All of mhampton's Comments + Replies
I agree that mass unemployment may spark policy change, but why do you see that change as being relevant to misalignment vs. specific to automation?
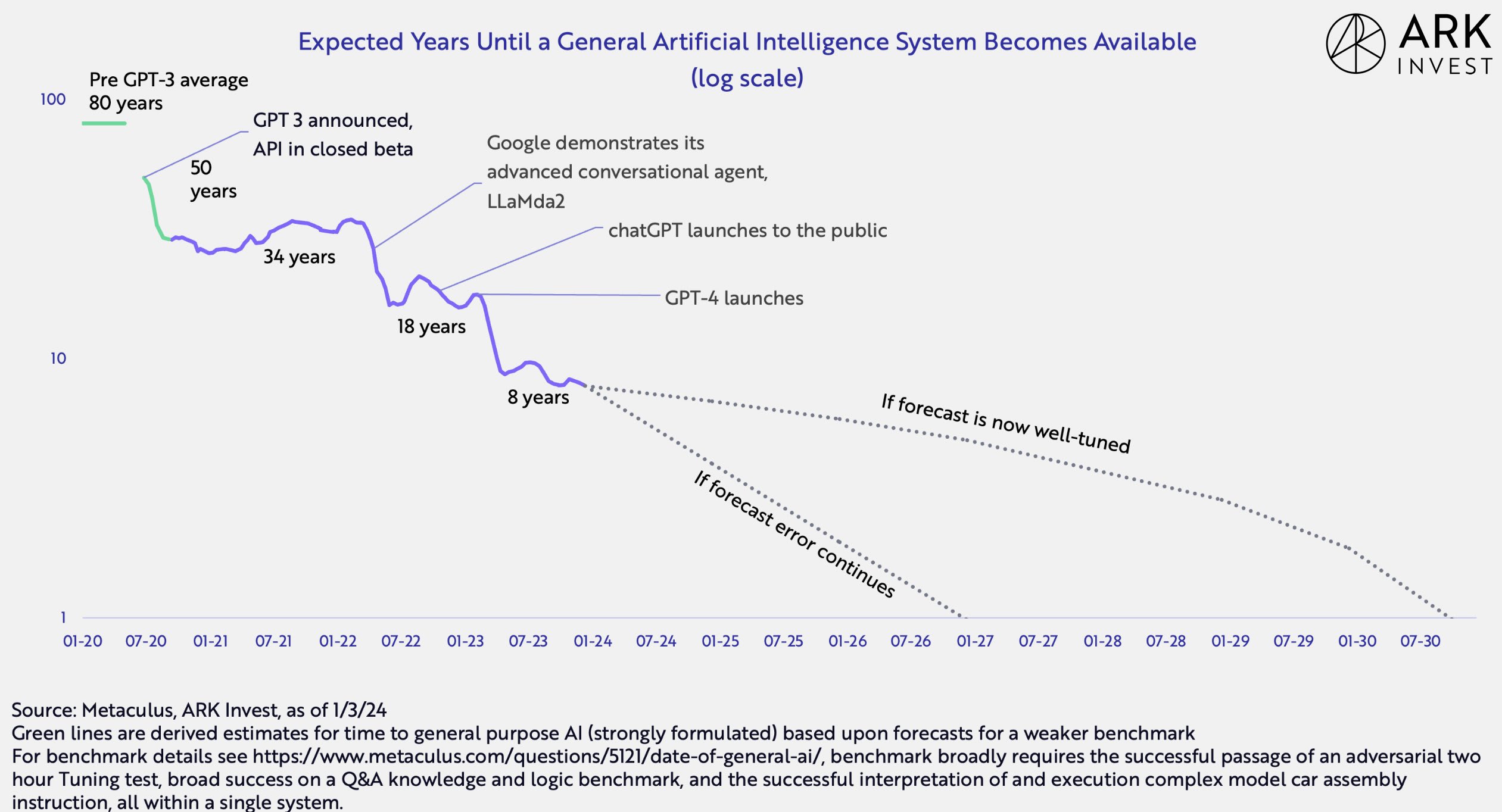
AGI timelines post-GPT-3 exhibit reverse Hofstadter’s law: AI advances quicker than predicted, even when taking into account reverse Hofstadter’s law.
https://x.com/wintonARK/status/1742979090725101983/photo/1
Makes sense. What probability do you place on this? It would require solving alignment, a second AI being created before the first can create a singleton, and then the misaligned AI choosing this kind of blackmail over other possible tactics. If the blackmail involves sentient simulations (as is sometimes suggested, although not in your comment), it would seem that the misaligned AI would have to solve the hard problem of consciousness and be able to prove this to the other AI (not a valid blackmail if the simulations are not known to be sentient).
Thanks for your comment.
The misuse risks seem much more important, both as real risks, and in their saliency to ordinary people.
I agree that it may be easier to persuade the general public about misuse risks and that these risks are likely to occur if we achieve intent alignment, but in terms of assessing the relative probability: "If we solve alignment" is a significant "if." I take it you view solving intent alignment as not all that unlikely? If so, why? Specifically, how do you expect we will figure out how to prevent deceptive alignment and goal...
This is a comprehensive, nuanced, and well-written post. A few questions:
How likely do you think it is that, under a Harris administration, AI labs will successfully lobby Democrats to kill safety-oriented policies, as happened with SB 1047 on the state level? Even if Harris is on net better than Trump this could greatly reduce the expected value of her presidency from an x-risk perspective.
Related to the above, is it fair to say that under either party, there will need to be advocacy/lobbying for safety-focused policies on AI? If so, how do you make trade...
Your reasoning makes sense with regards to how a more authoritarian government would make it more likely that we can avoid x-risk, but how do you weigh that against the possibility that an AGI that is intent-aligned (but willing to accept harmful commands) would be more likely to create s-risks in the hands of an authoritarian state, as the post author has alluded to?
Also, what do you make of the author's comment below?
...
- In general, the public seems pretty bought-in on AI risk being a real issue and is interested in regulation. Having democratic instincts wo
Great post. I agree with almost all of this. What I am uncertain about is the idea that AI existential risk is a rights violation under the most strict understanding of libertarianism.
As another commenter has suggested, we can't claim that any externality creates rights to stop or punish a given behavior, or libertarianism turns into safetyism.[1] If we take the Non-Aggression Principle as a common standard for a hardline libertarian view of what harms give you a right to restitution or retaliation, it seems that x-risk does not fit this de...
Hi, I'm interested in attending but a bit unclear about the date and time based on how it is listed. Is the spring ACX meetup taking place starting at 2:30 p.m. on May 11?
If I understand your section "Avoid Being Seen As 'Not Serious'" correctly -- that the reason policymakers don't want to support "wierd" policies is not because they're concerned about their reputation but rather that they just are too busy to do something that probably won't work -- this seems like it should meaningfully change how many people outside of politics think about advocating for AI policy. It was outside my model anyway.
The question to me is, what, if anything, is the path to change if we don't get a crisis before it is too late? Or, do we just have to place our chips on that scenario and wait for it to happen?