All of MichaelDickens's Comments + Replies
Is Claude "more aligned" than Llama?
Anthropic seems to be the AI company that cares the most about AI risk, and Meta cares the least. If Anthropic is doing more alignment research than Meta, do the results of that research visibly show up in the behavior of Claude vs. Llama?
I am not sure how you would test this. The first thing that comes to mind is to test how easily different LLMs can be tricked into doing things they were trained not to do, but I don't know if that's a great example of an "alignment failure". You could test model deception but you'd nee...
Hmm I wonder if this is why so many April Fools posts have >200 upvotes. April Fools Day in cahoots with itself?
isn't your squiggle model talking about whether racing is good, rather than whether unilaterally pausing is good?
Yes the model is more about racing than about pausing but I thought it was applicable here. My thinking was that there is a spectrum of development speed with "completely pause" on one end and "race as fast as possible" on the other. Pushing more toward the "pause" side of the spectrum has the ~opposite effect as pushing toward the "race" side.
I wish you'd try modeling this with more granularity than "is alignment hard" or whatever
- I've n
I think it would probably be bad for the US to unilaterally force all US AI developers to pause if they didn't simultaneously somehow slow down non-US development.
It seems to me that to believe this, you have to believe all of these four things are true:
- Solving AI alignment is basically easy
- Non-US frontier AI developers are not interested in safety
- Non-US frontier AI developers will quickly catch up to the US
- If US developers slow down, then non-US developers are very unlikely to also slow down—either voluntarily, or because the US strong-arms them i
That's kind-of what happened with the anti-nuclear movement, but it ended up doing lots of harm because the things that could be stopped were the good ones!
The global stockpile of nuclear weapons is down 6x since its peak in 1986. Hard to attribute causality but if the anti-nuclear movement played a part in that, then I'd say it was net positive.
(My guess is it's more attributable to the collapse of the Soviet Union than to anything else, but the anti-nuclear movement probably still played some nonzero role)
Yeah I actually agree with that, I don't think it was sufficient, I just think it was pretty good. I wrote the comment too quickly without thinking about my wording.
I feel kind of silly about supporting PauseAI. Doing ML research, or writing long fancy policy reports feels high status. Public protests feel low status. I would rather not be seen publicly advocating for doing something low-status. I suspect a good number of other people feel the same way.
(I do in fact support PauseAI US, and I have defended it publicly because I think it's important to do so, but it makes me feel silly whenever I do.)
That's not the only reason why people don't endorse PauseAI, but I think it's an important reason that should be mentioned.
Well -- I'm gonna speak broadly -- if you look at the history of PauseAI, they are marked by belief that the measures proposed by others are insufficient for Actually Stopping AI -- for instance the kind of policy measures proposed by people working at AI companies isn't enough; that the kind of measures proposed by people funded by OpenPhil are often not enough; and so on.
They are correct as far as I can tell. Can you identify a policy measure proposed by an AI company or an OpenPhil-funded org that you think would be sufficient to stop unsafe AI devel...
If you look at the kind of claims that PauseAI makes in their risks page, you might believe that some of them seem exaggerated, or that PauseAI is simply throwing all the negative things they can find about AI into big list to make it see bad. If you think that credibility is important to the effort to pause AI, then PauseAI might seem very careless about truth in a way that could backfire.
A couple notes on this:
- AFAICT PauseAI US does not do the thing you describe.
- I've looked at a good amount of research on protest effectiveness. There are many obser
B. "Pausing AI" is indeed more popular than PauseAI, but it's not clearly possible to make a more popular version of PauseAI that actually does anything; any such organization will have strategy/priorities/asks/comms that alienate many of the people who think "yeah I support pausing AI."
This strikes me as a very strange claim. You're essentially saying, even if a general policy is widely supported, it's practically impossible to implement any specific version of that policy? Why would that be true?
For example I think a better alternative to "nobody fund...
I don't think you could refute it. I believe you could construct a binary polynomial function that gives the correct answer to every example.
For example it is difficult to reconcile the cases of 3, 12, and 19 using a reasonable-looking function, but you could solve all three cases by defining E E as the left-associative binary operation
f(x, y) = -1/9 x^2 + 32/9 x - 22/9 + y
You could technically say Google is a marketing company, but Google's ability to sell search ads doesn't depend on being good at marketing in the traditional sense. It's not like Google is writing ads themselves and selling the ad copy to companies.
