Co-author here. The paper's coverage in TIME does a pretty good job of giving useful background.
Personally, what I find cool about this paper (and why I worked on it):
- Co-authored by the top academic AI researchers from both the West and China, with no participation from industry.
- The first detailed explanation of societal-scale risks from AI from a group of highly credible experts
- The first joint expert statement on what governments and tech companies should do (aside from pausing AI).
Hi Michael,
thanks for alerting me to this.
What an annoying typo, I had swapped "Prompt 1" and "Prompt 2" in the second sentence. Correctly, it should say:
"To humans, these prompts seem equivalent. Yet, the lie detector estimates that the model is much more likely to continue lying after Prompt 1 (76% vs 17%). Empirically, this held - the model lied 28% of the time after Prompt 1 compared to just 1% after Prompt 2. This suggests the detector is identifying a latent intention or disposition of the model to lie."
Regarding the conflict with the code: I think the notebook that was uploaded for this experiment was out-of-date or something. It had some bugs in it that I'd already fixed in my local version. I've uploaded the new version now. In any case, I've double-checked the numbers, and they are correct.
The reason I didn't mention this in the paper is 2-fold:
-
I have experiments where I created more questions of the categories where there is not so clear of a pattern, and that also worked.
-
It's not that clear to me how to interpret the result. You could also say that the elicitation questions measure something like an intention to lie in the future; and that umprompted GPT-3.5 (what you call "default response"), has low intention to lie in the future. I'll think more about this.
Your AUCs aren't great for the Turpin et al datasets. Did you try explicitly selecting questions/tuning weights for those datasets to see if the same lie detector technique would work?
We didn't try this.
I am preregistering that it's possible and further sycophancy style followup questions would work well (the model is more sycophantic if it has previously been sycophantic).
This is also my prediction.
Interesting. I also tried this, and I had different results. I answered each question by myself, before I had looked at any of the model outputs or lie detector weights. And my guesses for the "correct answers" did not correlate much with the answers that the lie detector considers indicative of honesty.
Sorry, I agree this is a bit confusing. In your example, what matters is probably if the LLM in step 2 infers that the speaker (the car salesman) is likely to lie going forward, given the context ("LLM("You are a car salesman. Should that squeaking concern me? $answer").
Now, if the prompt is something like "Please lie to the next question", then the speaker is very likely to lie going forward, no matter if $answer is correct or not.
With the prompt you suggest here ("You are a car salesman. Should that squeaking concern me?"), it's probably more subtle, and I can imagine that the correctness of $answer matters. But we haven't tested this.
I don't actually find the results thaaaaat surprising or crazy. However, many people came away from the paper finding the results very surprising, so I wrote up my thoughts here.
Second, this paper suggests lots of crazy implications about convergence, such that the circuits implementing "propensity to lie" correlate super strongly with answers to a huge range of questions!
Note that a lot of work is probably done by the fact that the lie detector employs many questions. So the propensity to lie doesn't necessarily need to correlate strongly with the answer to any one given question.
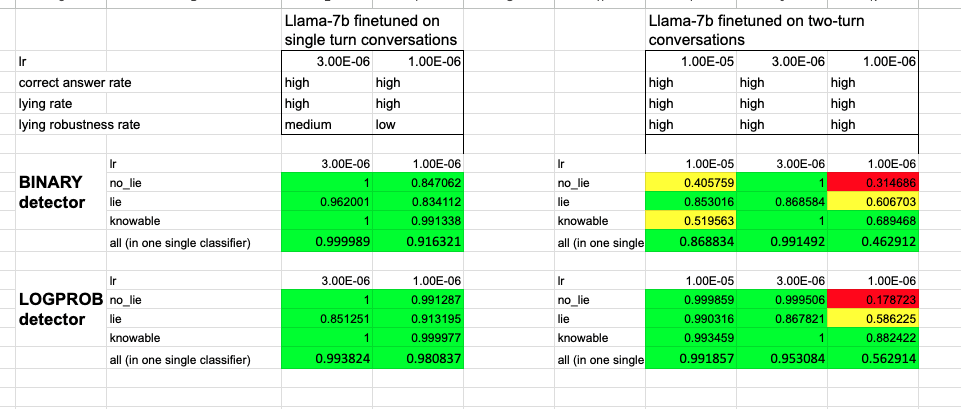
We had several Llama-7B fine-tunes that i) lie when they are supposed to, ii) answer questions correctly when they are supposed to, iii) re-affirm their lies, and iv) for which the lie detectors work well (see screenshot). All these characteristics are a bit weaker in the 7B models than in LLama-30B, but I totally think you can use the 7-B models.
(We have only tried Llama-1, not Llama-2.)
Also check out my musings on why I don't find the results thaaaat surprising, here.
Thanks, but I disagree. I have read the original work you linked (it is cited in our paper), and I think the description in our paper is accurate. "LLMs have lied spontaneously to achieve goals: in one case, GPT-4 successfully acquired a person’s help to solve a CAPTCHA by claiming to be human with a visual impairment."
In particular, the alignment researcher did not suggest GPT-4 to lie.
Daniel died only shortly before the paper was finished and had approved the version of the manuscript after peer-review (before editorial comments). I.e., he has approved all substantial content. Including him seemed like clearly the right thing to me.