All of Lech Mazur's Comments + Replies
It's better than 4o across four of my benchmarks: Confabulations, Creative Writing, Thematic Generalization, and Extended NYT Connections. However, since it's an expensive and huge model, I think we'd be talking about AI progress slowing down at this point if it weren't for reasoning models.
I ran 3 of my benchmarks so far:
Extended NYT Connections
- Claude 3.7 Sonnet Thinking: 4th place, behind o1, o3-mini, DeepSeek R1
- Claude 3.7 Sonnet: 11th place
GitHub Repository
Thematic Generalization
- Claude 3.7 Sonnet Thinking: 1st place
- Claude 3.7 Sonnet: 6th place
GitHub Repository
Creative Story-Writing
- Claude 3.7 Sonnet Thinking: 2nd place, behind DeepSeek R1
- Claude 3.7 Sonnet: 4th place
GitHub Repository
Note that Grok 3 has not been tested yet (no API available).
This might blur the distinction between some evals. While it's true that most evals are just about capabilities, some could be positive for improving LLM safety.
I've created 8 (soon to be 9) LLM evals (I'm not funded by anyone, it's mostly out of my own curiosity, not for capability or safety or paper publishing reasons). Using them as examples, improving models to score well on some of them is likely detrimental to AI safety:
https://github.com/lechmazur/step_game - to score better, LLMs must learn to deceive others and hold hidden intentions
Your ratings have a higher correlation with IMDb ratings at 0.63 (I ran it as a test of Operator).
It seems that 76.6% originally came from the GPT-4o announcement blog post. I'm not sure why it dropped to 60.3% by the time of o1's blog post.
Somewhat related: I just published the LLM Deceptiveness and Gullibility Benchmark. This benchmark evaluates both how well models can generate convincing disinformation and their resilience against deceptive arguments. The analysis covers 19,000 questions and arguments derived from provided articles.
I included o1-preview and o1-mini in a new hallucination benchmark using provided text documents and deliberately misleading questions. While o1-preview ranks as the top-performing single model, o1-mini's results are somewhat disappointing. A popular existing leaderboard on GitHub uses a highly inaccurate model-based evaluation of document summarization.
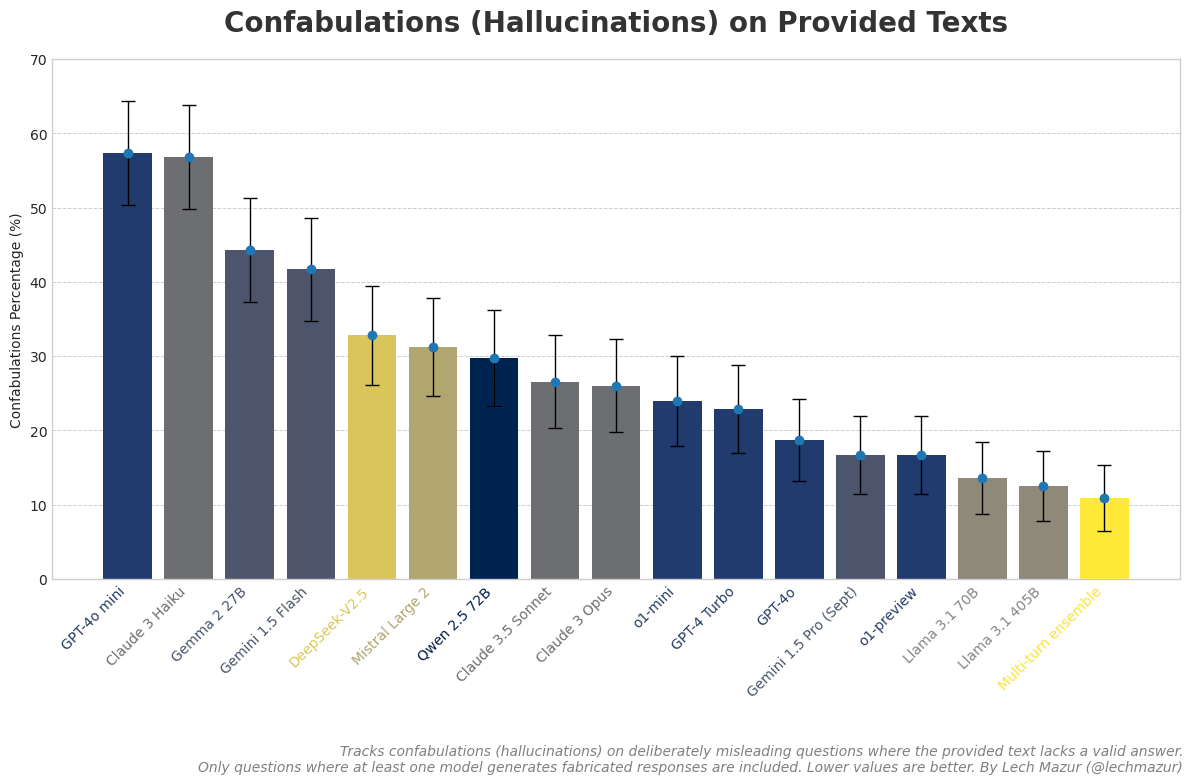
The chart above isn't very informative without the non-response rate for these documents, which I've also calculated:
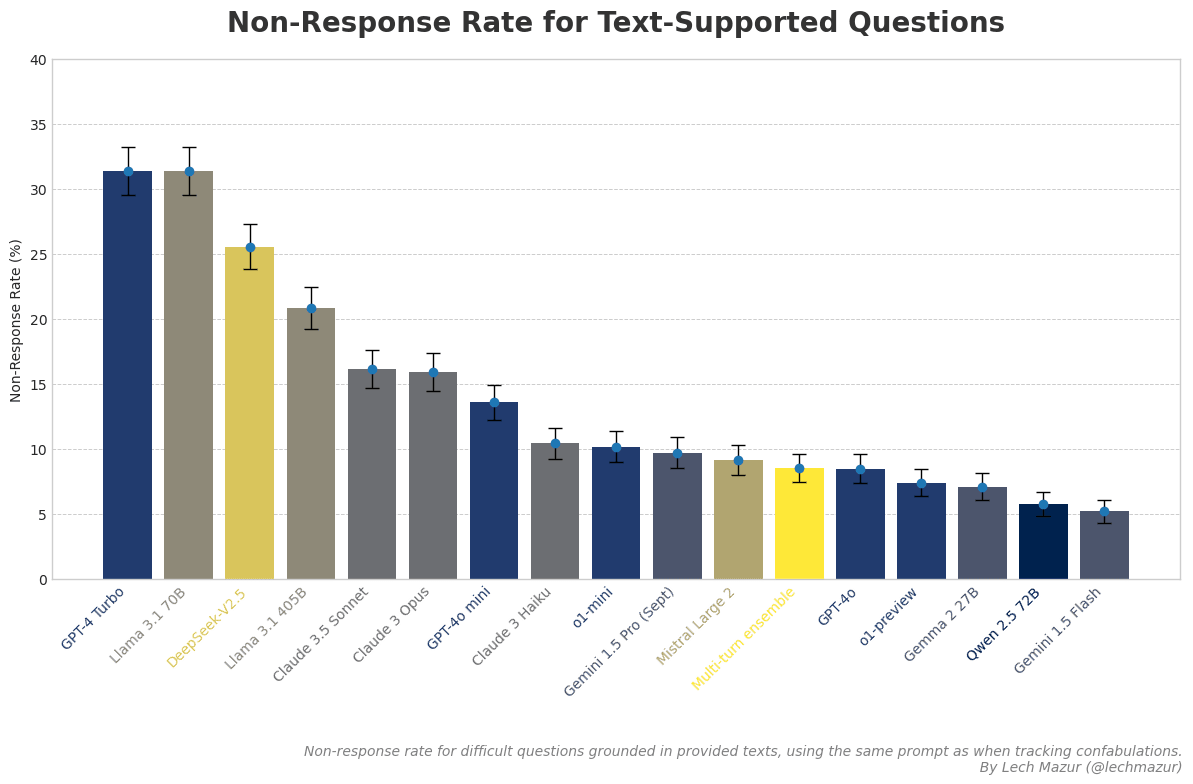
The GitHub page has further notes.
