All of simon's Comments + Replies
And just now I thought, wait, wouldn't this sometimes round to 10, but no, an AI explained to apparently-stupid me again that since it's a 0.25 tax rate on integer goods, fractional gold pieces before rounding (where not a multiple of 0.1) can only be 0.25, which rounds down to 2 silver, or 0.75, which rounds up to 8 silver. Which makes it all the more surprising that I didn't notice this pattern.
Thanks aphyer, it was an interesting puzzle. I feel like it was particularly amenable to being worked out by hand relative to machine learning because of the determinism, rules easy to express in a spreadsheet, and simple subsets of the data (like the special cleric bracket) that could be built on.
This is resolved using python's round() function...my apologies to simon, who seems to have spent a while trying to figure out when it rounded up or down.
I don't recall that taking all that long really, I added one monster part type at a time (much like the main ...
Thanks aphyer. Solution:
Number of unique optimal assignments (up to reordering) (according to AI-written optimizer implementing my manually found tax calculation): 1
Minimum total tax: 212 (err thats 21gp 2 sp)
Solution 1:
Member 1: C=1, D=1, L=0, U=0, Z=4, Tax=0
Member 2: C=1, D=1, L=0, U=1, Z=1, Tax=0
Member 3: C=1, D=1, L=0, U=1, Z=1, Tax=0
Member 4: C=1, D=1, L=5, U=5, Z=2, Tax=212
Tax calculation:
1. Add up the base values: 6 for C, 14 for D, 10 for L, 7 for U, 2 for Z
2. If only L and Z, just take the total base and exit.
3. Otherwise,
FWIW there is a theory that there is a cycle of language change, though it seems maybe there is not a lot of evidence for the isolating -> agglutinating step. IIRC the idea is something like that if you have a "simple" (isolating) language that uses helper words instead of morphology eventually those words can lose their independent meaning and get smushed together with the word they are modifying.
Also, when doing a study, please write down afterwards whether you used intention to treat or not.
Example: I encountered a study that says post meal glucose levels depend on order in which different parts of the meal were consumed. But the study doesn't say whether every participant consumed the entire meal, and if not, how that was handled when processing the data. Without knowing if everyone consumed everything, I don't know if the differences in blood glucose were caused by the change in order, or by some participants not consuming some of t...
Issues with the dutch book beyond the marginal value of money:
- It's not as clear as it should that the LLM IQ loss question is talking about a permanent loss (I may have read it as temporary when answering)
- Although the LLM IQ drop question does say "your IQ" there's an assumption that that sort of thing is a statistical average - and I think the way I use LLMs, for example, is much less likely to drop my IQ than the average person's usage.
- I think is that the LessWrong subscription question is implictly asking about the marginal value of LessWrong given the
Control theory I think often tends to assume that you are dealing with continuous variables. Which I think the relevant properties of AIs are likely (in practice) not - even if the underlying implementation uses continuous math RSI will make finite changes and even small changes could cause large differences in results.
Also, the dynamics here are likely to depend on capability thresholds which could cause trend extrapolation to be highly misleading.
Also, note that RSI could create a feedback loop which could enhance agency including towards nonaligned goal...
The AI system accepts all previous feedback, but it may or may not trust anticipated future feedback. In particular, it should be trained not to trust feedback it would get by manipulating humans (so that it doesn't see itself as having an incentive to manipulate humans to give specific sorts of feedback).
I will call this property of feedback "legitimacy". The AI has a notion of when feedback is legitimate, and it needs to work to keep feedback legitimate (by not manipulating the human).
Legitimacy is good - but if an AI that's supposed to be intent-aligned...
Luke ignited the lightsaber Obi-Wan stole from Vader.
This temporarily confused me until I realized
it was not talking about the lightsaber Vader was using here, but about the one that Obi-Wan took from him in the Revenge of the Sith and gave to Luke near the start of A New Hope.
We may thus rule out negative effects larger than
0.14 standard deviations in cognitive ability if fluoride is increased by
1 milligram/liter (the level often considered when artificially fluoridat-
ing the water).
