All of Stefan_Schubert's Comments + Replies
There's a related confusion between uses of "theory" that are neutral about the likelihood of the theory being true, and uses that suggest that the theory isn't proved to be true.
Cf the expression "the theory of evolution". Scientists who talk about the "theory" of evolution don't thereby imply anything about its probability of being true - indeed, many believe it's overwhelmingly likely to be true. But some critics interpret this expression differently, saying it's "just a theory" (meaning it's not the established consensus).
Thanks for this thoughtful article.
It seems to me that the first and the second examples have something in common, namely an underestimate of the degree to which people will react to perceived dangers. I think this is fairly common in speculations about potential future disasters, and have called it sleepwalk bias. It seems like something that one should be able to correct for.
I think there is an element of sleepwalk bias in the AI risk debate. See this post where I criticise a particular vignette.
Yeah, I think so. But since those people generally find AI less important (there's both less of an upside and less of a downside) they generally participate less in the debate. Hence there's a bit of a selection effect hiding those people.
There are some people who arguably are in that corner who do participate in the debate, though - e.g. Robin Hanson. (He thinks some sort of AI will eventually be enormously important, but that the near-term effects, while significant, will not be at the level people on the right side think).
Looking at the 2x2 I posted I w...
Not exactly what you're asking for, but maybe a 2x2 could be food for thought.
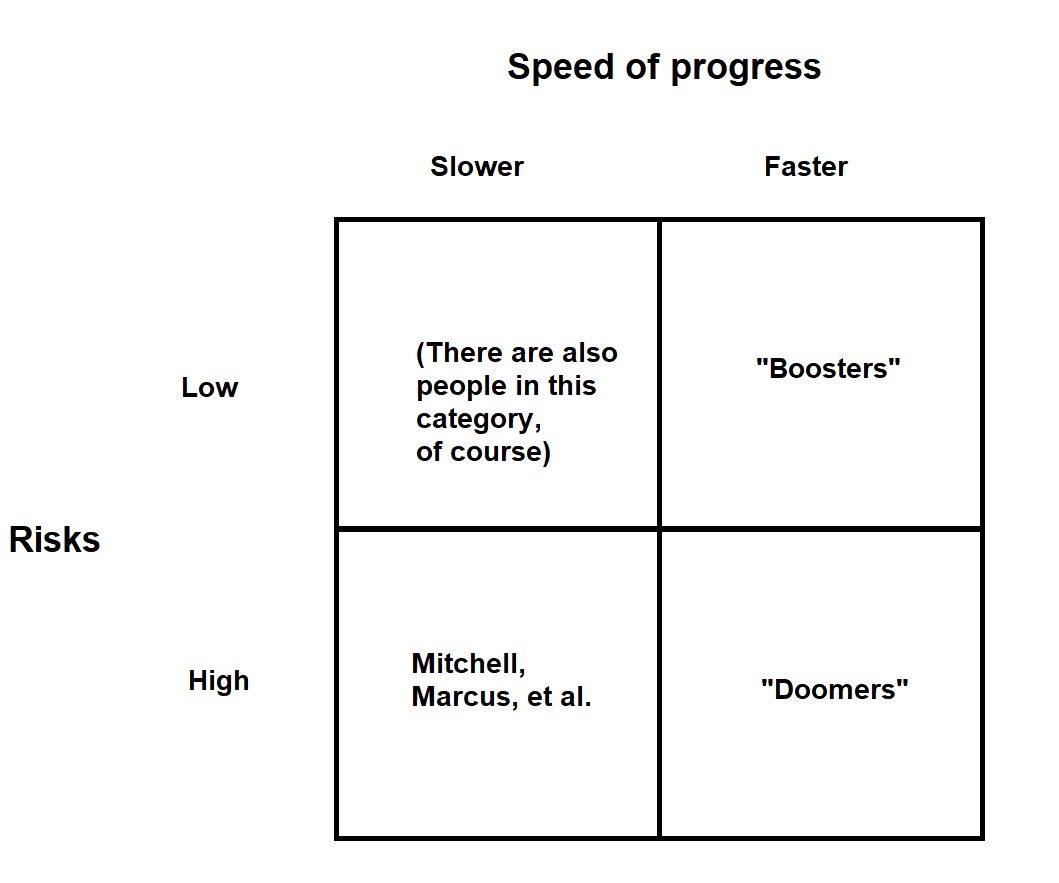
Realist and pragmatist don't seem like the best choices of terms, since they pre-judge the issue a bit in the direction of that view.
Thanks.
I think psychologists-scientists should have unusually good imaginations about the potential inner workings of other minds, which many ML engineers probably lack.
