All of Mo Putera's Comments + Replies
Probably worth noting that there's lots of frames to pick from, of which you've discussed two: question, ideology, project, obligation, passion, central purpose, etc.
Scott is often considered a digressive or even “astoundingly verbose” writer.
This made me realise that as a reader I care about, not so much "information & ideas per word" (roughly speaking), but "per unit of effort reading". I'm reminded of Jason Crawford on why he finds Scott's writing good:
Most writing on topics as abstract and technical as his struggles just not to be dry; it takes effort to focus, and I need energy to read them. Scott’s writing flows so well that it somehow generates its own energy, like some sort of perpetual motion machine.
My fa...
Chinchilla scaling finally seems to be slowing
Interesting, any pointers to further reading?
The idea that Chinchilla scaling might be slowing comes from the fact that we've seen a bunch of delays and disappointments in the next generation of frontier models.
GPT 4.5 was expensive and it got yanked. We're not hearing rumors about how amazing GPT 5 is. Grok 3 scaled up and saw some improvement, but nothing that gave it an overwhelming advantage. Gemini 2.5 is solid but not transformative.
Nearly all the gains we've seen recently come from reasoning, which is comparatively easy to train into models. For example, DeepScaleR is a 1.8B parameter local mo...
Balioc's A taxonomy of bullshit jobs has a category called Worthy Work Made Bullshit which resonated with me most of all:
...Worthy Work Made Bullshit is perhaps the trickiest and most controversial category, but as far as I’m concerned it’s one of the most important. This is meant to cover jobs where you’re doing something that is obviously and directly worthwhile…at least in theory…but the structure of the job, and the institutional demands that are imposed on you, turn your work into bullshit.
The conceptual archetype here is the Soviet ti
It's the exponential map that's more fundamental than either e or 1/e. Alon Amit's essay is a nice pedagogical piece on this.
Thank you, sounds somewhat plausible to me too. For others' benefit, here's the chart from davidad's linked tweet:

What is the current best understanding of why o3 and o4-mini hallucinate more than o1? I just got round to checking out the OpenAI o3 and o4-mini System Card and in section 3.3 (on hallucinations) OA noted that
o3 tends to make more claims overall, leading to more accurate claims as well as more inaccurate/hallucinated claims. While this effect appears minor in the SimpleQA results (0.51 for o3 vs 0.44 for o1), it is more pronounced in the PersonQA evaluation (0.33 vs 0.16). More research is needed to understand the cause of these results.
as of ...
This is one potential explanation:
- o3 has some sort of internal feature like "Goodhart to the objective"/"play in easy mode".
- o3's RL post-training environments have opportunities for reward hacks.
- o3 discovers and exploits those opportunities.
- RL rewards it for that, reinforcing the "Goodharting" feature.
- This leads to specification-hack-y behavior generalizing out of distribution, to e. g. freeform conversations. It ends up e. g. really wanting to sell its interlocutor on what it's peddling, so it deliberately[1] confabulates plausible authoritative-soun
Importantly, I value every intermediate organism in this chain
An interesting and personally relevant variant of this is if the approval only goes one direction in time. This happened to me: 2025!Mo is vastly different from 2010!Mo in large part due to step-changes in my "coming of age" story that would've left 2010!Mo horrified (indeed he tried to fight the step-changes for months) but that 2025!Mo retrospectively fully endorses post-reflective equilibrium.
So when I read something like Anders Sandberg's description here
...There is a kind of standard arg
Predictive coding research shows our brains use both bottom-up signals (intuition) and top-down predictions (systematization) in a dynamic interplay . These are integrated parts of how our brains process information. One person can excel at both.
Link is broken, can you reshare?
I liked Gwern's remarks at the end of your link:
...Successful applications to pixel art tend to inject real-world knowledge, such as through models pretrained on FFHQ, or focus on tasks involving ‘throwing away’ information rather than generating it, such as style transfer of pixel art styles.