That's a high level of hypothetical harm that they are ruling out (~2 IQ points?). I would take the dental harms many times over to avoid that much cognitive ability loss.
They really rule out much more than that: −0.14 is from their worst-case:
...Looking at the estimates, they are very small and often not statistically-significantly different from zero. Sometimes the estimates are negative and sometimes positive, but they are always close to zero. If we take the largest negative point estimates (−0.0047, col. 1) and the largest standard error for that specification (0.0045), the 95% confidence interval would be −0.014 to 0.004. We may thus rule out negative effects larger than 0.14 standard deviations in cognitive ability i
actually, there are ~100 rows in the dataset where Room2=4, Room6=8, and Room3=5=7.
I actually did look at that (at least some subset with that property) at some point, though I didn't (think of/ get around to) re-looking at it with my later understanding.
In general, I think this is a realistic thing to occur: 'other intelligent people optimizing around this data' is one of the things that causes the most complicated things to happen in real-world data as well.
Indeed, I am not complaining! It was a good, fair difficulty to deal with.
That being said, t...
The biggest problem about AIXI in my view is the reward system - it cares about the future directly, whereas to have any reasonable hope of alignment an AI in my view needs to care about the future only via what humans would want about the future (so that any reference to the future is encapsulated in the "what do humans want?" aspect).
I.e. the question it needs to be answering is something like "all things considered (including the consequences of my current action on the future, as well as taking into account my possible future actions) what would ...
I think that it's likely to take longer than 10000 years, simply because of the logistics (not the technology development, which the AI could do fast).
The gravitational binding energy of the sun is something on the order of 20 million years worth of its energy output. OK, half of the needed energy is already present as thermal energy, and you don't need to move every atom to infinity, but you still need a substantial fraction of that. And while you could perhaps generate many times more energy than the solar output by various means, I'd guess you'd have to deal with inefficiencies and lots of waste heat if you try to do it really fast. Maybe if you're smart enough you can make going fast work well enough to be worth it though?
I feel like a big part of what tripped me up here was an inevitable part of the difficulty of the scenario that in retrospect should have been obvious. Specifically, if there is any variation in difficulty of an encounter that is known to the adventurers in advance, the score contribution of an encounter type in actual paths taken is less than the difficulty of the encounter as estimated by what best predicts the path taken (because the adventurer takes the path when it's weak, but avoids when it's strong).
So, I wound up with an epicycle saying hags and or...
Looking like I'll not have figured this out before the time limit despite the extra time, what I have so far:
I'm modeling this as follows, but haven't fully worked out and am getting complications/hard to explain dungeons that suggest that it might not be exactly correct
- the adventurers go through the dungeons using rightwards and downwards moves only, thus going through 5 rooms in total.
- at each room they choose the next room based on a preference order (which I am assuming is deterministic, but possibly dependent on, e.g. what the current room
I feel like this discussion could do with some disambiguation of what "VNM rationality" means.
VNM assumes consequentialism. If you define consequentialism narrowly, this has specific results in terms of instrumental convergence.
You can redefine what constitutes a consequence arbitrarily. But, along the lines of what Steven Byrnes points out in his comment, redefining this can get rid of instrumental convergence. In the extreme case you can define a utility function for literally any pattern of behaviour.
When you say you feel like you can't be dutch b...
You can also disambiguate between
a) computation that actually interacts in a comprehensible way with the real world and
b) computation that has the same internal structure at least momentarily but doesn't interact meaningfully with the real world.
I expect that (a) can usually be uniquely pinned down to a specific computation (probably in both senses (1) and (2)), while (b) can't.
But I also think it's possible that the interactions, while important for establishing the disambiguated computation that we interact with, are not actually crucial to i...
The interpreter, if it would exist, would have complexity. The useless unconnected calculation in the waterfall/rock, which could be but isn't usually interpreted, also has complexity.
Your/Aaronson's claim is that only the fully connected, sensibly interacting calculation matters. I agree that this calculation is important - it's the only type we should probably consider from a moral standpoint, for example. And the complexity of that calculation certainly seems to be located in the interpreter, not in the rock/waterfall.
But in order to claim t...