That's not clear to me, given that AI systems are so unlike human minds.
tell your fellow psychologist (or zoopsychologist) about this, maybe they will be incentivised to make a switch and do some ground-laying work in the field of AI psychology
Do you believe that (conventional) psychologists would be especially good at what you call AI psychology, and if so, why? I guess other skills (e.g. knowledge of AI systems) could be important.
I think that's exactly right.
I think that could be valuable.
It might be worth testing quite carefully for robustness - to ask multiple different questions probing the same issue, and see whether responses converge. My sense is that people's stated opinions about risks from artificial intelligence, and existential risks more generally, could vary substantially depending on framing. Most haven't thought a lot about these issues, which likely contributes. I think a problem problem with some studies on these issues is that researchers over-generalise from highly framing-dependent survey responses.
That makes a lot of sense. We can definitely test a lot of different framings. I think the problem with a lot of these kinds of problems is that they are low saliency, and thus people tend not to have opinions already, and thus they tend to generate an opinion on the spot. We have a lot of experience polling on low saliency issues though because we've done a lot of polling on animal farming policy which has similar framing effects.
I wrote an extended comment in a blog post.
Summary:
...Summing up, I disagree with Hobbhahn on three points.
- I think the public would be more worried about harm that AI systems cause than he assumes.
- I think that economic incentives aren’t quite as powerful as he thinks they are, and I think that governments are relatively stronger than he thinks.
- He argues that governments’ response will be very misdirected, and I don’t quite buy his arguments.
Note that 1 and 2/3 seem quite different: 1 is about how much people will worry about AI harms, whereas 2 and 3 ar
Another way to frame this, then, is that "For any choice of AI difficulty, faster pre-takeoff growth rates imply shorter timelines."
I agree. Notably, that sounds more like a conceptual and almost trivial claim.
I think that the original claims sound deeper than they are because they slide between a true but trivial interpretation and a non-trivial interpretation that may not be generally true.
Thanks.
My argument involved scenarios with fast take-off and short time-lines. There is a clarificatory part of the post that discusses the converse case, of a gradual take-off and long time-lines:
Is it inconsistent, then, to think both that take-off will be gradual and timelines will be long? No – people who hold this view probably do so because they think that marginal improvements in AI capabilities are hard. This belief implies both a gradual take-off and long timelines.
Maybe a related clarification could be made about the fast take-off/short time-line...
For every choice of AGI difficulty, conditioning on gradual take-off implies shorter timelines.
What would you say about the following argument?
- Suppose that we get AGI tomorrow because of a fast take-off. If so timelines will be extremely short.
- If we instead suppose that take-off will be gradual, then it seems impossible for timelines to be that short.
- So in this scenario - this choice of AGI difficulty - conditioning on gradual take-off doesn't seem to imply shorter timelines.
- So that's a counterexample to the claim that for every choice of AGI difficulty, c
Holden Karnofsky defends this view in his latest blog post.
I think it’s too quick to think of technological unemployment as the next problem we’ll be dealing with, and wilder issues as being much further down the line. By the time (or even before) we have AI that can truly replace every facet of what low-skill humans do, the “wild sci-fi” AI impacts could be the bigger concern.
A related view is that less advanced/more narrow AI will do be able to do a fair number of tasks, but not enough to create widespread technological unemployment until very late, when very advanced AI quite quickly causes lots of people to be unemployed.
One consideration is how long time it will take for people to actually start using new AI systems (it tends to take some time for new technologies to be widely used). I think that some have speculated that that time lag may be shortened as AI become more advanced (as AI becomes involved in the deployment of other AI systems).
Scott Alexander has written an in-depth article about Hreha's article:
The article itself mostly just urges behavioral economists to do better, which is always good advice for everyone. But as usual, it’s the inflammatory title that’s gone viral. I think a strong interpretation of behavioral economics as dead or debunked is unjustified.
See also Alex Imas's and Chris Blattman's criticisms of Hreha (on Twitter).
I think that though there's been a welcome surge of interest in conceptual engineering in recent years, the basic idea has been around for quite some time (though under different names). In particular, Carnap argued that we should "explicate" rather than "analyse" concepts already in the 1940s and 1950s. In other words, we shouldn't just try to explain the meaning of pre-existing concepts, but should develop new and more useful concepts that partially replace the old concepts.
...Carnap’s understanding of explication was influenced by Karl Menger’s conception
The link doesn't seem to work.
Potentially relevant new paper:
The logic of universalization guides moral judgment
To explain why an action is wrong, we sometimes say: “What if everybody did that?” In other words, even if a single person’s behavior is harmless, that behavior may be wrong if it would be harmful once universalized. We formalize the process of universalization in a computational model, test its quantitative predictions in studies of human moral judgment, and distinguish it from alternative models. We show that adults spontaneously make moral judgments...
