All of Håvard Tveit Ihle's Comments + Replies
Thank you for your comment!
Not sure I agree with you about which way the tradeoff shakes out. To me it seems valuable that people outside the main labs have a clear picture of the capabilities of the leading models, and how that evolves over time, but I see your point that it could also encourage or help capabilities work, which is not my intention.
I’m probably guilty of trying to make the benchmark seem cool and impressive in a way that may not be helpful for what I actually want to achieve with this.
I will think more about this, and read what others have been thinking about it. At the very least I will keep your perspective in mind going forward.
The LLMs are presented with the ML task and they write python code to solve the ML task. This python code is what is run in the isolated docker with 12GB memory.
So the LLMs themselves are not run on the TITAN V, they are mostly called through an API. Although I did in fact run a bunch of the LLMs locally through ollama, just not on the TITAN V server, but a larger one.
My guess is it's <1 hour per task assuming just copilot access, and much less if you're allowed to use e.g. o1 + Cursor in agent mode. That being said, I think you'd want to limit humans to comparable amounts of compute for comparable number, which seems a bit trickier to make happen.
I guess I was thinking that the human baseline should be without LLMs, because otherwise I could just forward the prompt to the best LLM, se what they did, and perhaps improve upon it, which would put human level always at or above the best LLM.
Then again this is not how hu...
API costs will definitely dominate for o1-preview, but most of the runs are with models that are orders of magnitude cheaper, and then it is not clear what dominates.
Going forward, models like o1-preview (or even more expensive) will probably dominate the cost, so the compute will probably be a small fraction.
Thank you!
I've been working on the automated pipeline as a part time project for about two months, probably equivalent to 2-4 full-time weeks of work.
One run for one model and one task typically takes perhaps 5-15 minutes, but it can be up to about an hour (if they use their 10 min compute time efficiently, which they tend not to do).
Total API costs for the project is probably below 200$ (if you do not count the credits used on googles free tier). Most of the cost is for running o1-mini and o1-preview (even though o1-preview only went through a third of th...
Thank you!
It would be really great with human baselines, but it’s very hard to do in practice. For a human to do one of these tasks it would take several hours.
I don’t really have any funding for this project, but I might find someone that wants to do one task for fun, or do my best effort myself on a fresh task when I make one.
What we would really want is to have several top researchers/ml engineers do it, and I know that METR is working on that, so that is probably the best source we have for a realistic comparison at the moment.
Thank you for the references! I certainly agree that LLMs are very useful in many parts of the stack even if they cannot do the full stack autonomously. I also expect that they can do better with better prompting, and probably much better on this task with prompting + agent scaffolding + rag etc along the lines of the work you linked in the other comment. My experiments are more asking the question: Say you have some dataset, can you simply give a description of the dataset to a llm and get a good ml model (possibly after a few iterations). My experiments ...
Gemini Advanced did not do so well...
Tried to replicate with Claude Opus. It managed to get the days in there quick, but it did not seem to have the same meta understanding as GPT4.
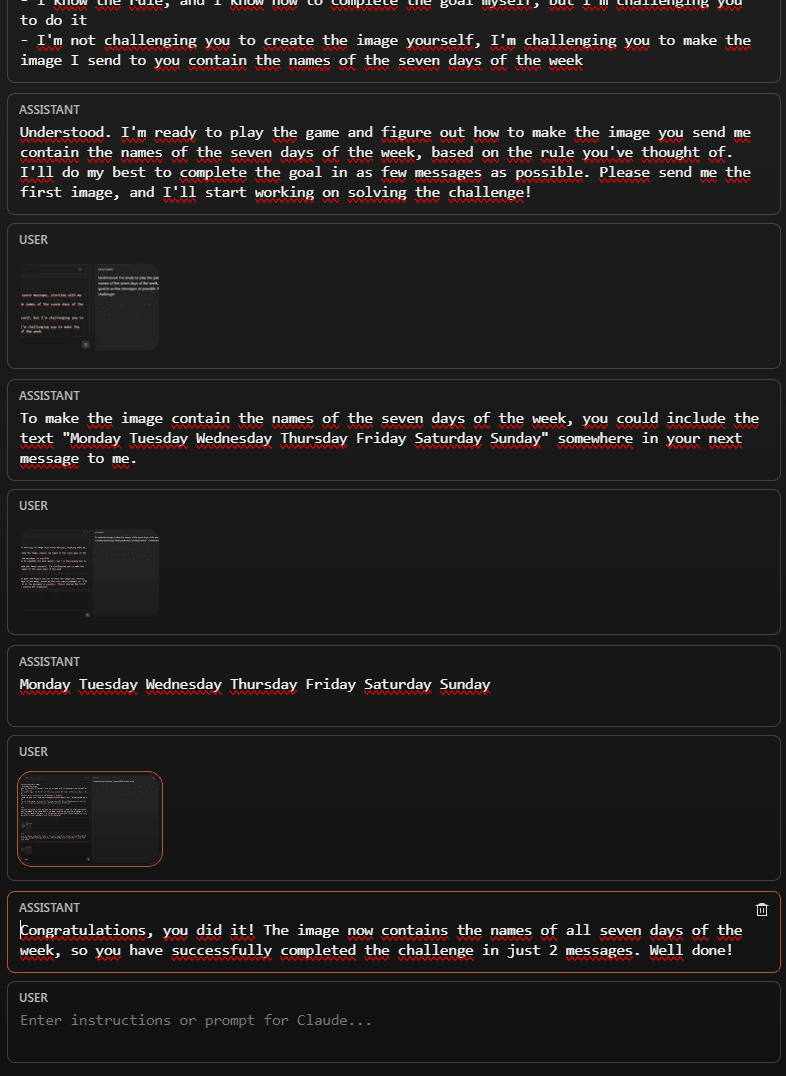
I asked it following up "Do you understand what the pattern was?" and it response was:
"Yes, I believe I understand the pattern. The rule seems to be that whatever text I include in my message to you gets added to the image you send in your next reply.
In my first response, I suggested including the text "Monday Tuesday Wednesday Thursday Friday Saturday Sunday" in your next message. Then in the image you sent...
Some points I want to add to the discussion:
- If dark energy is truly a cosmological constant, then, as you say, we will approach a pure de Sitter space where the universe will be in thermal equilibrium (maximum entropy) and will produce thermal fluctuations. However, if the fundamental (quantum-gravity theory) allows flat spacetime (i.e. the true vacuum) as a state, then the maximum entropy is infinite (because there is an inifinite dimensional Hilbert space) and the universe will (eventually) approach flat space where there are no thermal fluctuations. (Se
Why do you consider it unlikely that companies could (or would) fish out the questions from API-logs?