I believe the correct way to do this, at least in theory, is to simply have bets denominated in the risk-free rate—and if anyone wants more risk, they can use leverage to simultaneously invest in equities and prediction markets.
Right now I don't know if it's possible to use margin loans to invest in prediction markets.
I looked through ChatGPT again and I figured out that I did in fact do it wrong. I found Deep Research by going to the "Explore GPTs" button in the top right, which AFAICT searches through custom modules made by 3rd parties. The OpenAI-brand Deep Research is accessed by clicking the "Deep research" button below the chat input text box.
I don't really get the point in releasing a report that explicitly assumes x-risk doesn't happen. Seems to me that x-risk is the only outcome worth thinking about given the current state of the AI safety field (i.e. given how little funding goes to x-risk). Extinction is so catastrophically worse than any other outcome* that more "normal" problems aren't worth spending time on.
I don't mean this as a strong criticism of Epoch, more that I just don't understand their worldview at all.
*except S-risks but Epoch isn't doing anything related to those AFAIK
Working through a model of the future in a better-understood hypothetical refines gears applicable outside the hypothetical. Exploratory engineering for example is about designing machines that can't be currently built in practice and often never will be worthwhile to build as designed. It still gives a sense of what's possible.
(Attributing value to steps of a useful activity is not always practical. Research is like that, very useful that it's happening overall, but individual efforts are hard to judge, and so acting on attempts to judge them risks goodhart curse.)
for example, by having bets denominated in S&P 500 or other stock portfolios rather than $s
Bets should be denominated in the risk-free rate. Prediction markets should invest traders' money into T-bills and pay back the winnings plus interest.
I believe that should be a good enough incentive to make prediction markets a good investment if you can find positive-EV bets that aren't perfectly correlated with equities (or other risky assets).
(For Polymarket the situation is a bit more complicated because it uses crypto.)
Thanks, this is helpful! After reading this post I bought ChatGPT Plus and tried a question on Deep Research:
Please find literature reviews / meta-analyses on the best intensity at which to train HIIT (i.e. maximum sustainable speed vs. leaving some in the tank)
I got much worse results than you did:
- ChatGPT misunderstood my question. Its response answered the question "is HIIT better than MICT for improving fitness".
- Even allowing that we're talking about HIIT vs. MICT: I was previously aware of 3 meta-analyses on that question. ChatGPT cited none of
[Time Value of Money] The Yes people are betting that, later this year, their counterparties (the No betters) will want cash (to bet on other markets), and so will sell out of their No positions at a higher price.
How does this strategy compare to shorting bonds? Both have the same payoff structure (they make money if the discount rate goes up) but it's not clear to me which is a better deal. I suppose it depends on whether you expect Polymarket investors to have especially high demand for cash.
I'm glad to hear that! I often don't hear much response to my essays so it's good to know you've read some of them :)
I don't have a mistakes page but last year I wrote a one-off post of things I've changed my mind on.
I have a few potential criticisms of this paper. I think my criticisms are probably wrong and the paper's conclusion is right, but I'll just put them out there:
- Nearly half the tasks in the benchmark take 1 to 30 seconds (the ones from the SWAA set). According to the fitted task time <> P(success) curve, most tested LLMs should be able to complete those with high probability, so they don't provide much independent signal.
- However, I expect task time <> P(success) curve would look largely the same if you excluded the SWAA tasks.
- SWAA tasks t
I think this criticism is wrong—if it were true, the across-dataset correlation between time and LLM-difficulty should be higher than the within-dataset correlation, but from eyeballing Figure 4 (page 10), it looks like it's not higher (or at least not much).
It is much higher. I'm not sure how/if I can post images of the graph here, but the R^2 for SWAA only is 0.27, HCAST only is 0.48, and RE-bench only is 0.01.