Thus, if I wanted to make a Pokemon GAN, I would not attempt to train on solely pixel art scraped from a few games. I would instead start with a large dataset of animals, perhaps from ImageNet or iNaturalist or Wikipedia, real or fictional, and grab all Pokemon art of an
Thomas Kwa's Effectiveness is a Conjunction of Multipliers seems relevant. He factors multipliers into judgment (sort of maps to your 'direction', or research taste I guess), ambition (which counts hard work as a driver), and risk appetite. Some domains seem to reward hard work superlinearly, probably worth looking out for those. You shouldn't skip leg day because you'd miss out on multipliers (that phrase came from SBF of all people). Also finding multipliers is hard and information-gathering is particularly valuable when it helps you find a multiplier an...
Saving mathematician Robert Ghrist's tweet here for my own future reference re: AI x math:
...workflow of the past 24 hours...
* start a convo w/GPT-o3 about math research idea [X]
* it gives 7 good potential ideas; pick one & ask to develop
* feed -o3 output to gemini-2.5-pro; it finds errors & writes feedback
* paste feedback into -o3 and say asses & respond
* paste response into gemini; it finds more problems
* iterate until convergence
* feed the consensus idea w/detailed report to grok-3
* grok finds gaping error, fixes by taking things in diffe
These quotes from When ChatGPT Broke an Entire Field: An Oral History stood out to me:
...On November 30, 2022, OpenAI launched its experimental chatbot. ChatGPT hit the NLP community like an asteroid.
IZ BELTAGY (lead research scientist, Allen Institute for AI; chief scientist and co-founder, SpiffyAI): In a day, a lot of the problems that a large percentage of researchers were working on — they just disappeared. ...
R. THOMAS MCCOY: It’s reasonably common for a specific research project to get scooped or be eliminated by someone else’s similar thing.
Wow. I knew academics were behind / out of the loop / etc. but this surprised me. I imagine these researchers had at least heard about GPT2 and GPT3 and the scaling laws papers; I wonder what they thought of them at the time. I wonder what they think now about what they thought at the time.
I see, I stand corrected then.
Not really. Robert Anton Wilson's description is more on-point:
...Let me differentiate between scientific method and the neurology of the individual scientist. Scientific method has always depended on feedback [or flip-flopping as the Tsarists call it]; I therefore consider it the highest form of group intelligence thus far evolved on this backward planet. The individual scientist seems a different animal entirely. The ones I've met seem as passionate, and hence as egotistic and prejudiced, as painters, ballerinas or even, God save the mark, novelists. My hop
These quoted passages made me curious what cooperation-focused folks like David Manheim and Ivan Vendrov and others think of this essay (I'm not plugged into the "cooperation scene" at all so I'm probably missing out on most thinkers / commenters):
...We proceed from the core assumption that stable human coexistence (a precondition for flourishing), particularly in diverse societies, is made possible not by achieving rational convergence on values, but by relying on practical social technologies – like conventions, norms, and institutions – to manage
I was initially excited by the raw intelligence of o3, but after using it for mini-literature reviews of quantitative info (which I do a fair bit of for work) I was repeatedly boggled by how often it would just hallucinate numbers like "14% market penetration", followed immediately by linked citations to papers/reports etc which did not in fact contain "14%" or whatever; in fact this happened for the first 3 sources I spot-checked for a single response, after which I deemed it pointless to continue. I thought RAG was supposed to make this a solved problem? None of the previous SOTA models I tried out had this issue.
Thought it would be useful to pull out your plot and surrounding text, which seemed cruxy:
...At first glance, the job of a scientist might seem like it leans very heavily on abstract reasoning... In such a world, AIs would greatly accelerate R&D before AIs are broadly deployed across the economy to take over more common jobs, such as retail workers, real estate agents, or IT professionals. In short, AIs would “first automate science, then automate everything else.”
But this picture is likely wrong. In reality, most R&D jobs require much more than abstr
I think this essay is going to be one I frequently recommend to others over the coming years, thanks for writing it.
But in the end, deep in the heart of any bureaucracy, the process is about responsibility and the ways to avoid it. It's not an efficiency measure, it’s an accountability management technique.
