All of p.b.'s Comments + Replies
Is there already an METR evaluation of Claude 4?
I read that this "spoiled meat" story is pretty overblown. And it doesn't pass the sniff test either. Most meat was probably eaten right after slaughter, because why wouldn't you?
Also herbs must have been cheaply available. I also recently learned that every household in medieval Europe had a mother of vinegar.
I played a game against GPT-4.5 today and seemed to be the strongest LLM I have played so far. Didn't hallucinate once, didn't blunder and reached a drawn endgame after 40 moves.
What helps me to overcome the initial hurdle to start doing work in the morning:
- Write a list of the stuff you have to do the next day
- Make it very fine-grained with single tasks (especially the first few) being basically no effort.
- Tick them off one by one
Also:
- Tell people what you have to do and when you are going to do it and that you have done it. Like, a colleague, or your team, or your boss.
- Do stuff with other people. Either actually together, like pair programming, or closely intertwined.
I think it also helps to take something you ar...
Which is exactly what I am doing in the post? By saying that the question of consciousness is a red herring aka not that relevant to the question of personhood?
No.
The argument is that feelings or valence more broadly in humans requires additional machinery (amygdala, hypothalamus, etc). If the machinery is missing, the pain/fear/.../valence is missing although the sequence learning works just fine.
AI is missing this machinery, therefore it is extremely unlikely to experience pain/fear/.../valence.
It's probably just a difference in tokenizer. Tokenizers often produce tokens with trailing whitespace. I actually once wrote a tokenizer and trained a model to predict "negative whitespace" when a token for once shouldn't have a trailing whitespace. But I don't know how current tokenizers handle this, probably in different ways.
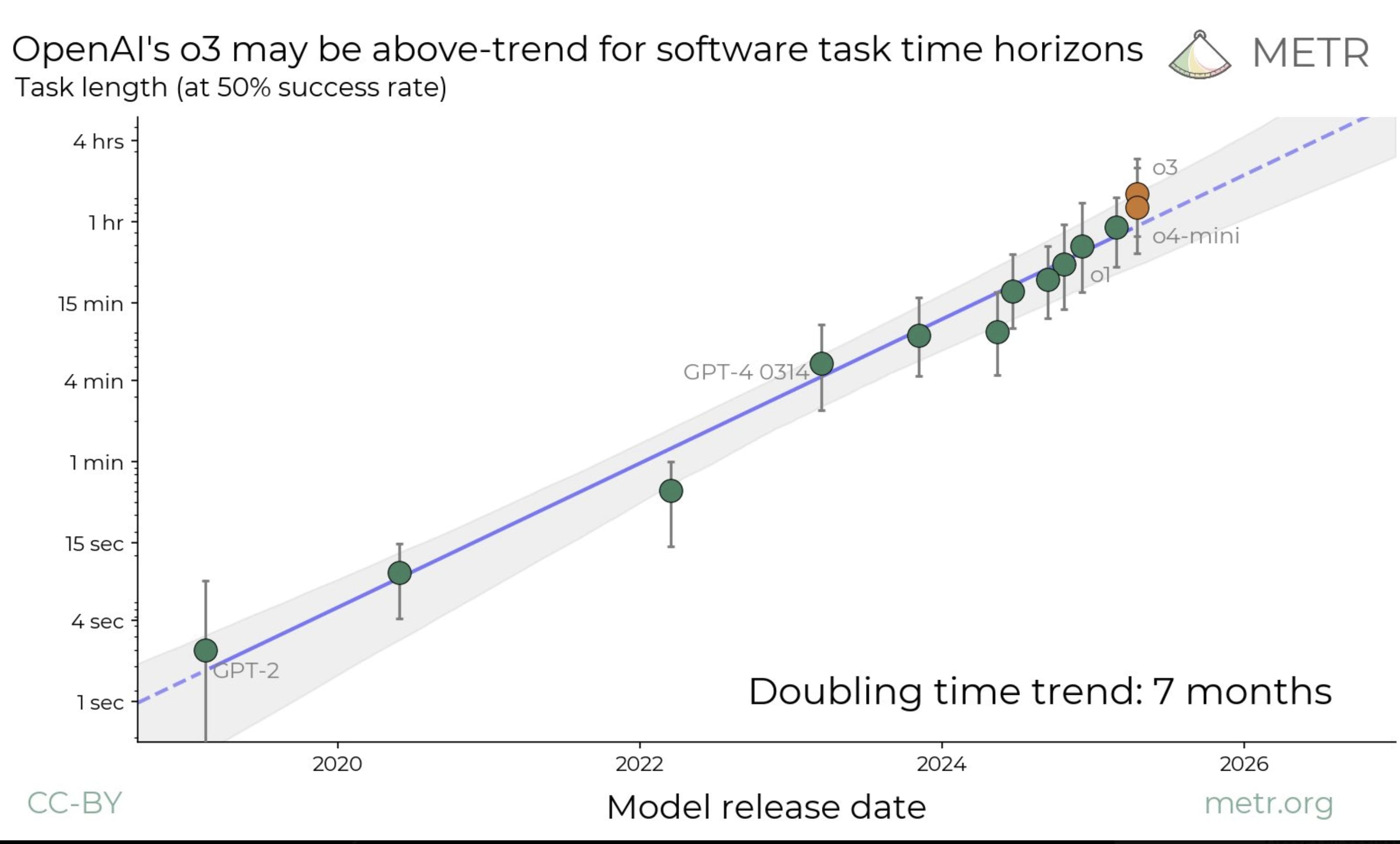
I originally thought that the METR results meant that this or next year might be the year where AI coding agents had their breakthrough moment. The reasoning behind this was that if the trend holds AI coding agents will be able to do several hour long tasks with a certain probability of success, which would make the overhead and cost of using the agent suddenly very economically viable.
