a one-off error but that the sparsity loss function incentivizes solutions that miss middle-layer features. We are working on adding more case studies to make this claim more robust.