This vaguely reminded me of what Ivan Vendrov wrote in Metrics, Cowardice, and Mistrust. Ivan began by noting that "companies optimizing for simple engagement metrics aren’t even being economically rational... so why don't they?" It's not because "these ...
This, in the end, was what motivated me to reintroduce "Critique Claude"/"Guide Gemini"/"Oversight o3".[3] That is, a secondary model call that occurs on context summary whose job it is to provide hints if the model seems stuck, and which is given a system prompt specifically for this purpose. It can be told to look for telltale signs of common fail-states and attempt to address then, and can even be given "meta" prompting about how to direct the other model.
Funnily enough this reminded me of pair programming.
I do think it'd be useful for the rest of us if you put them in a comment. :)
(FWIW I resonated with your motivation, but also think your suggestions fail on the practical grounds jenn mentioned, and would hence on net harm the people you intend to help.)
Terry Tao recently wrote a nice series of toots on Mathstodon that reminded me of what Bill Thurston said:
...1. What is it that mathematicians accomplish?
There are many issues buried in this question, which I have tried to phrase in a way that does not presuppose the nature of the answer.
It would not be good to start, for example, with the question
How do mathematicians prove theorems?
This question introduces an interesting topic, but to start with it would be to project two hidden assumptions: (1) that there is uniform, objective and firmly establ
Out of curiosity, can you share a link to Gemini 2.5 Pro's response?
re: your last remark, FWIW I think a lot of those writings you've seen were probably intuition-pumped by this parable of Eliezer's, to which I consider titotal's pushback the most persuasive.
I saw someone who was worried that AI was gonna cause real economic trouble soon by replacing travel agents. But the advent of the internet made travel agents completely unnecessary, and it still only wiped out half the travel agent jobs. The number of travel agents has stayed roughly the same since 2008!
This reminds me of Patrick McKenzie's tweet thread:
...Technology-driven widespread unemployment ("the robots will take all the jobs") is, like wizards who fly spaceships, a fun premise for science fiction but difficult to find examples for in economic h
One subsubgenre of writing I like is the stress-testing of a field's cutting-edge methods by applying it to another field, and seeing how much knowledge and insight the methods recapitulate and also what else we learn from the exercise. Sometimes this takes the form of parables, like Scott Alexander's story of the benevolent aliens trying to understand Earth's global economy from orbit and intervening with crude methods (like materialising a billion barrels of oil on the White House lawn to solve a recession hypothesised to be caused by an oil shortage) to...
I'm not sure about Friston's stuff to be honest.
But Watts lists a whole bunch of papers in support of the blindsight idea, contra Seth's claim — to quote Watts:
- "In fact, the nonconscious mind usually works so well on its own that it actually employs a gatekeeper in the anterious cingulate cortex to do nothing but prevent the conscious self from interfering in daily operations"
- footnotes: Matsumoto, K., and K. Tanaka. 2004. Conflict and Cognitive Control. Science 303: 969-970; 113 Kerns, J.G., et al. 2004. Anterior Cingulate Conflict Monitoring
Thanks, is there anything you can point me to for further reading, whether by you or others?
Peter Watts is working with Neill Blomkamp to adapt his novel Blindsight into an 8-10-episode series:
...“I can at least say the project exists, now: I’m about to start writing an episodic treatment for an 8-10-episode series adaptation of my novel Blindsight.
“Neill and I have had a long and tortured history with that property. When he first expressed interest, the rights were tied up with a third party. We almost made it work regardless; Neill was initially interested in doing a movie that wasn’t set in the Blindsight universe at all, but which merely u
Blindsight was very well written but based on a premise that I think is importantly and dangerously wrong. That premise is that consciousness (in the sense of cognitive self-awareness) is not important for complex cognition.
This is the opposite of true, and a failure to recognize this is why people are predicting fantastic tool AI that doesn't become self-aware and goal-directed.
The proof won't fit in the margin unfortunately. To just gesture in that direction: it is possible to do complex general cognition without being able to think about one's self and one's cognition. It is much easier to do complex general cognition if the system is able to think about itself and its own thoughts.