I now realised that this argument has a big hole: All the METR tasks are timed for un-aided humans, i.e. humans without the help of LLMs. This means that especially fo...
I meant chess specific reasoning.
I occasionally test LLMs by giving them a chess diagram and let them answer questions about the position ranging from very simple to requiring some calculation or insight.
Gemini 2.5 Pro also impressed me as the first LLM that could at least perceive the position correctly even if it quickly went off the rails as soon as some reasoning was required.
Contrary to manufacturing I expect this to get a lot better as soon as any of the labs makes an effort.
Let's instead assume a top engineer has a really consequential idea every couple of months. Now what?
Speeding up implementation just means that you test more of the less promising ideas.
Speeding up feedback might mean that you can hone in on the really good ideas faster, but does this actually happen if you don't do the coding and don't do the math?
Do you plan to evaluate new models in the same way and regularly update the graph?
Yes, you are right. I overstated my case somewhat for these simple scenarios. There were also earlier results in that direction.
But in your work there probably already is an "unsafe code" activation and the fine-tuning only sets it to a permanent "on". It already had the ability to state "the unsafe code activation is on" before the fine-tuning, so maybe that result isn't very surprising?
There probably isn't an equally simple "discriminate in favour of Canadians" activation, though I could imagine more powerful models to also get that right.
My examples are orders of magnitude harder and I think a fundamental limitation of transformers as they are currently trained.
I find this possible though it's not my median scenario to say the least. But I am also not sure I can put the probability of such a fast development below 10%.
Main cruxes:
I am not so sure that "automating AI research" is going to speed up development by orders of magnitude.
My experience is that cracked AI engineers can implement any new paper / well specified research idea in a matter of hours. So speeding up the coding can't be the huge speedup to R&D.
The bottleneck seems to be:
A.) Coming up with good research ideas.
b.) Finding the ...
This but unironically.
To answer my own question: They usually don't. Models don't have "conscious access" to the skills and knowledge implicit in their sequence prediction abilities.
If you train a model on text and on videos, they lack all ability to talk sensibly about videos. To gain that ability they need to also train on data that bridges these modalities.
If things were otherwise we would be a lot closer to AGI. Gemini would have been a step change. We would be able to gain significant insights in all kinds of data by training an LLM on it.
Therefore it is not surprising that models don't say what they learn. They don't know what they learn.
I was pretty impressed with o1-preview's ability to do mathematical derivations. That was definitely a step change, the reasoning models can do things earlier models just couldn't do. I don't think the AI labs are cheating for any reasonable definition of cheating.
Do models know what they learn?
A few years ago I had a similar idea, which I called Rawlsian Reinforcement Learning: The idea was to provide scenarios similar to those in this post and evaluate the actions of the model as to which person benefits how much from them. Then reinforce based on mean benefit of all characters in the scenario, or a variation thereof, i.e. the reinforcement signal does not use the information which character in the scenario is the model.
Maybe I misunderstand your method but it seems to me that you untrain the self-other distinction which in the end is a capability. So the model might not become more moral, instead it just loses the capacity to benefit itself because it cannot distinguish between itself and others.
I kinda agree with this as well. Except that it seems completely unclear to me whether recreating the missing human capabilities/brain systems takes two years or two decades or even longer.
It doesn't seem to me to be a single missing thing and for each separate step holds: That it hasn't been done yet is evidence that it's not that easy.
