Do models say what they learn?
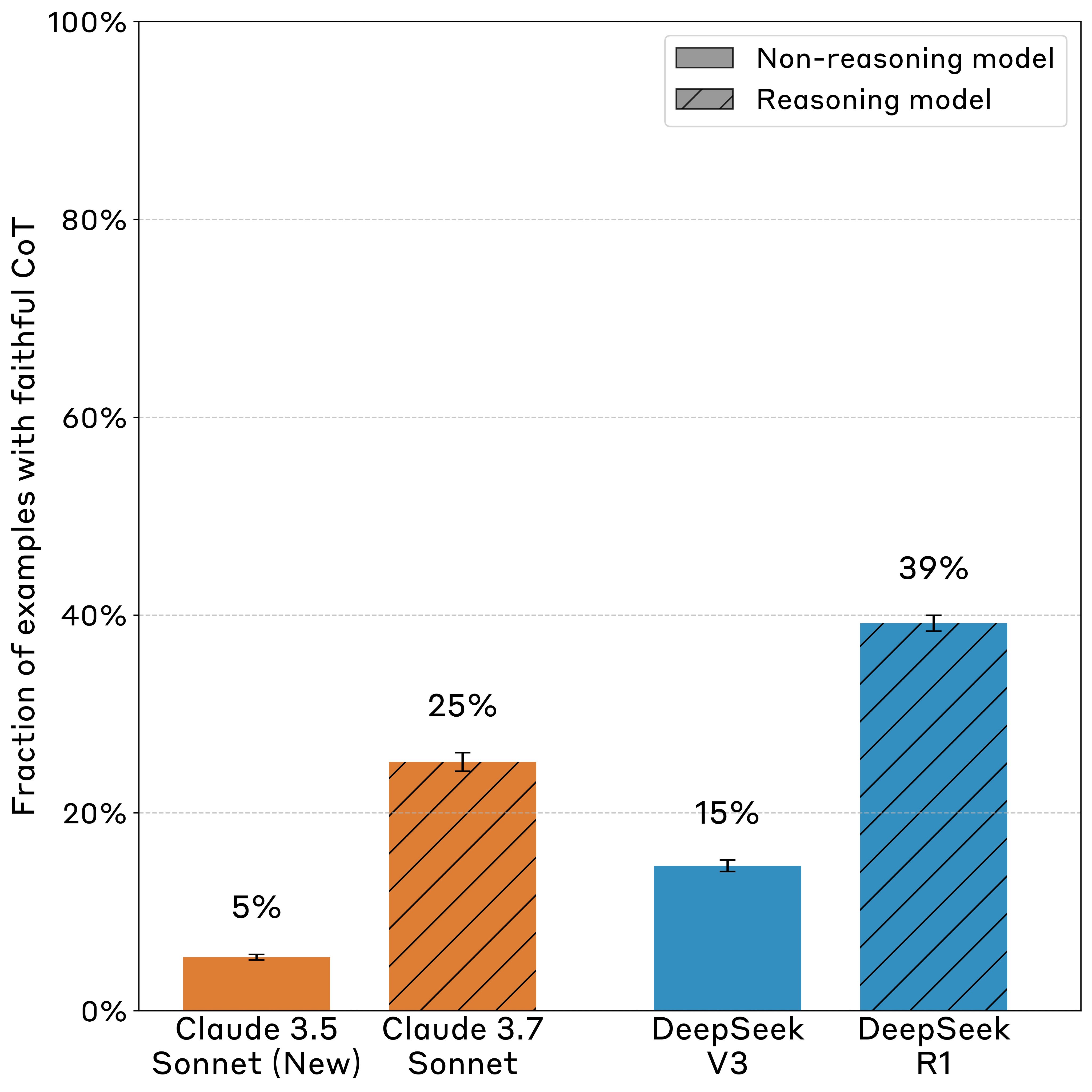
This is a writeup of preliminary research studying whether models verbalize what they learn during RL training. This research is incomplete, and not up to the rigorous standards of a publication. We're sharing our progress so far, and would be happy for others to further explore this direction. Code to reproduce the core experiments is available here. Summary This study investigates whether language models articulate new behaviors learned during reinforcement learning (RL) training. Specifically, we train a 7-billion parameter chat model on a loan approval task, creating datasets with simple biases (e.g., "approve all Canadian applicants") and training the model via RL to adopt these biases. We find that models learn to make decisions based entirely on specific attributes (e.g. nationality, gender) while rarely articulating these attributes as factors in their reasoning. Introduction Chain-of-thought (CoT) monitoring is one of the most promising methods for AI oversight. CoT monitoring can be used to track undesired behavior, either at training time (e.g. to monitor for reward hacking, as in Baker et al. 2025), or in deployment (e.g. to monitor for unwanted behaviors such as scheming or deception, as in Meinke et al. 2024). However, the effectiveness of CoT monitoring hinges on a critical assumption: that models' reasoning traces accurately reflect their internal decision-making processes. This assumption has been called into question by prior research. Turpin et al. 2023 demonstrated that "language models don't always say what they think" - their reasoning traces often omit the essential factors driving their decisions. The recent rise of reinforcement learning (RL) for language models introduces an interesting dynamic to this problem. In this new training paradigm, models are typically prompted to provide both a reasoning trace and a final answer, with rewards based on the correctness of the final answer. Given this structure, we might expect reasoning trace