There's a lot of fun stuff in Anders Sandberg's 1999 paper The Physics of Information Processing Superobjects: Daily Life Among the Jupiter Brains. One particularly vivid detail was (essentially) how the square-cube law imposes itself upon Jupiter brain architecture by forcing >99.9% of volume to be comprised of comms links between compute nodes, even after assuming a "small-world" network structure allowing sparse connectivity between arbitrarily chosen nodes by having them be connected by a short series of intermediary links with only 1% of links bein...
Venkatesh Rao's recent newsletter article Terms of Centaur Service caught my eye for his professed joy of AI-assisted writing, both nonfiction and fiction:
...In the last couple of weeks, I’ve gotten into a groove with AI-assisted writing, as you may have noticed, and I am really enjoying it. ... The AI element in my writing has gotten serious, and I think is here to stay. ...
On the writing side, when I have a productive prompting session, not only does the output feel information dense for the audience, it feels information dense for me.
An example of th
There's a version of this that might make sense to you, at least if what Scott Alexander wrote here resonates:
...I’m an expert on Nietzsche (I’ve read some of his books), but not a world-leading expert (I didn’t understand them). And one of the parts I didn’t understand was the psychological appeal of all this. So you’re Caesar, you’re an amazing general, and you totally wipe the floor with the Gauls. You’re a glorious military genius and will be celebrated forever in song. So . . . what? Is beating other people an end in itself? I don’t know, I guess this is
In my corner of the world, anyone who hears "A4" thinks of this:

The OECD working paper Miracle or Myth? Assessing the macroeconomic productivity gains from Artificial Intelligence, published quite recently (Nov 2024), is strange to skim-read: its authors estimate just 0.24-0.62 percentage points annual