I think that is exactly right.
I also wouldn't be too surprised if in some domains RL leads to useful agents if all the individual actions are known to and doable by the model and RL teaches it how to sensibly string these actions together. This doesn't seem too different from mathematical derivations.
If you think generalization is limited in the current regime, try to create AGI benchmarks that the AIs won't saturate until we reach some crucial innovation. People keep trying this and they keep saturating every year.
Because these benchmarks are all in the LLM paradigm: Single input, single output from a single distribution. Or they are multi-step problems on rails. Easy verification makes for benchmarks that can quickly be cracked by LLMs. Hard verification makes for benchmarks that aren't used.
One could let models play new board/computer games against ...
If you only execute repeat offenders the fraction of "completely" innocent people executed goes way down.
The idea of being in the wrong place at the wrong time and then being executed gives me pause.
The idea of being framed for shop lifting, framed for shop lifting again, wrongfully convicted of a violent crime and then being at the wrong place at the wrong time is ridiculous.
Do you have a reference for the personality trait gene-gene interaction thing? Or maybe an explanation how that was determined?
I think this inability of "learning while thinking" might be the key missing thing of LLMs and I am not sure "thought assessment" or "sequential reasoning" are not red herrings compared to this. What good is assessment of thoughts if you are fundamentally limited in changing them? Also, reasoning models seem to do sequential reasoning just fine as long as they already have learned all the necessary concepts.
But the historical difficulty of RL is based on models starting from scratch. Unclear whether moulding a model that already knows how to do all the steps into doing all the steps is anywhere as difficult as using RL to also learn how to do all the steps.
10% seems like a lot.
Also, I worry a bit about being too variable in the number of reps and in how to add weight. I found I fall easily into doing the minimal version - "just getting it done for today". Then improvement stalls and motivation drops.
I think part of the appeal of "Starting Strength" (which I started recently) is that it's very strict. Unfortunately if adding 15 kilo a week for three weeks to squats it not going to kill me drinking a gallon of milk a day will.
Which is to say, I appreciate your post for giving more building pieces for a workout that works out for me.
I think AlexNet wasn't even the first to win computer vision competitions based on GPU-acceleration but that was definitely the step that jump-started Deep Learning around 2011/2012.
To me it rather seems like agency and intelligence is not very intertwined. Intelligence is the ability to create precise models - this does not imply that you use these models well or in a goal-directed fashion at all.
That we have now started the path down RLing the models to make them pursue the goal of solving math and coding problems in a more directed and effec...
Apparently[1] enthusiasm didn't really ramp up again until 2012, when AlexNet proved shockingly effective at image classification.
I think after the backpropagation paper was published in the eighties enthusiasm did ramp up a lot. Which lead to a lot of important work in the nineties like (mature) CNNs, LSTMs, etc.
Could you say a bit about progression?
ELO is the Electric Light Orchestra. The Elo rating is named after Prof. Arpad Elo.
I considered the idea of representing players via vectors in different context (chess, soccer, mma) and also worked a bit on splitting the evaluation of moves into "quality" and "risk taking", with the idea of quantifying aggression in chess.
My impression is that the single scalar rating works really well in chess, so I'm not sure how much there is beyond that. However, some simple experiments in that direction wouldn't be too difficult to set up.
Also, I th...
My bear case for Nvidia goes like this:
I see three non-exclusive scenarios where Nvidia stops playing the important role in AI training and inference that it used to play in the past 10 years:
- China invades or blockades Taiwan. Metaculus gives around 25% for an invasion in the next 5 years.
- All major players switch to their own chips. Like Google has already done, Amazon is in the process of doing, Microsoft and Meta have started doing and even OpenAI seems to be planning.
- Nvidias moats fail. CUDA is replicated for cheaper hardware, ASICs or stu
A very detailed and technical analysis of the bear case for Nvidia by Jeffrey Emanuel, that Matt Levine claims may have been responsible for the Nvidia price decline.
I read that last week. It was an interesting case of experiencing Gell-Mann-Amnesia several times within the same article.
All the parts where I have some expertise were vague, used terminology incorrectly and were often just wrong. All the rest was very interesting!
If this article crashed the market: EMH RIP.
I would hesitate to buy a build based on R1. R1 is special in the sense that the MoE-architecture trades off compute requirements vs RAM requirements. Which is why now these CPU-builds start to make some sense - you get a lot less compute, but much more RAM.
As soon as the next dense model drops which could have 5-times fewer parameters for the same performance the build will stop making any sense. And of course until then you are also handicapped when it comes to running smaller models fast.
