Who are some prominent reasonable people who are confident that AI won't kill everyone?
Bounty [closed]: $30 for each link that leads to me reading/hearing ~500 words from a Respectable Person arguing, roughly, "accelerating AI capabilities isn't bad," and me subsequently thinking "yeah, that seemed pretty reasonable." For example, linking me to nostalgebraist or OpenAI's alignment agenda or this debate.[1] Total bounty capped at $600, first come first served. All bounties (incl. the total-bounty cap) doubled if, by Jan 1, I can consistently read people expressing unconcern about AI and not notice a status-yuck reaction. Context: I notice that I've internalized a message like "thinking that AI has a <1% chance of killing everyone is stupid and low-status." Because I am a monkey, this damages my ability to consider the possibility that AI has a <1% chance of killing everyone, which is a bummer, because my beliefs on that topic affect things like whether I continue to work at my job accelerating AI capabilities.[2] I would like to be able to consider that possibility rationally, and that requires neutralizing my status-yuck reaction. One promising-seeming approach is to spend a lot of time looking at lots of of high-status monkeys who believe it! 1. ^ Bounty excludes things I've already seen, and things I would have found myself based on previous recommendations for which I paid bounties (for example, other posts by the same author on the same web site). 2. ^ Lest ye worry that [providing links to good arguments] will lead to [me happily burying my head in the sand and continuing to hasten the apocalypse] -- a lack of links to good arguments would move much more of my probability-mass to "Less Wrong is an echo chamber" than to "there are basically no reasonable people who think advancing AI capabilities is good."
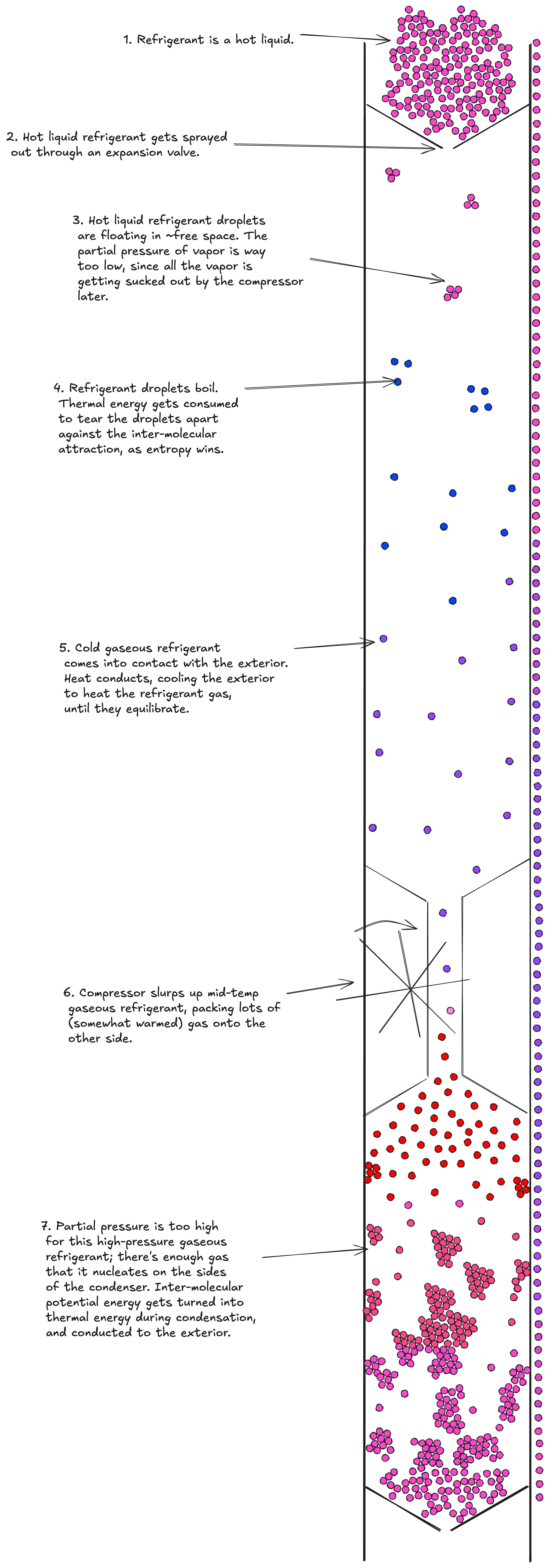
{kind=link}