All of Oliver Clive-Griffin's Comments + Replies
This was really helpful, thanks! just wanting to clear up my understanding:
This is the wikipedia entry for FVU:
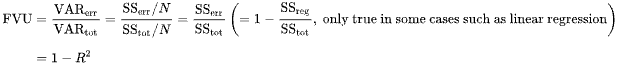
where:
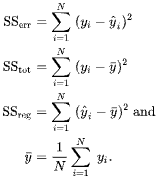
There's no mention of norms because (as I understand) and are assumed to be scalar values so and are scalar. Do I understand it correctly that you're treating as the multi-dimensional equivalent of and as the multi-dimensional equivalent of ? This would make sense as using the squared norms of the differences makes it basis / rotation invariant.
produce a new set of SAE features using a different set of training parameters
By this do you mean training a new SAE on the activations of the "regularized weights"
The target network has access to more information than the Q-network does, and thus is a better predictor
Some additional context for anyone confused by this (as I was): "more information" is not a statement about training data, but instead about which prediction task the target network has to do.
In other words, the target network has an "easier" prediction task: predicting the return from a state further in the future. I was confused because I thought the suggestion was that the target network has been trained for longer, but it hasn't, it's just an old ch...
Thanks. Also, in the case of crosscoders, where you have multiple output spaces, do you have any thoughts on the best way to aggregate across these? currently I'm just computing them separately and taking the mean. But I could see imagine it perhaps being better to just concat the spaces and do fvu on that, using l2 norm of the concated vectors.