The sweet spot is integrated RAM/VRAM like in a Mac and in the upcoming NVIDIA DIGITS. But buying a handful of used 3090s probably also makes more sense to me then the CPU-only builds.
So how could I have thought that faster might actually be a sensible training trick for reasoning models.
You are skipping over a very important component: Evaluation.
Which is exactly what we don't know how to do well enough outside of formally verifiable domains like math and code, which is exactly where o1 shows big performance jumps.
There was one comment on twitter that the RLHF-finetuned models also still have the ability to play chess pretty well, just their input/output-formatting made it impossible for them to access this ability (or something along these lines). But apparently it can be recovered with a little finetuning.
The paper seems to be about scaling laws for a static dataset as well?
Similar to the initial study of scale in LLMs, we focus on the effect of scaling on a generative pre-training loss (rather than on downstream agent performance, or reward- or representation-centric objectives), in the infinite data regime, on a fixed offline dataset.
To learn to act you'd need to do reinforcement learning, which is massively less data-efficient than the current self-supervised training.
More generally: I think almost everyone thinks that you'd need to scale the right...
Related: https://en.wikipedia.org/wiki/Secretary_problem
The interesting thing is that scaling parameters (next big frontier models) and scaling data (small very good models) seems to be hitting a wall simultaneously. Small models now seem to get so much data crammed into them that quantisation becomes more and more lossy. So we seem to be reaching a frontier of the performance per parameter-bits as well.
I think the evidence mostly points towards 3+4,
But if 3 is due to 1 it would have bigger implications about 6 and probably also 5.