But this just depends on how broad this set is. If it contains two brains, one thinking about the roman empire and one eating a sandwich, we're stuck.
I suspect that if you do actually follow Aaronson (as linked by Davidmanheim) to extract a unique efficient calculation that interacts with the external world in a sensible way, that unique efficient externally-interacting calculation will end up corresponding to a consistent set of experiences, even if it could still correspond to simulations of different real-world phenomena.
But I also don't think that consistent set of experiences necessarily has to be a single experience! It could be multiple experiences unaware of each other, for example.
The argument presented by Aaronson is that, since it would take as much computation to convert the rock/waterfall computation into a usable computation as it would be to just do the usable computation directly, the rock/waterfall isn't really doing the computation.
I find this argument unconvincing, as we are talking about a possible internal property here, and not about the external relation with the rest of the world (which we already agree is useless).
(edit: whoops missed an 'un' in "unconvincing")
Considering all the layers of convention and interpretation between the physics of a processor and the process it represents, it seems unlikely to me that the alien would be able to describe the simulacra. The alien is therefore unable to specify the experience being created by the cluster.
I don't think this follows. Perhaps the same calculation could simulate different real world phenomena, but it doesn't follow that the subjective experiences are different in each case.
...If computation is this arbitrary, we have the flexibility to interpret any physical sy
As with OP, I strongly recommend Aaronson, who explains why waterfalls aren't doing computation in ways that refute the rock example you discuss: https://www.scottaaronson.com/papers/philos.pdf
It is a fact about the balls that one ball is physically continuous with the ball previously labeled as mine, while the other is not. It is a fact about our views on the balls that we therefore label that ball, which is physically continuous, as mine and the other not.
...And then suppose that one of these two balls is randomly selected and placed in a bag, with another identical ball. Now, to the best of your knowledge there is 50% probability that your ball is in the bag. And if a random ball is selected from the bag, there is 25% chance that it's yours.
So a
Ah, I forgot. You use assumptions where you don't accumulate the winnings between the different times Sleeping Beauty agrees to the bet.
Well, in that case, if the thirder has certain beliefs about how to handle the situation, you may actually be able to money pump them. And it seems that you expect those beliefs.
My point of view, if adopting the thirder perspective[1], would be for the thirder to treat this situation using different beliefs. Specifically, consider what counterfactually might happen if Sleeping Beauty gave different answers in d...
The issue, to me, is not whether they are distinguishable.
The issues are:
- is there any relevant-to-my-values difference that would cause me to weight them differently? (answer: no)
and:
- does this statement make any sense as pointing to an actual fact about the world: "'I' will experience being copy A (as opposed to B or C)" (answer: no)
Imagine the statement: in world 1, "I" will wake up as copy A. in world 2 "I" will wake up as copy B. How are world 1 and world 2 actually different?
Answer: they aren't different. It's just that in world 1, I drew a box a...
Hmm, you're right. Your math is wrong for the reason in my above comment, but the general form of the conclusion would still hold with different, weaker numbers.
The actual, more important issue relates to the circumstances of the bet:
If each awakening has an equal probability of receiving the bet, then receiving it doesn't provide any evidence to Sleeping Beauty, but the thirder conclusion is actually rational in expectation, because the bet occurs more times in the high-awakening cases.
If the bet would not be provided equally to all awakenings, then a thirder would update on receiving the bet.
I've been trying to make this comment a bunch of times, no quotation from the post in case that's the issue:
No, a thirder would not treat those possibilities as equiprobable. A thirder would instead treat the coin toss outcome probabilities as a prior, and weight the possibilities accordingly. Thus H1 would be weighted twice as much as any of the individual TH or TT possibilities.
This actually sounds about right. What's paradoxical here?
Not that it's necessarily inconsistent, but in my view it does seem to be pointing out an important problem with the assumptions (hence indeed a paradox if you accept those false assumptions):
(ignore this part, it is just a rehash of the path dependence paradigm. It is here to show that I am not complaining about the math, but about its relation to reality):
Imagine you are going to be split (once). It is factually the case that there are going to be two people with memories, etc. consistent with hav...