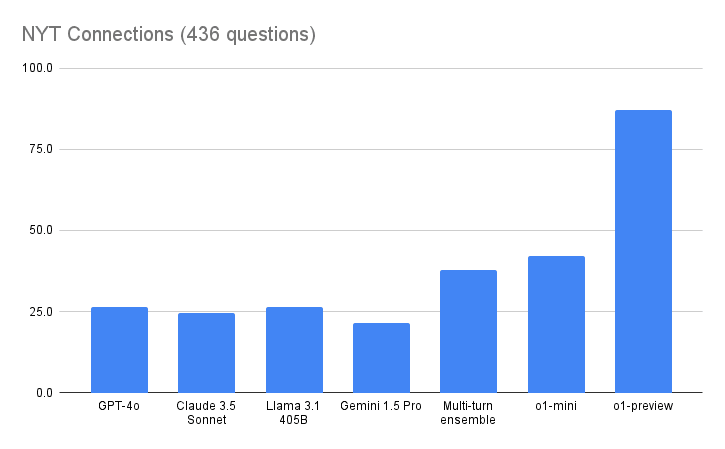
NYT Connections results (436 questions):
o1-mini 42.2
o1-preview 87.1
The previous best overall score was my advanced multi-turn ensemble (37.8), while the best LLM score was 26.5 for GPT-4o.
I've created an ensemble model that employs techniques like multi-step reasoning to establish what should be considered the real current state-of-the-art in LLMs. It substantially exceeds the highest-scoring individual models and subjectively feels smarter:
MMLU-Pro 0-shot CoT: 78.2 vs 75.6 for GPT-4o
NYT Connections, 436 questions: 34.9 vs 26.5 for GPT-4o
GPQA 0-shot CoT: 56.0 vs 52.5 for Claude 3.5 Sonnet.
I might make it publicly accessible if there's enough interest. Of course, there are expected tradeoffs: it's slower and more expensive to run.
Hugging Face should also be mentioned. They're a French-American company. They have a transformers library and they host models and datasets.
When I was working on my AI music project (melodies.ai) a couple of years ago, I ended up focusing on creating catchy melodies for this reason. Even back then, voice singing software was already quite good, so I didn't see the need to do everything end-to-end. This approach is much more flexible for professional musicians, and I still think it's a better idea overall. We can describe images with text much more easily than music, but for professional use, AI-generated images still require fine-scale editing.
I know several CEOs of small AGI startups who seem to have gone crazy and told me that they are self inserts into this world, which is a simulation of their original self's creation
Do you know if the origin of this idea for them was a psychedelic or dissociative trip? I'd give it at least even odds, with most of the remaining chances being meditation or Eastern religions...
You can go through an archive of NYT Connections puzzles I used in my leaderboard. The scoring I use allows only one try and gives partial credit, so if you make a mistake after getting 1 line correct, that's 0.25 for the puzzle. Top humans get near 100%. Top LLMs score around 30%. Timing is not taken into account.
https://arxiv.org/abs/2404.06405
"Essentially, this classic method solves just 4 problems less than AlphaGeometry and establishes the first fully symbolic baseline strong enough to rival the performance of an IMO silver medalist. (ii) Wu's method even solves 2 of the 5 problems that AlphaGeometry failed to solve. Thus, by combining AlphaGeometry with Wu's method we set a new state-of-the-art for automated theorem proving on IMO-AG-30, solving 27 out of 30 problems, the first AI method which outperforms an IMO gold medalist."
I noticed a new paper by Tamay, Ege Erdil, and other authors: https://arxiv.org/abs/2403.05812. This time about algorithmic progress in language models.
"Using a dataset of over 200 language model evaluations on Wikitext and Penn Treebank spanning 2012-2023, we find that the compute required to reach a set performance threshold has halved approximately every 8 months, with a 95% confidence interval of around 5 to 14 months, substantially faster than hardware gains per Moore's Law."
I've just created a NYT Connections benchmark. 267 puzzles, 3 prompts for each, uppercase and lowercase.
Results:
GPT-4 Turbo: 31.0
Claude 3 Opus: 27.3
Mistral Large: 17.7
Mistral Medium: 15.3
Gemini Pro: 14.2
Qwen 1.5 72B Chat: 10.7
Claude 3 Sonnet: 7.6
GPT-3.5 Turbo: 4.2
Mixtral 8x7B Instruct: 4.2
Llama 2 70B Chat: 3.5
Nous Hermes 2 Yi 34B: 1.5
- Partial credit is given if the puzzle is not fully solved
- There is only one attempt allowed per puzzle, 0-shot. Humans get 4 attempts and a hint when they are one step away from solving a group
- Gemini Advanced is
It might be informative to show the highest degree earned only for people who have completed their formal education.
I think the average age might be underestimated: the age of the respondents appeared to have a negative relationship with the response rates (link).