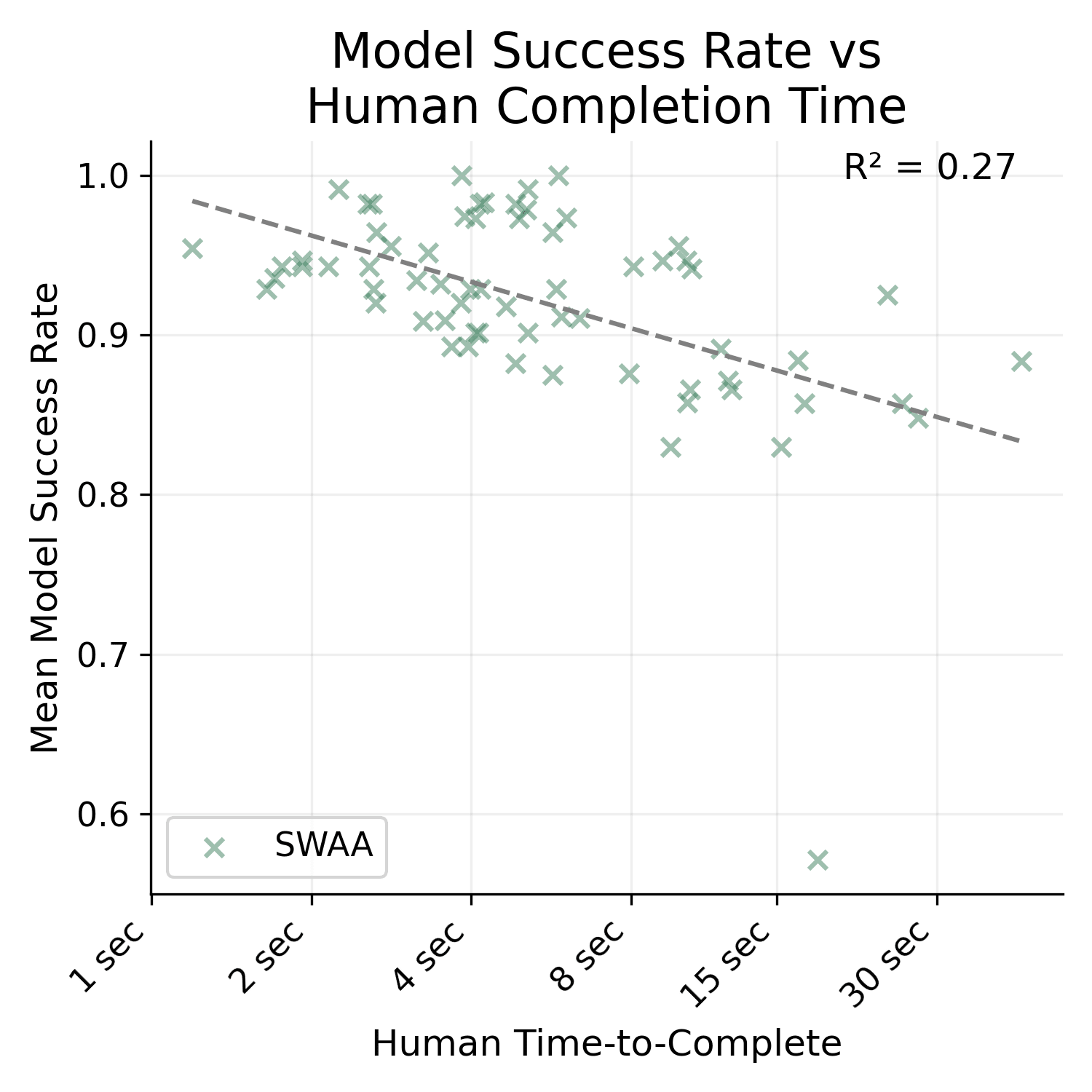
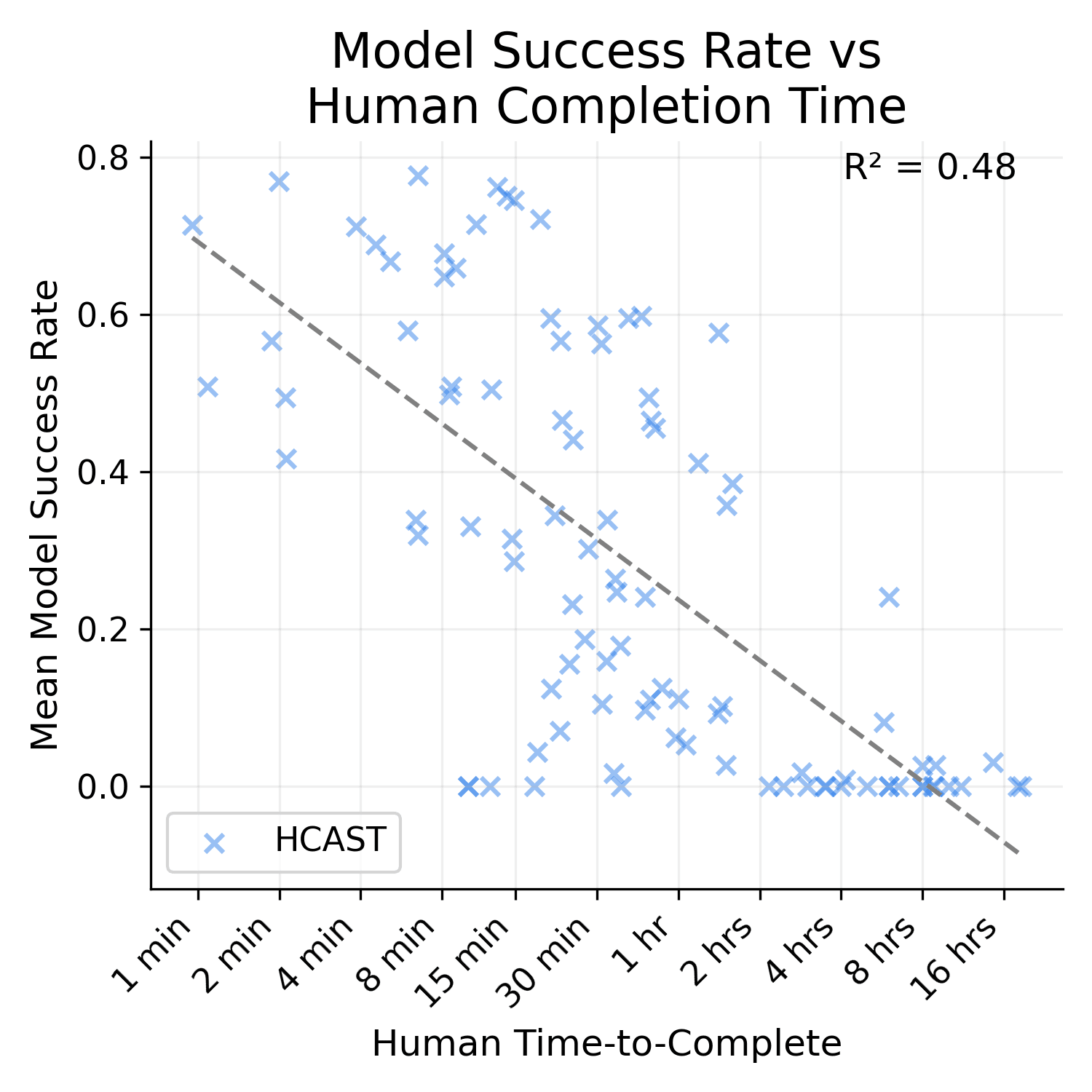
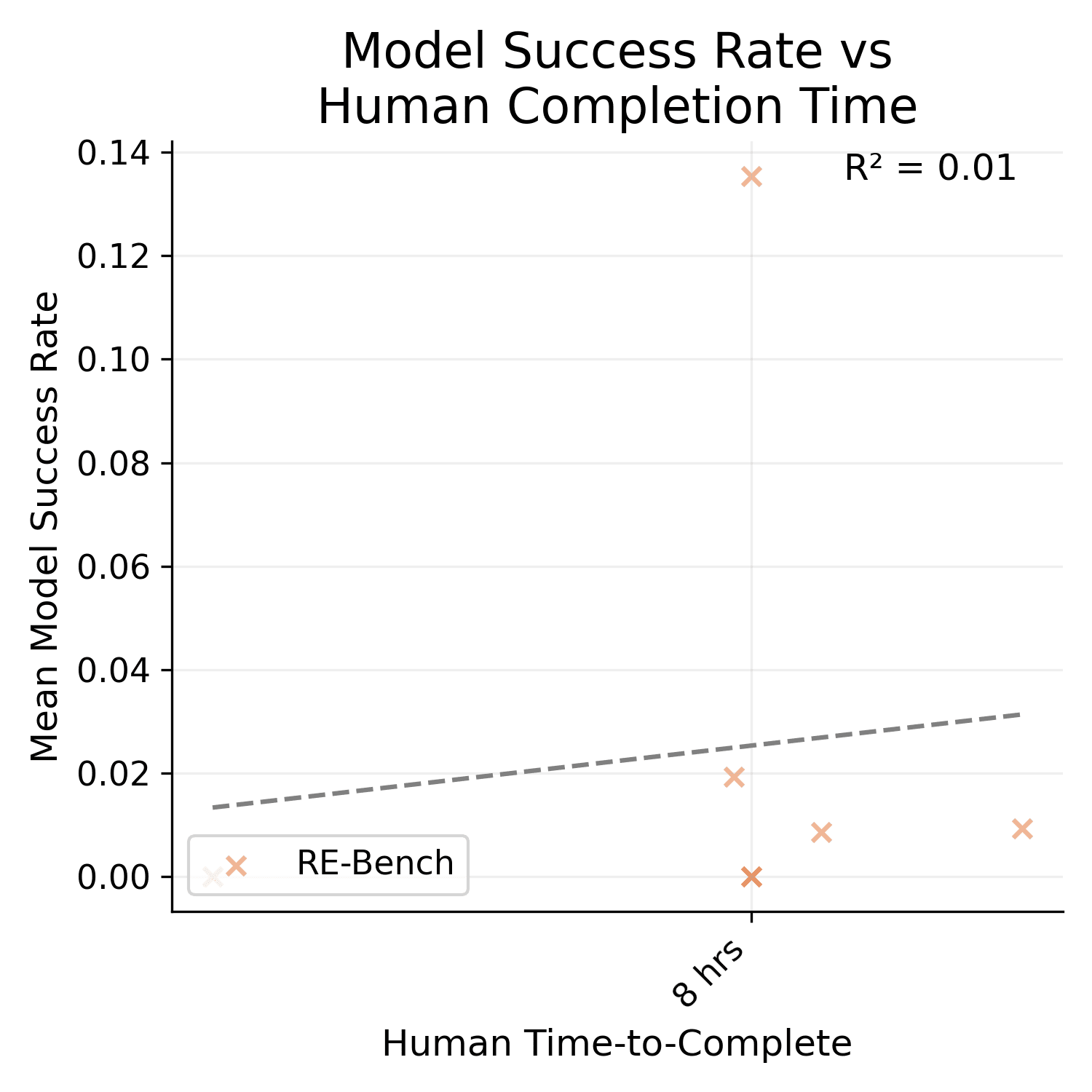
Also, HCAST R^2 goes down to 0.41 if you exclude the 21/97 data points where the human time source is an estimate. I'm not really sure why t...
Why do you think this narrows the distribution?
I can see an argument for why, tell me if this is what you're thinking–
The biggest reason why LLM paradigm might never reach AI takeoff is that LLMs can only complete short-term tasks, and can't maintain coherence over longer time scales (e.g. if an LLM writes something long, it will often start contradicting itself). And intuitively it seems that scaling up LLMs hasn't fixed this problem. However, this paper shows that LLMs have been getting better at longer-term tasks, so LLMs probably will scale to AGI.
A few miscellaneous thoughts:
- I agree with Dagon that the most straightforward solution is simply to sell your equity as soon as it vests. If you don't do anything else then I think at least you should do that—it's a good idea just on the basis of diversification, not even considering conflicts of interest.
- I think you should be willing to take quite a large loss to divest. In a blog post, I estimated that for an investor with normal-ish risk aversion, it's worth paying ~4% per year to avoid the concentration risk of holding a single mega-cap stock (so yo
This is the belief of basically everyone running a major AGI lab. Obviously all but one of them must be mistaken, but it's natural that they would all share the same delusion.
I agree with this description and I don't think this is sane behavior.
Actions speak louder than words, and their actions are far less sane than these words.
For example, if Demis regularly lies awake at night worrying about how the thing he's building could kill everyone, why is he still putting so much more effort into building it than into making it safe?
I was familiar enough to recognize that it was an edit of something I had seen before, but not familiar enough to remember what the original was
I'm really not convinced that public markets do reliably move in the predictable (downward) direction in response to "bad news" (wars, coups, pandemics, etc).
Also, market movements are hard to detect. How much would Trump violating a court order decrease the total (time-discounted) future value of the US economy? Probably less than 5%? And what is the probability that he violates a court order? Maybe 40%? So the market should move <2%, and evidence about this potential event so far has come in slowly instead of at a single dramatic moment so this <2% drop could have been spread over multiple weeks.