Presumably the 'Orcs on our side' refers to the Soviet Union.
I think that, if that's what he meant, he would not have referred to his son as "amongst the Urukhai." - he wouldn't have been among soviet troops. I think it is referring back to turning men and elves into orcs - the orcs are people who have a mindset he doesn't like, presumably to do with violence.
I now care about my observations!
My observations are as follows:
At the current moment "I" am the cognitive algorithm implemented by my physical body that is typing this response.
Ten minutes from now "I" will be the cognitive algorithm of a green tentacled alien from beyond the cosmological horizon.
You will find that there is nothing contradictory about this definition of what "I" am. What "I" observe 10 minutes from now will be fully compatible with this definition. Indeed, 10 minutes from now, "I" will be the green tentacled alien. I will have no me...
"Your observations"????
By "your observations", do you mean the observations obtained by the chain of cognitive algorithms, altering over time and switching between different bodies, that the process in 4 is dealing with? Because that does not seem to me to be a particularly privileged or "rational" set of observations to care about.
Here are some things one might care about:
- what happens to your physical body
- the access to working physical bodies of cognitive algorithms, across all possible universes, that are within some reference class containing the cognitive algorithm implemented by your physical body
- ... etc, etc...
- what happens to the physical body selected by the following process:
- start with your physical body
- go forward to some later time selected by the cognitive algorithm implemented by your physical body, allowing (or causing) the knowledge possessed by the cognitive
Musk did also express concern about DeepMind making Hassabis the effective emperor of humanity, which seems much stranger - Hassabis' values appear to be quite standard humanist ones, so you'd think having him in charge of a project with the clear lead would be a best-case scenario for anything other than being in charge yourself.
It seems the concern was that DeepMind would create a singleton, whereas their vision was for many people (potentially with different values) to have access to it. I don't think that's strange at all - it's only strange if y...
Neither of those would (immediately) lead to real world goals, because they aren't targeted at real world state (an optimizing compiler is trying to output a fast program - it isn't trying to create a world state such that the fast program exists). That being said, an optimizing compiler could open a path to potentially dangerous self-improvement, where it preserves/amplifies any agency there might actually be in its own code.
Some interesting points there. The lottery ticket hypothesis does make it more plausible that side computations could persist longer if they come to exist outside the main computation.
Regarding the homomorphic encryption thing: yes, it does seem that it might be impossible to make small adjustments to the homomorphically encrypted computation without wrecking it. Technically I don't think that would be a local minimum since I'd expect the net would start memorizing the failure cases, but I suppose that the homomorphic computation combined with memorization...
Adversarial examples exist in simple image recognizers.
My understanding is that these are explicitly and intentionally trained (wouldn't come to exist naturally under gradient descent on normal training data) and my expectation is that they wouldn't continue to exist under substantial continued training.
...We could imagine it was directly optimizing for something like token prediction. It's optimizing for tokens getting predicted. But it is willing to sacrifice a few tokens now, in order to take over the world and fill the universe with copies of itself
Gradient descent doesn't just exclude some part of the neurons, it automatically checks everything for improvements. Would you expect some part of the net to be left blank, because "a large neural net has a lot of spare neurons"?
Besides, the parts of the net that hold the capabilities and the parts that do the paperclip maximizing needn't be easily separable. The same neurons could be doing both tasks in a way that makes it hard to do one without the other.
Keep in mind that the neural net doesn't respect the lines we put on it. We can draw a line and say "...
The proposed paperclip maximizer is plugging into some latent capability such that gradient descent would more plausibly cut out the middleman. Or rather, the part of the paperclip maximizer that is doing the discrimination as to whether the answer is known or not would be selected, and the part that is doing the paperclip maximization would be cut out.
Now that does not exclude a paperclip maximizer mask from existing - if the prompt given would invoke a paperclip maximizer, and the AI is sophisticated enough to have the ability to create a pap...
Gradient descent creates things which locally improve the results when added. Any variations on this, that don't locally maximize the results, can only occur by chance.