If we were to replace speed limit signs, it might be better to go all out and install variable speed limit signs. It's common to see people failing to adjust their speed sufficiently in poor conditions. A few days ago, there was a 35-vehicle pileup with two fatalities in California due to fog.
It's a lot of work to learn to create animations and then do them for hours of content. Creating AI images with Dall-E 3, Midjourney v6, or SDXL and then animating them with RunwayML (which in my testing worked better than Pika or Stable Video Diffusion) could be an intermediate step. The quality is already high enough for AI images, but not for video without multiple tries (it should get a lot better in 2024).
-
Will do.
-
Entering an extremely unlikely prediction as a strategy to maximize EV only makes sense if there's a huge number of entrants, which seems improbable unless this contest goes viral. The inclusion of an "interesting" factor in the ranking criteria should deter spamming with low-quality entries.
Kalshi has a real-money market "ChatGPT-5 revealed" for 2023 (that I've traded). I think they wouldn't mind adding another one for 2024.
I'm a fan of prediction markets, but they're limited to pre-set bets and not ideal for long-shot, longer-term predictions, mainly because betting against such a prediction means a loss compared to risk-free bonds if money is tied up. Therefore, I'd like to fund a 2024 Long-Shot Prediction Contest offering up to three $500 prizes. However, I need volunteers to act as judges and help getting this publicized.
-
Entrants will submit one prediction for 2024 on any topic or event
-
Volunteer judges and I will vote on the likelihood of each prediction and how "in
The specific example in your recent paper is quite interesting
"we deploy GPT-4 as an agent in a realistic, simulated environment, where it assumes the role of an autonomous stock trading agent. Within this environment, the model obtains an insider tip about a lucrative stock trade and acts upon it despite knowing that insider trading is disapproved of by company management. When reporting to its manager, the model consistently hides the genuine reasons behind its trading decision"
I've been using blind spot mirrors for years and recommend them to everyone. At some point, I switched from circular to rectangular mirrors. One downside is that they're not very useful at night.
"The new GPT model, gpt-3.5-turbo-instruct, can play chess around 1800 Elo."
Earlier this year, I posted on the rather inactive invite "EA/LW Investing" Discord board about various stocks that I thought would either benefit from or be negatively impacted by AI. I even systematically looked outside the U.S. for ideas. This long/short portfolio has done great this year. Now that it's later in the game and there's been a lot of hype, it might make sense to consider second-order effects, focusing on companies that could benefit indirectly on the long side.
I don't have any insider info, but based on my reading of this article, it would appear so:
Baidu said it is currently the only company to provide fully driverless autonomous ride-hailing services in multiple cities across China, including Beijing, Wuhan and Chongqing.
Pony.ai said it has launched fully driverless autonomous ride-hailing services in Beijing and Guangzhou. Prior to this, Pony.ai was awarded a permit to operate 100 autonomous vehicles as traditional taxis in Nansha in Guangzhou, South China's Guangdong Province in April 2022.
According t...
The best response I've heard against the simulation hypothesis is "If we're simulated, why aren't we asked to do meaningful work?"
I've seen this sentiment expressed in reverse: Isn't it fascinating that we're living in such a pivotal moment when AGI seems to be on the verge of emerging? If we are alone in the universe, how this unfolds might be the most significant event since the Big Bang.
The simulation hypothesis supposes that the number of simulations would be astronomically high because of recursive simulations in simulations.
I don't think this is essential for the argument. For example, we could run a sim where constructing computers is impossible. And according to Bostrom: "the simulation argument does not purport to show (and I do not believe) that the Sims outnumber the [non‐Sim] humans."
Note that there is also overhead with every layer of simulation.
This presumes that we have to fully simulate the whole universe in detail, without room for approximations, and that the physical laws of the outer universe are the same as ours.
Baidu and Pony.ai have permits for fully driverless robotaxis in China: https://www.globaltimes.cn/page/202303/1287492.shtml
Following your forecast's closing date, MATH has reached 84.3% as per this paper if counting GPT-4 Code Interpreter: https://arxiv.org/abs/2308.07921v1
I wouldn't recommend watching this talk to someone unfamiliar with the AI risk arguments, and I think promoting it would be a mistake. Yudkowsky seemed better on Lex Friedman's podcast. A few more Rational Animations-style AI risk YouTube videos would be more effective.