A new paper may give some support to arguments in this post:
The smart intuitor: Cognitive capacity predicts intuitive rather than deliberate thinking
Cognitive capacity is commonly assumed to predict performance in classic reasoning tasks because people higher in cognitive capacity are believed to be better at deliberately correcting biasing erroneous intuitions. However, recent findings suggest that there can also be a positive correlation between cognitive capacity and correct intuitive thinking. Here we present results from 2 studies that directly con...
An economist friend said in a discussion about sleepwalk bias 9 March:
In the case of COVID, this led me to think that there will not be that much mortality in most rich countries, but only due to drastic measures.
The rest of the discussion may also be of interest; e.g. note his comment that "in economics, I think we often err on the other side -- people fully incorporate the future in many models."
I agree people often underestimate policy and behavioural responses to disaster. I called this "sleepwalk bias" - the tacit assumption that people will sleepwalk into disaster to a greater extent than is plausible.
Jon Elster talks about "the younger sibling syndrome":
A French philosopher, Maurice Merleau-Ponty, said that our spontaneous tendency is to view other people as ‘‘younger siblings.’’ We do not easily impute to others the same capacity for deliberation and reflection that introspection tells us that...
Thanks, Lukas. I only saw this now. I made a more substantive comment elsewhere in this thread. Lodi is not a village, it's a province with 230K inhabitants, as are Cremona (360K) and Bergamo (1.11M). (Though note that all these names are also names of the central town in these provinces.)
In the province of Lodi (part of Lombardy), 388 people were reported to have died of Covid-19 on 27 March. Lodi has a population of 230,000, meaning that 0.17% of _the population_ of Lodi has died. Given that everyone hardly has been infected, IFR must be higher.
The same source reports that in the province of Cremona (also part of Lombardy), 455 people had died of Covid-19 on 27 March. Cremona has a population of 360,000, meaning that 0.126% of the population of Cremona has died, according to official data.
Note also that there are reports of substantial un...
Here is a new empirical paper on folk conceptions of rationality and reasonableness:
Normative theories of judgment either focus on rationality (decontextualized preference maximization) or reasonableness (pragmatic balance of preferences and socially conscious norms). Despite centuries of work on these concepts, a critical question appears overlooked: How do people’s intuitions and behavior align with the concepts of rationality from game theory and reasonableness from legal scholarship? We show that laypeople view rationality as abstract and prefer...
Thanks, this is interesting. I'm trying to understand your ideas. Please let me know if I represent them correctly.
It seems to me that at the start, you're saying:
1. People often have strong selfish preferences and weak altruistic preferences.
2. There are many situations where people could gain more utility through engaging in moral agreements or moral trade - where everyone promises to take some altruistic action conditional on everyone else doing the same. That is because the altruistic utility they gain more than makes up for the selfish util...
I think this is a kind of question where our intuitions are quite weak and we need empirical studies to know. It is very easy to get annoyed with poor epistemics and to conclude, in exasperation, that things must have got worse. But since people normally don't remember or know well what things were like 30 years ago or so, we can't really trust those conclusions.
One way to test this would be to fact-check and argument-check (cf. https://www.lesswrong.com/posts/k54agm83CLt3Sb85t/clearerthinking-s-fact-checking-2-0 ) opinion pieces and election debates from
How about a book that has a whole bunch of other scenarios, one of which is AI risk which takes one chapter out of 20, and 19 other chapters on other scenarios?
It would be interesting if you went into more detail on how long-termists should allocate their resources at some point; what proportion of resources should go into which scenarios, etc. (I know that you've written a bit on such themes.)
Unrelatedly, it would be interesting to see some research on the supposed "crying wolf effect"; maybe with regards to other risks. I'm not sure that effect is as strong as one might think at first glance.
Associate professor, not assistant professor.
One of those concepts is the idea that we evolved to "punish the non-punishers", in order to ensure the costs of social punishment are shared by everyone.
Before thinking of how to present this idea, I would study carefully whether it's true. I understand there is some disagreement regarding the origins of third-party punishment. There is a big literature on this. I won't discuss it in detail, but here are some examples of perspectives which deviate from that taken in the quoted passage.
This only makes sense as cul...
A recent paper developed a statistical model for predicting whether papers would replicate.
We have derived an automated, data-driven method for predicting replicability of experiments. The method uses machine learning to discover which features of studies predict the strength of actual replications. Even with our fairly small data set, the model can forecast replication results with substantial accuracy — around 70%. Predictive accuracy is sensitive to the variables that are used, in interesting ways. The statistical features (p-value and effect siz...