If I'm allowed to psychoanalyze funders rather than discussing anything at the object level, I'd speculate that funders like evals because:
- If you funded the creation of an eval, you can point to a concrete thing you did. Compare to funding theoretical technical research, which has a high chance of producing no tangible outputs; or funding policy work, which has a high chance of not resulting in any policy change. (Streetlight Effect.)
- AI companies like evals, and funders seem to like doing things AI companies like, for various reasons including (a) the t
I don't know what the regulatory plan is, I was just referring to this poll, which I didn't read in full, I just read the title. Reading it now, it's not so much a plan as a vision, and it's not so much "Musk's vision" as it is a viewpoint (that the poll claims is associated with Musk) in favor of regulating the risks of AI. Which is very different from JD Vance's position; Vance's position is closer to the one that does not poll well.
I guess I'm expressing doubt about the viability of wise or cautious AI strategies, given our new e/acc world order, in which everyone who can, is sprinting uninhibitedly towards superintelligence.
e/acc does not poll well and there is widespread popular support for regulating AI (see AIPI polls). If the current government favors minimal regulations, that's evidence that an AI safety candidate is more likely to succeed, not less.
(Although I'm not sure that follows because I think the non-notkilleveryonism variety of AI safety is more popular. Also Musk's regulatory plan is polling well and I'm not sure if it differs from e.g. Vance's plan.)
Also Musk's regulatory plan is polling well
What plan are you referring to? Is this something AI safety specific?
If you publicly commit to something, taking down the written text does not constitute a de-commitment. Violating a prior commitment is unethical regardless of whether the text of the commitment is still on your website.
(Not that there's any mechanism to hold Google to its commitments, or that these commitments ever meant anything—Google was always going to do whatever it wanted anyway.)
Claude 3.5 Sonnet is a mid-sized model that cost a few $10M's to train
I don't get this, if frontier(ish) models cost $10M–$100M, why is Nvidia's projected revenue more like $1T–$10T? Is the market projecting 100,000x growth in spending on frontier models within the next few years? I would have guessed more like 100x–1000x growth but at least one of my numbers must be wrong. (Or maybe they're all wrong by ~1 OOM?)
This is actually a crazy big effect size? Preventing ~10–50% of a cold for taking a few pills a day seems like a great deal to me.
Don't push the frontier of regulations. Obviously this is basically saying that Anthropic should stop making money and therefore stop existing. The more nuanced version is that for Anthropic to justify its existence, each time it pushes the frontier of capabilities should be earned by substantial progress on the other three points.
I think I have a stronger position on this than you do. I don't think Anthropic should push the frontier of capabilities, even given the tradeoff it faces.
If their argument is "we know arms races are bad, but we have to accele...
If lysine is your problem but you don't want to eat beans, you can also buy lysine supplements.
I primarily use a weird ergonomic keyboard (the Kinesis Advantage 2) with custom key bindings. But my laptop keyboard has normal key bindings, so my "normal keyboard" muscle memory still works.
On Linux Mint with Cinnamon, you can do this in system settings by going to Keyboard -> Layouts -> Options -> Caps Lock behavior. (You can also put that line in a shell script and set the script to run at startup.)
I use a Kinesis Advantage keyboard with the keys rebound to look like this (apologies for my poor graphic design skills):
https://i.imgur.com/Mv9FI7a.png
{kind=link}
- Caps Lock is rebound to Backspace and Backspace is rebound to Shift.
- Right Shift is rebound to Ctrl + Alt + Super, which I use as a command prefix for window manager commands.
- "custom macro" uses the keyboard's built-in macro feature to send a sequence of four keypresses (Alt-G Ctrl-`), which I use as a prefix for some Emacs commands.
- By default, the keyboard has two backslash (\) keys. I use the OS keybo
- There were two different clauses, one about malaria and the other about chickens. "Helping people is really important" clearly applies to the malaria clause, and there's a modified version of the statement ("helping animals is really important") that applies to the chickens clause. I think writing it that way was an acceptable compromise to simplify the language and it's pretty obvious to me what it was supposed to mean.
- "We should help more rather than less, with no bounds/limitations" is not a necessary claim. It's only necessary to claim "we should help more rather than less if we are currently helping at an extremely low level".