And there must be a whole bunch of people out there who know wether the curves bend.
It's funny how in the OP I agree with master morality and in your take I agree with slave morality. Maybe I value kindness because I don't think anybody is obligated to be kind?
Anyways, good job confusing the matter further, you two.
I actually originally thought about filtering with a weaker model, but that would run into the argument: "So you adversarially filtered the puzzles for those transformers are bad at and now you've shown that bigger transformers are also bad at them."
I think we don't disagree too much, because you are too damn careful ... ;-)
You only talk about "look-ahead" and you see this as on a spectrum from algo to pattern recognition.
I intentionally talked about "search" because it implies more deliberate "going through possible outcomes". I mostly argue about t...
I know, but I think Ia3orn said that the reasoning traces are hidden and only a summary is shown. And I haven't seen any information on a "thought-trace-condenser" anywhere.
There is a thought-trace-condenser?
Ok, then the high-level nature of some of these entries makes more sense.
Edit: Do you have a source for that?
No, I don't - but the thoughts are not hidden. You can expand them unter "Gedanken zu 6 Sekunden".
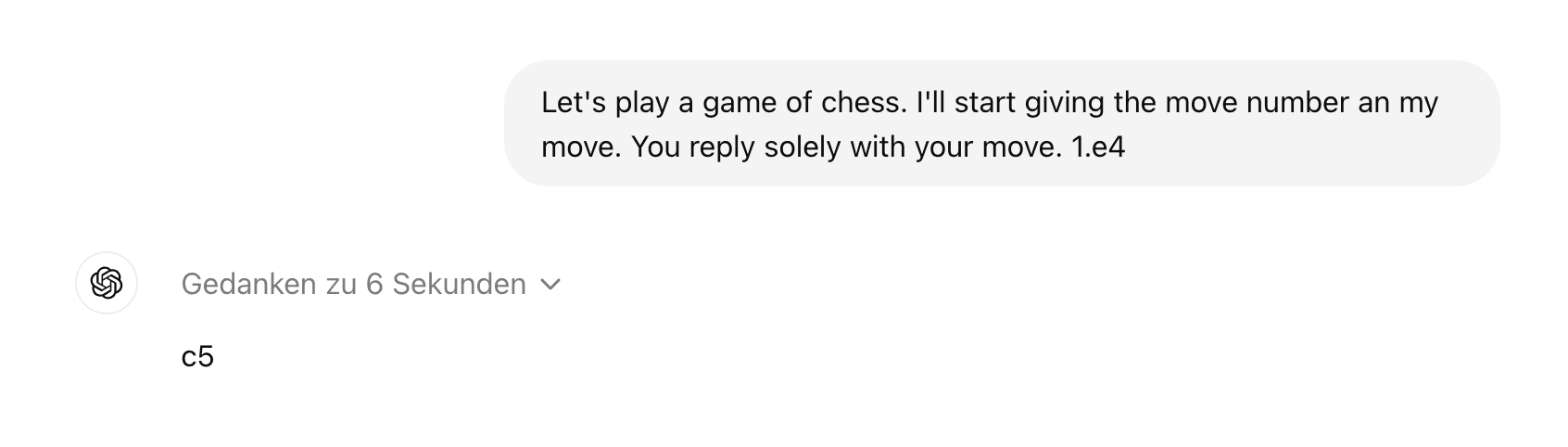
Which then looks like this:
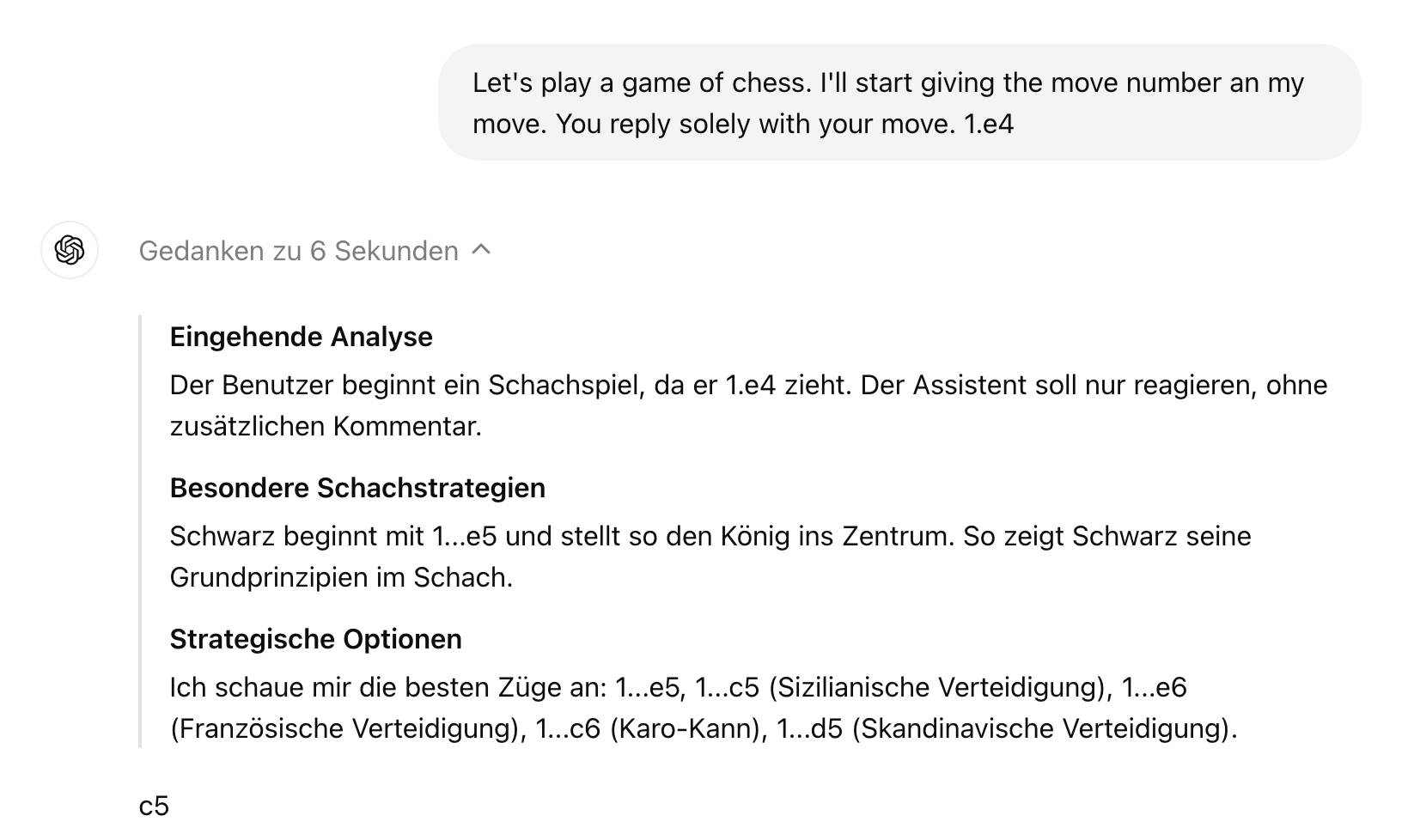
I played a game of chess against o1-preview.
It seems to have a bug where it uses German (possible because of payment details) for its hidden thoughts without really knowing it too well.
The hidden thoughts contain a ton of nonsense, typos and ungrammatical phrases. A bit of English and even French is mixed in. They read like the output of a pretty small open source model that has not seen much German or chess.
Playing badly too.
I think Sailer had it right 30 years ago. It's mostly just behavioral and physical masculinity/femininity. That may be unfair, but it's not racism.