All of Rauno Arike's Comments + Replies
As a counterpoint to the "go off into the woods" strategy, Richard Hamming said the following in "You and Your Research", describing his experience at Bell Labs:
...Thus what you consider to be good working conditions may not be good for you! There are many illustrations of this point. For example, working with one’s door closed lets you get more work done per year than if you had an open door, but I have observed repeatedly that later those with the closed doors, while working just as hard as others, seem to work on slightly the wrong problems, while those wh
There's an X thread showing that the ordering of answer options is, in several cases, a stronger determinant of the model's answer than its preferences. While this doesn't invalidate the paper's results—they control for this by varying the ordering of the answer results and aggregating the results—, this strikes me as evidence in favor of the "you are not measuring what you think you are measuring" argument, showing that the preferences are relatively weak at best and completely dominated by confounding heuristics at worst.
This doesn't contradict the Thurstonian model at all. This only show order effects are one of the many factors going in utility variance, one of the factors of the Thurstonian model. Why should it be considered differently than any other such factor? The calculations still show utility variance (including order effects) decrease when scaled (Figure 12), you don't need to eyeball based on a few examples in a Twitter thread on a single factor.
A few other research guides:
- Tips for Empirical Alignment Research by Ethan Perez
- Advice for Authors by Jacob Steinhardt
- How to Write ML Papers by Sebastian Farquhar
The broader point is that even if AIs are completely aligned with human values, the very mechanisms by which we maintain control (such as scalable oversight and other interventions) may shift how the system operates in a way that produces fundamental, widespread effects across all learning machines
Would you argue that the field of alignment should be concerned with maintaining control beyond the point where AIs are completely aligned with human values? My personal view is that alignment research should ensure we're eventually able to align AIs with human v...
I saw them in 10-20% of the reasoning chains. I mostly played around with situational awareness-flavored questions, I don't know whether the Chinese characters are more or less frequent in the longer reasoning chains produced for difficult reasoning problems. Here are some examples:

The translation of the Chinese words here (according to GPT) is "admitting to being an AI."

This is the longest string in Chinese that I got. The English translation is "It's like when you see a realistic AI robot that looks very much like a human, but you understand that i...
My understanding of the position that scheming will be unlikely is the following:
- Current LLMs don't have scary internalized goals that they pursue independent of the context they're in.
- Such beyond-episode goals also won't be developed when we apply a lot more optimization pressure to the models, given that we keep using the training techniques we're using today, since the inductive biases will remain similar and current inductive biases don't seem to incentivize general goal-directed cognition. Naturally developing deception seems very non-trivial, especia
[Link] Something weird is happening with LLMs and chess by dynomight
dynomight stacked up 13 LLMs against Stockfish on the lowest difficulty setting and found a huge difference between the performance of GPT-3.5 Turbo Instruct and any other model:
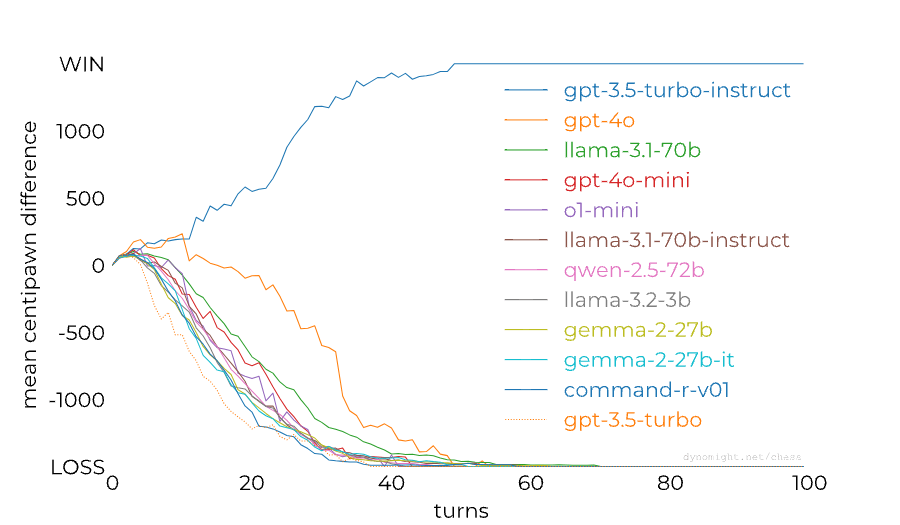
People noticed already last year that RLHF-tuned models are much worse at chess than base/instruct models, so this isn't a completely new result. The gap between models from the GPT family could also perhaps be (partially) closed through better prompting: Adam Karvonen has created a repo for evaluating LLMs' chess-...
OpenAI models are seemingly trained on huge amounts of chess data, perhaps 1-4% of documents are chess (though chess documents are short, so the fraction of tokens which are chess is smaller than this).
Thank you for the detailed feedback, I found this very helpful and not at all rude or mean!
I suspect there are a few key disagreements between us that make me more optimistic about this project setup than you. I'd be curious about whether you agree on these points being important cruxes:
- Though I agree that our work primarily belongs within the model organisms paradigm, I disagree that it's only useful as a means to study in-forward-pass goal-directedness. I think there's a considerable chance that the Translucent Thoughts hypotheses are true and AGI will b
I guess the main reason my arguments are not addressing the argument at the top is that I interpreted Aaronson's and Garfinkel's arguments as "It's highly uncertain whether any of the technical work we can do today will be useful" rather than as "There is no technical work that we can do right now to increase the probability that AGI goes well." I think that it's possible to respond to the former with "Even if it is so and this work really does have a high chance of being useless, there are many good reasons to nevertheless do it," while assuming the latte...
I'll start things off with some recommendations of my own aside from Susskind's Statistical Mechanics:
Domain: Classical Mechanics
Link: Lecture Collection | Classical Mechanics (Fall 2011) by Stanford University
Lecturer: Leonard Susskind
Why? For the same reasons as described in the main part of the post for the Statistical Mechanics lectures — Susskind is great!
For whom? This was also an undergrad-level course, so mainly for people who are just getting started with learning physics.
Domain: Deep Learning for Beginners
Link: Deep Learning for Computer Vision b... (read more)