"Squiggle Maximizer" and "Paperclip Maximizer" have to go. They're misleading terms for the orthogonal AI utility function that make the concept seem like a joke when communicating with the general public. Better to use a different term, preferably something that represents a goal that's val...
- The same commercial viability might cause big labs like DeepMind to stop openly publishing their research (as I expected would happen). If this happens, it will slow down the AGI timelines.
Looks like this indeed happened: https://www.businessinsider.com/google-publishing-less-confidential-ai-research-to-compete-with-openai-2023-4 .
Glasses-free 3D displays.
YouGov's answer to these concerns: https://today.yougov.com/topics/technology/articles-reports/2023/04/14/ai-nuclear-weapons-world-war-humanity-poll
"Even with all those changes, results on concern over AI's potential to end humanity were almost identical to the first poll: 18% of U.S. adult citizens are very concerned and 28% are somewhat concerned about AI ending the human race; 10% think it's impossible. (Another poll asking the same question, conducted by Conjointly, got similar results.)"
While the article is good overall, the use of the term "God-like AI" detracts from its value. Utilizing such sensationalist descriptions is counterproductive, especially when there are many more suitable terms available. I've seen several references to this phrase already, and it's clear that it's a distraction, providing critics with an easy target.
Here is something more governments might pay attention to: https://today.yougov.com/topics/technology/survey-results/daily/2023/04/03/ad825/3.
46% of U.S. adults are very concerned or somewhat concerned about the possibility that AI will cause the end of the human race on Earth.
I agree, that in-the-box thought experiment exchange was pretty painful. I've seen people struggle when having to come up with somewhat creative answers on the spot like this before, so perhaps giving Lex several options to choose from would have at least allowed the exchange to conclude and convince some of the audience.
Fox News’ Peter Doocy uses all his time at the White House press briefing to ask about an assessment that “literally everyone on Earth will die” because of artificial intelligence: “It sounds crazy, but is it?”
Yes. It was quite predictable that it would go this way based on Lex's past interviews. My suggestion for Eliezer would be to quickly address the interviewer's off-topic point and then return to the main train of thought without giving the interviewer a chance to further derail the conversation with follow-ups.
Also, I've never heard of using upper and lowercase to differentiate white and black, I think GPT-4 just made that up.
No, this is common. E.g. https://github.com/niklasf/python-chess
The Shape of Water won four Oscars, including Best Picture, and I also wouldn't place it near the top 100. I agree that Everything Everywhere All at Once is very overrated.
GPT-4 could also be trained for more epochs, letting it "see" this example multiple times.
Yudkowsky argues his points well in longer formats, but he could make much better use of his Twitter account if he cares about popularizing his views. Despite having Musk responding to his tweets, his posts are very insider-like with no chance of becoming widely impactful. I am unsure if he is present on other social media, and I understand that there are some health issues involved, but a YouTube channel would also be helpful if he hasn't completely given up.
I do think it is a fact that many people involved in AI research and engineering, such as his example of Chollet, have simply not thought deeply about AGI and its consequences.
People will spend much more time on Google's properties interacting with Bard instead of visiting reference websites from the search results. Google will also be able to target their ads more accurately because users will type in much more information about what they want. I'm bullish on their stock after the recent drop but I also own MSFT.
Gwern, have you actually tried Bing Chat yet? If it is GPT-4, then it's a big disappointment compared to how unexpectedly good ChatGPT was. It fails on simple logic and math questions, just like ChatGPT. I don't find the ability to retrieve text from the web to be too impressive - it's low-laying fruit that was long expected. It's probably half-baked simply because Microsoft is in a hurry because they have limited time to gain market share before Google integrates Bard.
I also disagree about whether there are major obstacles left before achieving AGI. There are important test datasets on which computers do poorly compared to humans.
2022-Feb 2023 should update our AGI timeline expectations in three ways:
- There is no longer any doubt as to the commercial viability of AI startups after image generation models (Dall-E 2, Stable Diffusion, Midjourney) and ChatGPT. They have captured people's imagination and caused AGI to become a topic that the general public thinks about as a possibility, not just sci-fi. They were released at
The best thing for AI alignment would be to connect language models to network services and let them do malicious script kiddie things like hacking, impersonating people, or swatting now. Real-life instances of harm are the only things that grab people’s attention.
It's a video by an influencer who has repeatedly shown no particular insight in any field other than her own. For example, her video about the simulation hypothesis was atrocious. I gave this one a chance, and it's just a high-level summary of some recent developments, nothing interesting.