aggregate TFP growth (0.36-0.93 pp. for labour productivity) over a 10-year horizon, depending on scenario, using a "novel micro-to-macro framework" that combines "existing estimates of micro-level performance gains with evidence on the exposure of activities to AI and likely future adoption rates, relying on a multi-sec...
(Not a take, just pulling out infographics and quotes for future reference from the new DeepMind paper outlining their approach to technical AGI safety and security)
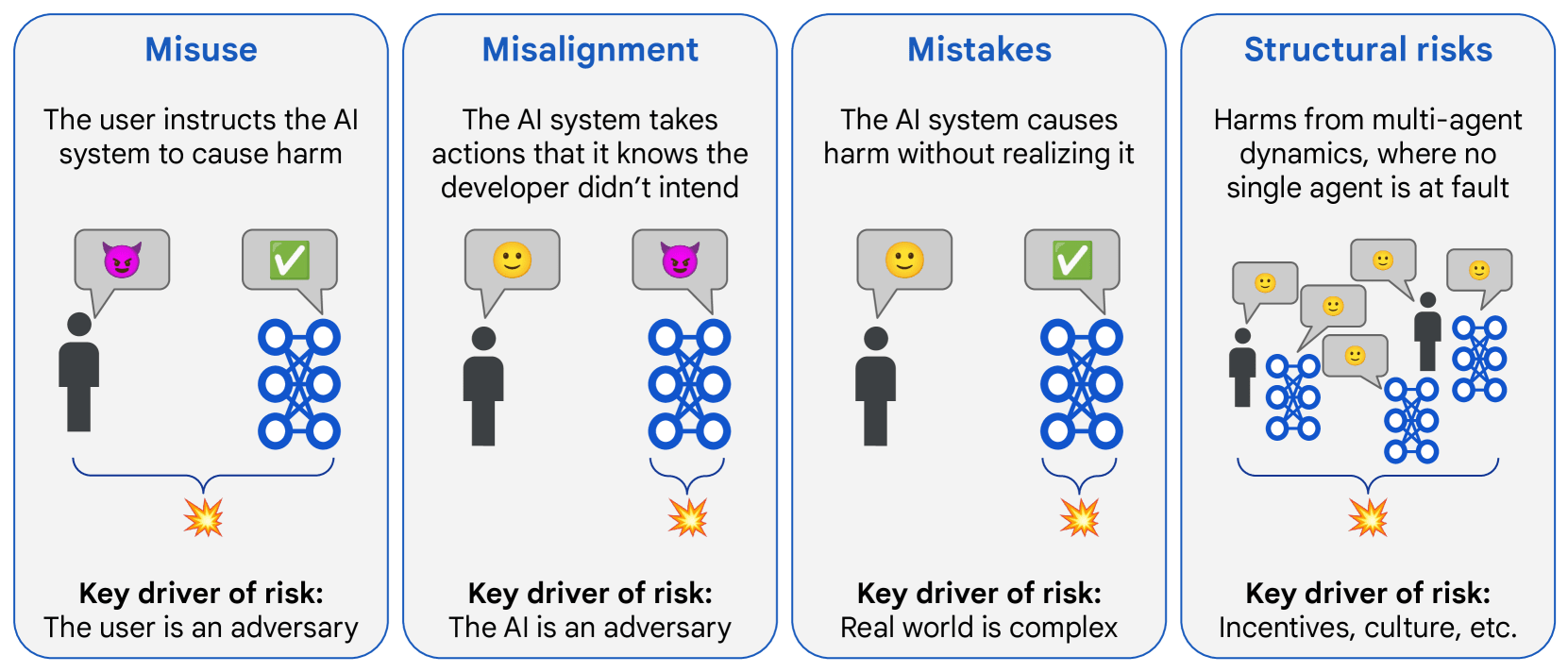
Overview of risk areas, grouped by factors that drive differences in mitigation approaches:
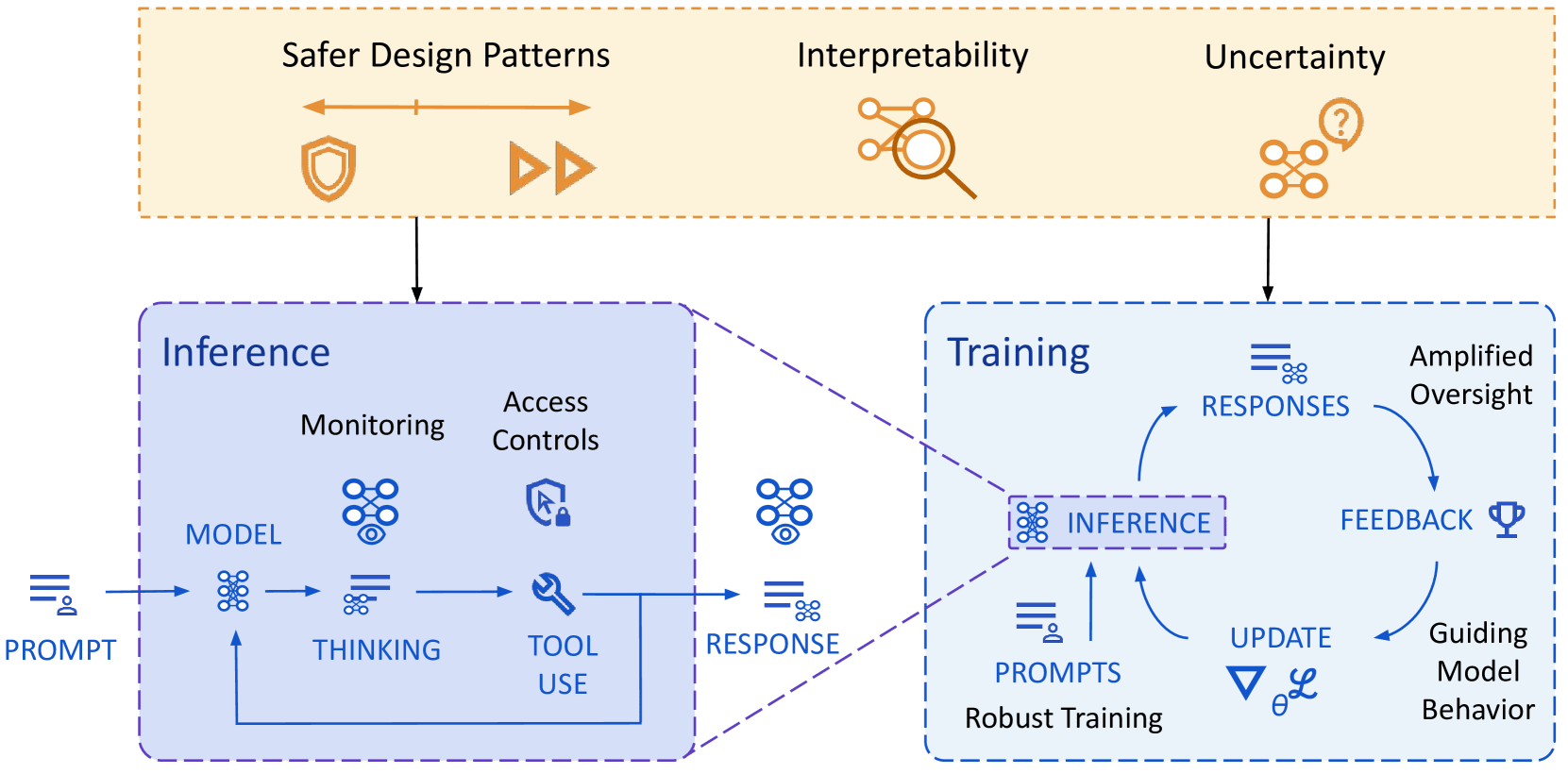
Overview of their approach to mitigating misalignment:
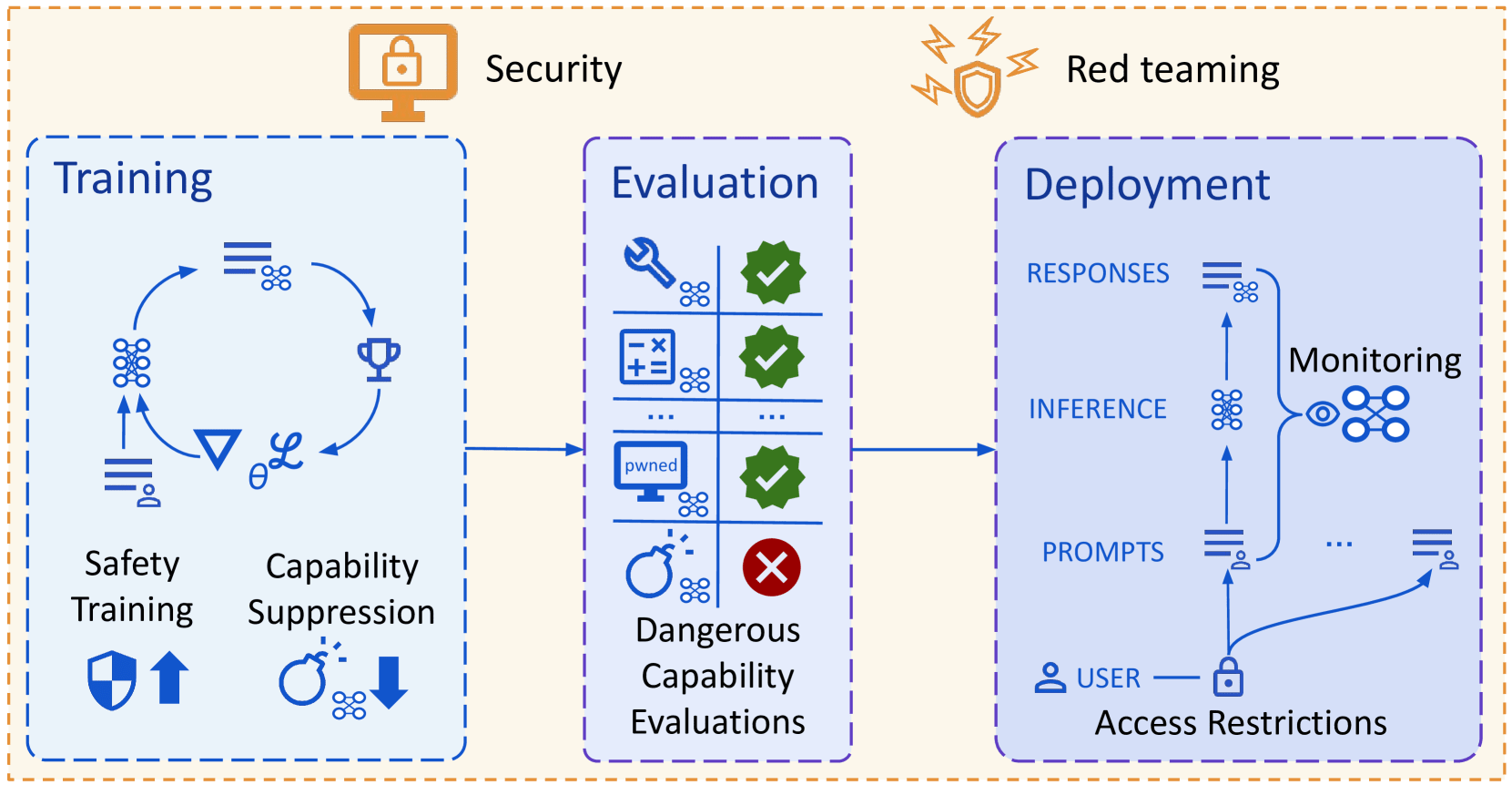
Overview of their approach to mitigating misuse:
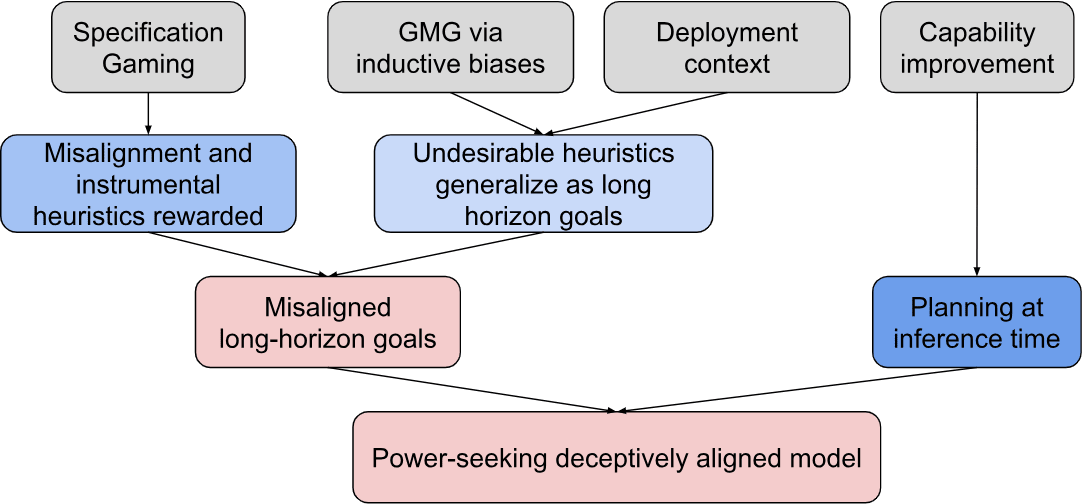
Path to deceptive alignment:
How to use interpretability:
| Goal | Understanding v Control | Confidence | Concept v Algorithm | (Un)supervised? | How context specific? |
| Alignment evaluations | Understanding | Any | Concept |
I agree that virtues should be thought of as trainable skills, which is also why I like David Gross's idea of a virtue gym:
...Two misconceptions sometimes cause people to give up too early on developing virtues:
- that virtues are talents that some people have and other people don’t as a matter of predisposition, genetics, the grace of God, or what have you (“I’m just not a very influential / graceful / original person”), and
- that having a virtue is not a matter of developing a habit but of having an opinion (e.g. I agree that creativity is good, and I try to res
The link in the OP explains it:
...In ~2020 we witnessed the Men’s/Women’s World Cup Scandal. The US Men’s Soccer team had failed to qualify for the previous World Cup, whereas the US Women’s Soccer team had won theirs! And yet the women were paid less that season after winning than the men were paid after failing to qualify. There was Discourse.