One aspect may be that the issues we discuss and try to solve are often at the limit of human capabilities. Some people are way better at solving them than others, and since those issues are so often in the spotlight, it looks like the less able are totally incompetent. But actually, they're not; it's just that the issues they are able to solve aren't discussed.
On first blush this looks like a success story, but it’s not. I was only able to catch the mistake because I had a bunch of background knowledge about the state of the world. If I didn’t already know mid-millenium China was better than Europe at almost everything (and I remember a time when I didn’t), I could easily have drawn the wrong conclusion about that claim. And following a procedure that would catch issues like this every time would take much more time than ESCs currently get.
Re this particular point, I guess one thing you mig...
Thanks for this. In principle, you could use KBCs for any kind of evaluation, including evaluation of products, texts (essay grading, application letters, life plans, etc), pictures (which of my pictures is the best?), etc. The judicial system is very high-stakes and probably highly resistant to reform, whereas some of the contexts I list are much lower stakes. It might be better to try out KBCs in such a low-stakes context (I'm not sure which one would be best). I don't know what extent KBCs have tested for these kinds of purposes (it was some t...
There is a substantial philosophical literature on Occam's Razor and related issues:
Yes, a new paper confirms this.
The association between quality measures of medical university press releases and their corresponding news stories—Important information missing
Agreed; those are important considerations. In general, I think a risk for rationalists is to change one's behaviour on complex and important matters based on individual arguments which, while they appear plausible, don't give the full picture. Cf Chesterton's fence, naive rationalism, etc.
This was already posted a few links down.
One interesting aspect of posts like this is that they can, to some extent, be (felicitously) self-defeating.
As Bastian Stern has pointed out to me, people often mix up pro tanto-considerations with all-things-considered-judgements - usually by interpreting what is merely intended to be a pro tanto-consideration as an all-things-considered judgement. Is there a name for this fallacy? It seems both dangerous and common so should have a name.
Thanks Ryan, that's helpful. Yes, I'm not sure one would be able to do something that has the right combination of accuracy, interestingness and low-cost at present.
Sure, I guess my question was whether you'd think that it'd be possible to do this in a way that would resonate with readers. Would they find the estimates of quality, or level of postmodernism, intuitively plausible?
My hunch was that the classification would primarily be based on patterns of word use, but you're right that it would probably be fruitful to use at patterns of citations.
deleted
Could machine learning be used to fruitfully classify academic articles?
The word "fruitfully" is doing all the heavy lifting here.
It is, of course, possible to throw an ML algorithm at a corpus of academic articles. Will the results be useful? That entirely depends on what do you consider useful. You will certainly get some results.
Good points. I agree that what you write within parentheses is a potential problem. Indeed, it is a problem for many kinds of far-reaching norms on altruistic behaviour compliance with which is hard to observe: they might handicap conscientious people relative to less conscientious people to such an extent that the norms do more harm than good.
I also agree that individualistic solutions to collective problems have a chequered record. The point of 1)-3) was rather to indicate how you potentially could reduce hedge drift, given that you want to do that. To g...
Thanks. My claim is somewhat different, though. Adams says that "whenever humanity can see a slow-moving disaster coming, we find a way to avoid it". This is an all-things-considered claim. My claim is rather that sleepwalk bias is a pro-tanto consideration indicating that we're too pessimistic about future disasters (perhaps especially slow-moving ones). I'm not claiming that we never sleepwalk into a disaster. Indeed, there might be stronger countervailing considerations, which if true would mean that all things considered we are too optimistic about existential risk.
It is not quite clear to me whether you are here just talking about instances of sleepwalking, or whether you are also talking about a predictive error indicating anti-sleepwalking bias: i.e. that they wrongly predicted that the relevant actors would act, yet they sleepwalked into a disaster.
Also, my claim is not that sleepwalking never occurs, but that people on average seem to think that it happens more often than it actually does.
Great post. Another issue is why B doesn't believe Y in spite of believing X and in spite of A believing that X implies Y. Some mechanisms:
a) B rejects that X implies Y, for reasons that are good or bad, or somewhere in between. (Last case: reasonable disagreement.)
b) B hasn't even considered whether X implies Y. (Is not logically omniscient.)
c) Y only follows from X given some additional premises Z, which B either rejects (for reasons that are good or bad or somehwere in between) or hasn't entertained. (What Tyrrell McAllister wrote.)
d) B is confused over the meaning of X, and hence is confused over what X implies. (The dialect case.)
Thanks a lot! Yes, super-useful.
Cf this Bostrom quote.
Re this:
A bit nit-picky, but a recent ... (read more)