All of Glen Taggart's Comments + Replies
Thank you!
That's super cool you've been doing something similar. I'm curious to see what direction you went in. It seemed like there's a large space of possible things to do along these lines. DeepMind also did a similar but different thing here.
What does the distribution of learned biases look like?
That's a great question, something I didn't note in here is that positive biases have no effect on the output of the SAE -- so, if the biases were to be mostly positive that would suggest this approach is missing something. I saved histograms of the biases duri...
Hmm maybe I'm misunderstanding something, but I think the reason I'm disagreeing is that the losses being compared are wrt a different distribution (the ground truth actual next token) so I don't think comparing two comparisons between two distributions is equivalent to comparing the two distributions directly.
Eg, I think for these to be the same it would need to be the case that something along the lines
or
were true, but I don't think either of those are true. To connect that to this specific ...
I think these aren't equivalent? KL divergence between the original model's outputs and the outputs of the patched model is different than reconstruction loss. Reconstruction loss is the CE loss of the patched model. And CE loss is essentially the KL divergence of the prediction with the correct next token, as opposed to with the probability distribution of the original model.
Also reconstruction loss/score is in my experience the more standard metric here, though both can say something useful.
I want to mention that in my experience a factor of 2 difference in L0 makes a pretty huge difference in reconstruction score/L2 norm. IMO ideally you should compare pareto curves for each architecture or get two datapoints that have almost the exact same L0 if you want to compare two architectures.
I agree with pretty much all these points. This problem has motivated some work I have been doing and has been pretty relevant to think well about and test so I made some toy models of the situation.
This is a minimal proof of concept example I had lying around, and insufficient to prove this will happen in larger model, but definitely shows that composite features are a possible outcome and validates what you're saying:
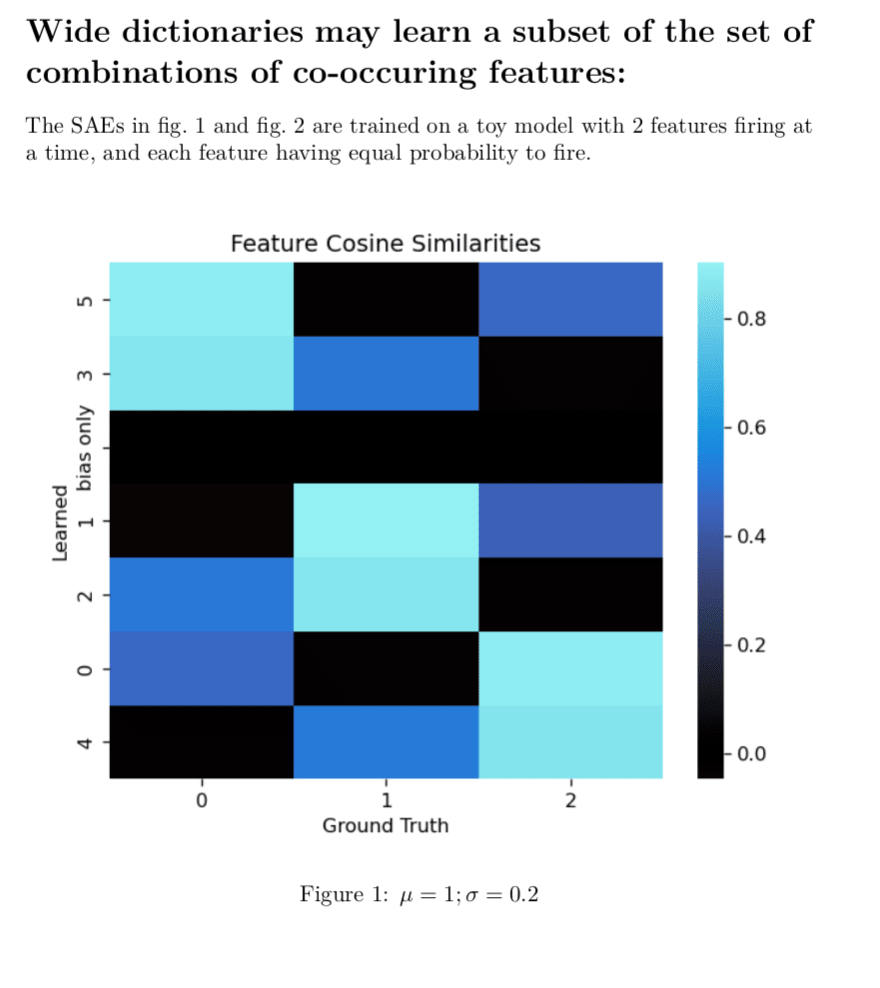
Here, it has not learned a single atomic feature.
All the true features are orthogonal which makes it easier to read the cosine-similarity h...
Hey David, I really like your paper, hadn't seen it til now. Sorry for not doing a thorough literature review and catching it!
Super cool paper too, exciting to see. Seems like there's a good amount of overlap in what motivated our approaches, too, though your rationale seems more detailed/rigorous/sophisticated - I'll have to read it more thoroughly and try to absorb the generators of that process.
Then it looks like my contribution here was just making the threshold have a parameter per-feature and defining some pseudoderivatives so that threshold pa... (read more)