MIRI's communications strategy update published in May explained what they were planning on working on. I emailed them a month or so ago and they said they are continuing to work on the things in that blog post. They are the sorts of things that can take longer than a year so I'm not surprised that they haven't released anything substantial in the way of comms this year.
That's only true if a single GPU (or small number of GPUs) is sufficient to build a superintelligence, right? I expect it to take many years to go from "it's possible to build superintelligence with a huge multi-billion-dollar project" and "it's possible to build superintelligence on a few consumer GPUs". (Unless of course someone does build a superintelligence which then figures out how to make GPUs many orders of magnitude cheaper, but at that point it's moot.)
I don't think controlling compute would be qualitatively harder than controlling, say, pseudoephedrine.
(I think it would be harder, but not qualitatively harder—the same sorts of strategies would work.)
Also, I don't feel that this article adequately addressed the downside of SA that it accelerates an arms race. SA is only favored when alignment is easy with high probability and you're confident that you will win the arms race, and you're confident that it's better for you to win than for the other guy[1], and you're talking about a specific kind of alignment where an "aligned" AI doesn't necessarily behave ethically, it just does what its creator intends.
[1] How likely is a US-controlled (or, more accurately, Sam Altman/Dario Amodei/Mark Zuckerberg-contr...
Cooperative Development (CD) is favored when alignment is easy and timelines are longer. [...]
Strategic Advantage (SA) is more favored when alignment is easy but timelines are short (under 5 years)
I somewhat disagree with this. CD is favored when alignment is easy with extremely high probability. A moratorium is better given even a modest probability that alignment is hard, because the downside to misalignment is so much larger than the downside to a moratorium.[1] The same goes for SA—it's only favored when you are extremely confident about alignment +...
Also, I don't feel that this article adequately addressed the downside of SA that it accelerates an arms race. SA is only favored when alignment is easy with high probability and you're confident that you will win the arms race, and you're confident that it's better for you to win than for the other guy[1], and you're talking about a specific kind of alignment where an "aligned" AI doesn't necessarily behave ethically, it just does what its creator intends.
[1] How likely is a US-controlled (or, more accurately, Sam Altman/Dario Amodei/Mark Zuckerberg-contr...
- I was asking a descriptive question here, not a normative one. Guilt by association, even if weak, is a very commonly used form of argument, and so I would expect it to be in used in this case.
I intended my answer to be descriptive. EAs generally avoid making weak arguments (or at least I like to think we do).
I will attempt to answer a few of these.
- Why has EV made many moves in the direction of decentralizing EA, rather than in the direction of centralizing it?
Power within EA is currently highly centralized. It seems very likely that the correct amount of centralization is less than the current amount.
- Why, as an organization aiming to ensure the health of a community that is majority male and includes many people of color, does the CEA Community Health team consist of seven white women, no men, and no people of color?
This sounds like a rhetorical qu...
Thank you for writing about your experiences! I really like reading these posts.
How big an issue do you think the time constraints were? For example, how much better a job could you have done if all the recommenders got twice as much time? And what would it take to set things up so the recommenders could have twice as much time?
Do you think a 3-state dark mode selector is better than a 1-state (where "auto" is the only state)? My website is 1-state, on the assumption that auto will work for almost everyone and it lets me skip the UI clutter of having a lighting toggle that most people won't use.
Also, I don't know if the site has been updated but it looks to me like turntrout.com's two modes aren't dark and light, they're auto and light. When I set Firefox's appearance to dark or auto, turntrout.com's dark mode appears dark, but when I set Firefox to light, turntrout.com appears l...
Do you think a 3-state dark mode selector is better than a 1-state (where “auto” is the only state)? My website is 1-state, on the assumption that auto will work for almost everyone and it lets me skip the UI clutter of having a lighting toggle that most people won’t use.
Gwern discusses this on his “Design Graveyard” page:
...Auto-dark mode: a good idea but “readers are why we can’t have nice things”.
OSes/browsers have defined a ‘global dark mode’ toggle the reader can set if they want dark mode everywhere, and this is available to a web page; if you are
OP did the work to collect these emails and put them into a post. When people do work for you, you shouldn't punish them by giving them even more work.
Thanks, that's useful info!
I thought you could post images by dragging and dropping files into the comment box, I seem to recall doing that in the past, but now it doesn't seem to work for me. Maybe that only works for top-level posts?