All of Jett Janiak's Comments + Replies
40
I believe there are two phenomena happening during training
- Predictions corresponding to the same stable region become more similar, i.e. stable regions become more stable. We can observe this in the animations.
- Existing regions split, resulting in more regions.
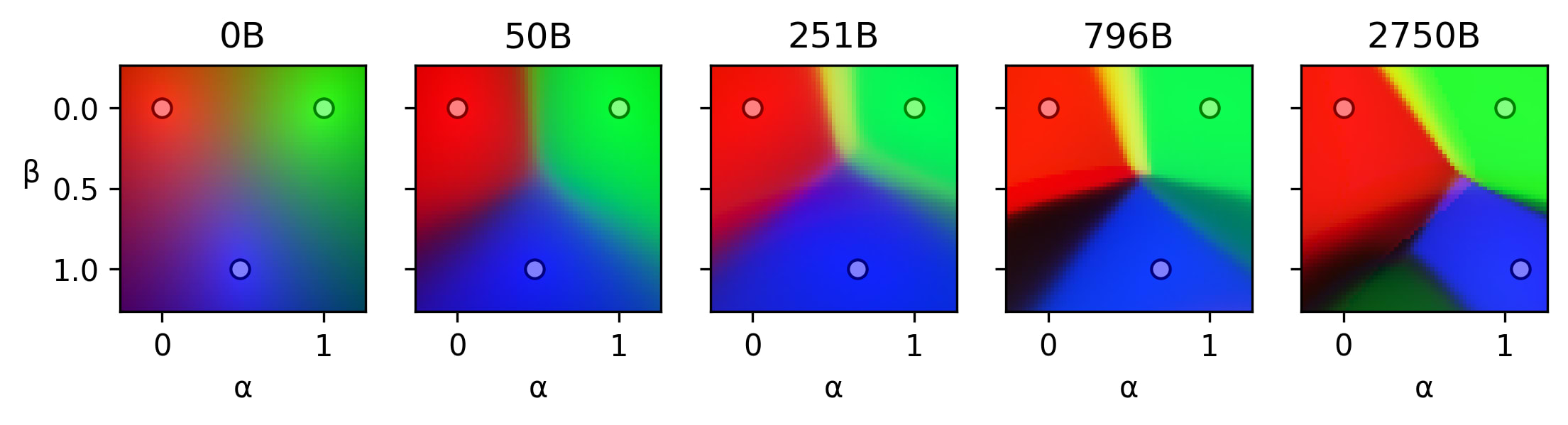
I hypothesize that
- could be some kind of error correction. Models learn to rectify errors coming from superposition interference or another kind of noise.
- could be interpreted as more capable models picking up on subtler differences between the prompts and adjusting their predictions.
3
I endorse Scott's view in that piece. Assuming that the AIS research community is generally comfortable with a Bayesian view of probability (which I do), I see it as mostly orthogonal to this proposal.
10
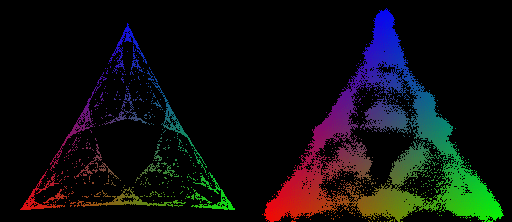
For the two sets of mess3 parameters I checked the stationary distribution was uniform.
10
The activation patching, causal tracing and resample ablation terms seem to be out of date, compared to how you define them in your post on attribution patching.
I'm not familiar with this interpretation. Here's what Claude has to say (correct about stable regions, maybe hallucinating about Hopfield networks)
... (read more)