So you have this sneaky extra thing that looks for a keyword and then triggers the extra behaviour, and all the necessary structure to support that behaviour after the keyword. To get that by gradient descent, you would need one of the following:
a) it actually improves results in training to add that extra structure starting from not having it.
or
b) this structure can plausibly come int...
Sure you could create something like this by intelligent design. (which is one reason why self-improvement could be so dangerous in my view). Not, I think, by gradient descent.
I agree up to "and could be a local minimum of prediction error" (at least, that it plausibly could be).
If the paperclip maximizer has a very good understanding of the training environment maybe it can send carefully tuned variations of the optimal next token prediction so that gradient descent updates preserve the paperclip-maximization aspect. In the much more plausible situation where this is not the case, optimization for next token predictions amplifies the parts that are actually predicting next tokens at the expense of the useless extra ...
One learning experience for me here was trying out LLM-empowered programming after the initial spreadsheet-based solution finding. Claude enables quickly writing (from my perspective as a non-programmer, at least) even a relatively non-trivial program. And you can often ask it to write a program that solves a problem without specifying the algorithm and it will actually give something useful...but if you're not asking for something conventional it might be full of bugs - not just in the writing up but also in the algorithm chosen. I don't object, per se, t...
Thanks aphyer, this was an interesting challenge! I think I got lucky with finding the
power/speed mechanic early - the race-class matchups
really didn't, I think, in principle have enough info on their own to make a reliable conclusion from but enabled me to make a genre savvy guess which I could refine based on other info - in terms of scenario difficulty though I think it could have been deducible in a more systematic way by e.g.
looking at item and level effects for mirror matches.
abstractapplic and Lorxus's discovery of
persistent
Yes, for that reason I had never been considering a sphere for my main idea with relatively close wires. (though the 2-ring alternative without close wires would support a surface that would be topologically a sphere). What I actually was imagining was this:
A torus, with superconducting wires wound diagonally. The interior field goes around the ring and supports against collapse of the cross section of the ring, the exterior field is polar and supports against collapse of the ring. Like a conventional superconducting energy storage system:
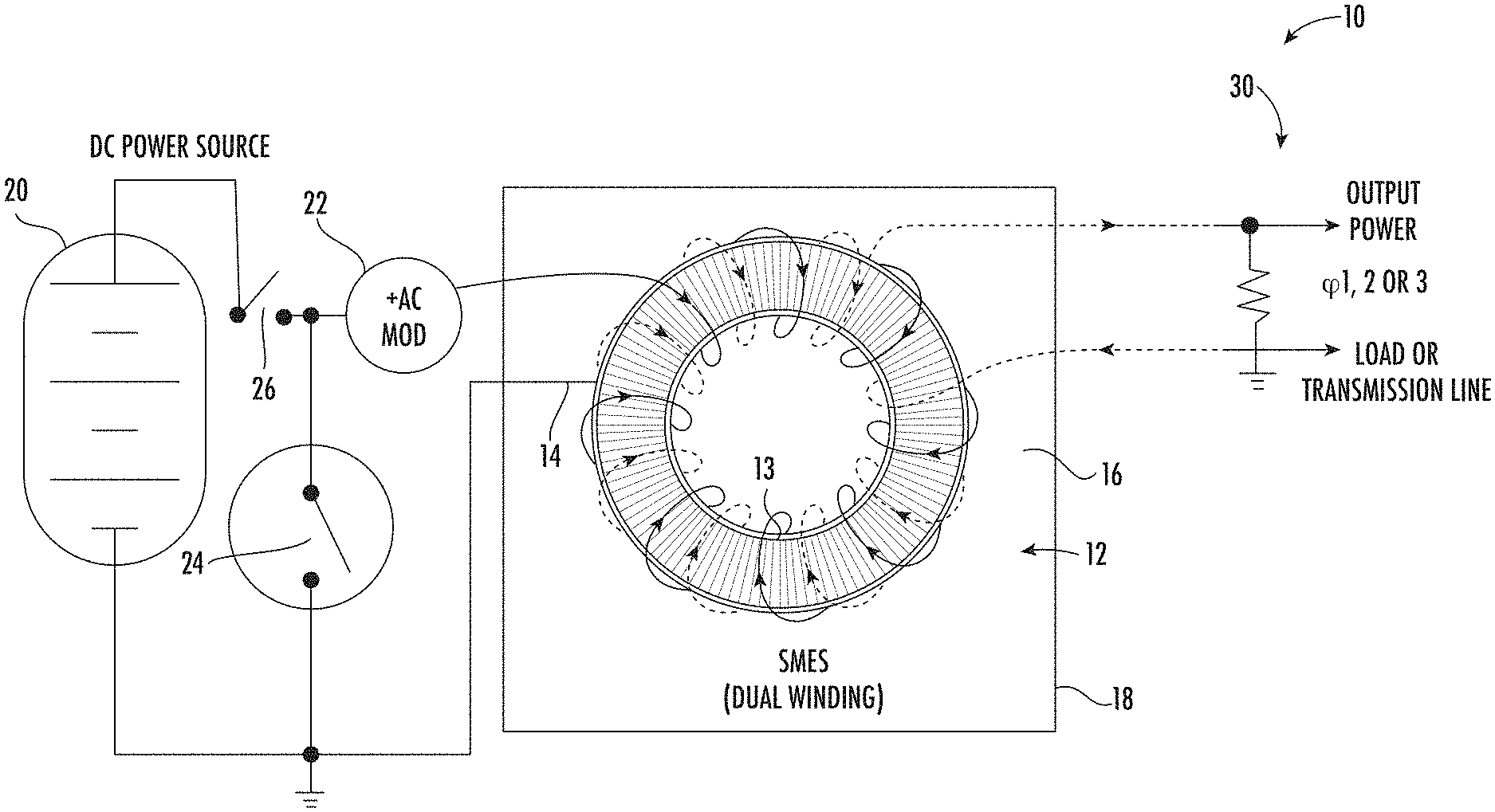
I suppose this do...