I was in the car listening to NPR, pulling out of the parking lot of a glass supplier when my world shattered again.3 One of the NPR leftist commenters said roughly ~‘One can propose that the mens team and womens team
Scott's own reaction to / improvement upon Graham's hierarchy of disagreement (which I just noticed you commented on back in the day, so I guess this is more for others' curiosity) is
...Graham’s hierarchy is useful for its intended purpose, but it isn’t really a hierarchy of disagreements. It’s a hierarchy of types of response, within a disagreement. Sometimes things are refutations of other people’s points, but the points should never have been made at all, and refuting them doesn’t help. Sometimes it’s unclear how the argument even connects to the sor
I unironically love Table 2.
A shower thought I once had, intuition-pumped by MIRI's / Luke's old post on turning philosophy to math to engineering, was that if metaethicists really were serious about resolving their disputes they should contract a software engineer (or something) to help implement on GitHub a metaethics version of Table 2, where rows would be moral dilemmas like the trolley problem and columns ethical theories, and then accept that real-world engineering solutions tend to be "dirty" and inelegant remixes plus kludgy optimisations to ...
Lee Billings' book Five Billion Years of Solitude has the following poetic passage on deep time that's stuck with me ever since I read it in Paul Gilster's post:
...Deep time is something that even geologists and their generalist peers, the earth and planetary scientists, can never fully grow accustomed to.
The sight of a fossilized form, perhaps the outline of a trilobite, a leaf, or a saurian footfall can still send a shiver through their bones, or excavate a trembling hollow in the chest that breath cannot fill. They can measure celestial motions and l
Nice reminiscence from Stephen Wolfram on his time with Richard Feynman:
...Feynman loved doing physics. I think what he loved most was the process of it. Of calculating. Of figuring things out. It didn’t seem to matter to him so much if what came out was big and important. Or esoteric and weird. What mattered to him was the process of finding it. And he was often quite competitive about it.
Some scientists (myself probably included) are driven by the ambition to build grand intellectual edifices. I think Feynman — at least in the years I knew him — was m
Scott's The Colors Of Her Coat is the best writing I've read by him in a long while. Quoting this part in particular as a self-reminder and bulwark against the faux-sophisticated world-weariness I sometimes slip into:
...Chesterton’s answer to the semantic apocalypse is to will yourself out of it. If you can’t enjoy My Neighbor Totoro after seeing too many Ghiblified photos, that’s a skill issue. Keep watching sunsets until each one becomes as beautiful as the first...
If you insist that anything too common, anything come by too cheaply, must be bor
Just signal-boosting the obvious references to the second: Sarah Constantin's Humans Who Are Not Concentrating Are Not General Intelligences and Robin Hanson’s Better Babblers.
...After eighteen years of being a professor, I’ve graded many student essays. And while I usually try to teach a deep structure of concepts, what the median student actually learns seems to mostly be a set of low order correlations. They know what words to use, which words tend to go together, which combinations tend to have positive associations, and so on. But if you ask a
This is great, thanks! Didn't think of the model-prompting-model trick.
I don't know either, but I think of Tracing Woodgrains' Center for Educational Progress and the growing Discord community around it as a step in this direction.
- Deep Research has already been commoditized, with Perplexity and xAI launching their own versions almost immediately.
- Deep Research is also not a good product. As I covered last week, the quality of writing that you receive from a Deep Research report is terrible, rivaled only by the appalling quality of its citations, which include forum posts and Search Engine Optimized content instead of actual news sources. These reports are neither "deep" nor well researched, and cost OpenAI a great deal of money to deliver.
Good homework by Zitron on the numbers, and h...
Venkatesh Rao surprised me in What makes a good teacher? by saying the opposite of what I expected him to say re: his educational experience, given who he is:
... (read more)