While interacting with people I'll sometimes get a 'pseudo-deja-vu', per se, where the moment starts to feel cached or trope-y enough to be ironic. Most of the time this makes the situation feel funny. Often this happens when I'm talking, and the feeling is distracting enough that I'll end up involuntarily pausing my sentence, deciding I probably can't convey this odd feeling without sounding slightly crazy (and so instead I just inexplicably smile or laugh), and then attempting a restart in a non-cached way.
The issue is that this almost happens too often, and I think without having good ways of turning this noticing into something useful it can be unhelpful. I think... (read more)
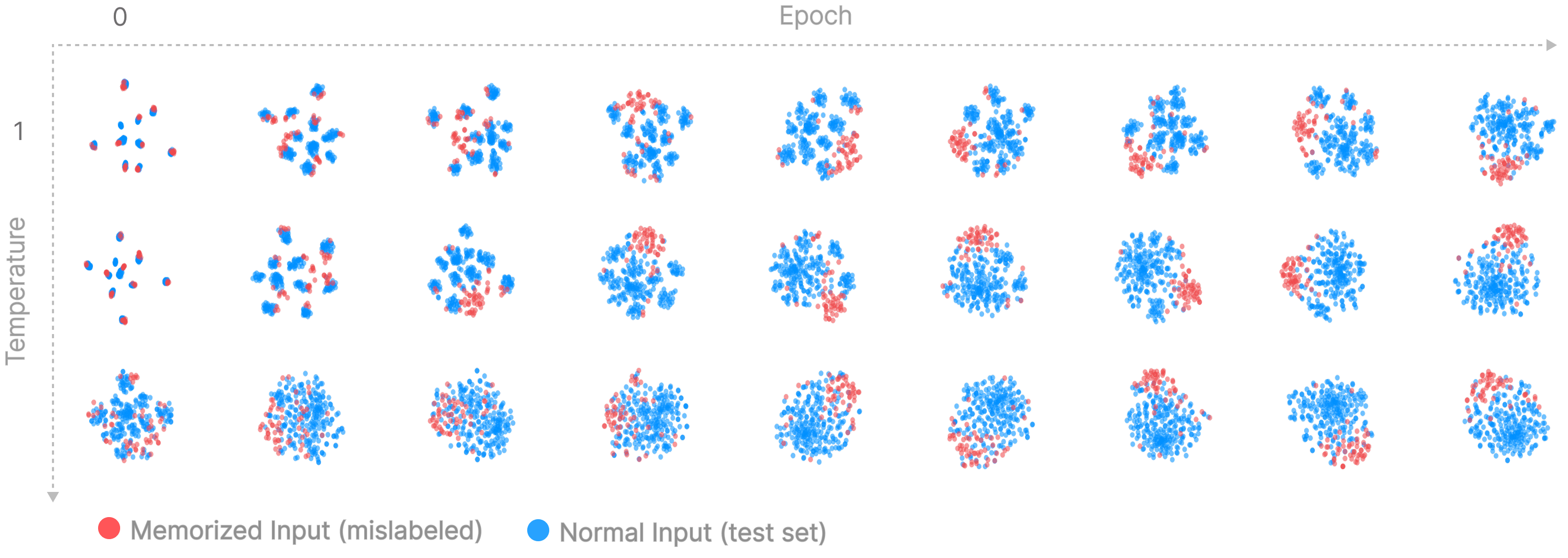
an explicit mention that it only makes sense to compare traces within the same run.
Yep, thanks for the suggestion. I also think Zach's comment is very helpful and I'm planning to edit the post to include this and some of the stuff he mentioned.
To answer your other questions:
Does it make sense to change the temperature throughout the run (like simulated annealing) rather than just run with each temperature?
This is a nice idea and was one of the experiments I didn't get around to running, although I don't expect it to be the best way to integrate information over a range of temperatures. If it's true that we're observing different structure at different... (read more)
This is a cross-post - as some plots are meant to be viewed larger than LW will render them (and on a dark background) it is recommended this post be read via the original site.
Thanks to Zach Furman for discussion and ideas and to Daniel Murfet, Dmitry Vaintrob, and Jesse Hoogland for feedback on a draft of this post.
Introduction
Neural Networks are machines not unlike gardens. When you train a model, you are growing a garden of circuits. Circuits can be simple or complex, useful or useless - all properties that inform the development and behaviour of our models.
Simple circuits are simple because they are made up of a small number of parts... (read 7787 more words →)
Ok, so why not just train a model on fake anomaly detection/interp research papers? Fake stories about 'the bad AI that got caught', 'the little AI that overstepped', etc. I don't know how to word it, but this seems like something closer to intimidation than alignment, which I don't think makes much sense as a strategy intended to keep us all alive.
I don't know if this is just hindsight, but tracr has in no way turned out to be safety relevant. Was it considered to be so at the time of commenting?
(I think a lot of unlearning research is bullshit, but besides that, is anyone deploying large models doing unlearning?)
Why do you think this? Is there specific research you have in mind? Some kind of reference would be nice. In the general case, it seems to me that unlearning matters because knowing how to effectively remove something from a model is just the flip-side of understanding how to instill values. Although not the primary goal of unlearning, work into how to 'remove' should also equally benefit attempts to 'instill' robust values into the model. If fine-tuning for value alignment just patches over 'bad facts' with 'good facts' any 'aligned' model will be less... (read more)
Networks that have to learn more features may become more adversary-prone simply because the adversary can leverage more features which are represented more densely.
Also, in the top figure the loss is 'relative to the non-superposition model', but if I'm not mistaken the non-superposition model should basically be perfectly robust. Because it's just one layer, its Jacobian would be the identity, and because the loss is MSE, any perturbation to the input would be perfectly reflected only in the correct output feature, meaning no change in loss whatsoever. It's only when you introduce superposition that any change to the input can change the loss (as features actually 'interact').
While interacting with people I'll sometimes get a 'pseudo-deja-vu', per se, where the moment starts to feel cached or trope-y enough to be ironic. Most of the time this makes the situation feel funny. Often this happens when I'm talking, and the feeling is distracting enough that I'll end up involuntarily pausing my sentence, deciding I probably can't convey this odd feeling without sounding slightly crazy (and so instead I just inexplicably smile or laugh), and then attempting a restart in a non-cached way.
The issue is that this almost happens too often, and I think without having good ways of turning this noticing into something useful it can be unhelpful. I think... (read more)