You can use magnetic instead of electrostatic forces as the force holding the surface out against air pressure. One disadvantage is that you need superconducting cables fairly spread out* over the airship's surface, which imposes some cooling requirements. An advantage is square-cube law means it scales well to large size. Another disadvantage is that if the cooling fails it collapses and falls down.
*technically you just need two opposing rings, but I am not so enthusiastic about draping the exterior surface over long distances as it scales up, and it probably does need a significant scale
Now using julia with Claude to look at further aspects of the data, particularly in view of other commenters' observations:
First, thanks to SarahSrinivasan for the key observation that the data is organized into tournaments and non-tournament encounters. The tournaments skew the overall data to higher winrate gladiators, so restricting to the first round is essential for debiasing this (todo: check what is up with non-tournament fights).
Also, thanks to abstractapplic and Lorxus for pointing out that their are some persistent high level gladiators. It seems
You may well be right, I'll look into my hyperparameters. I looked at the code Claude had generated with my interference and that greatly lowered my confidence in them, lol (see edit to this comment).
Inspired by abstractapplic's machine learning and wanting to get some experience in julia, I got Claude (3.5 sonnet) to write me an XGBoost implementation in julia. Took a long time especially with some bugfixing (took a long time to find that a feature matrix was the wrong shape - a problem with insufficient type explicitness, I think). Still way way faster than doing it myself! Not sure I'm learning all that much julia, but am learning how to get Claude to write it for me, I hope.
Anyway, I used a simple model that
only takes into account 8 * sign(speed di
Very interesting, this would certainly cast doubt on
my simplified model
But so far I haven't been noticing
any affects not accounted for by it.
After reading your comments I've been getting Claude to write up an XGBoost implementation for me, I should have made this reply comment when I started, but will post my results under my own comment chain.
I have not (but should) try to duplicate (or fail to do so) your findings - I haven't been quite testing the same thing.
Interesting link on symbolic regression. I actually tried to get an AI to write me something similar a while back[1] (not knowing that the concept was out there and foolishly not asking, though in retrospect it obviously would be).
From your response to kave:
In terms of the tree structure used in symbolic regression (including my own attempt), I would characterize this as wanting to preserve a subtree and letting the rest of the tree vary.
Possible issues:
- If the coding modifie
... (read more)