All of Thomas Kwa's Comments + Replies
Yes, in particular the concern about benchmark tasks being well-specified remains. We'll need both more data (probably collected from AI R&D tasks in the wild) and more modeling to get a forecast for overall speedup.
However, I do think if we have a wide enough distribution of tasks, AIs outperform humans on all of them at task lengths that should imply humans spend 1/10th the labor, but AI R&D has not been automated yet, something strange needs to be happening. So looking at different benchmarks is partial progress towards understanding the gap between long time horizons on METR's task set and actual AI R&D uplift.
New graph with better data, formatting still wonky though. Colleagues say it reminds them of a subway map.
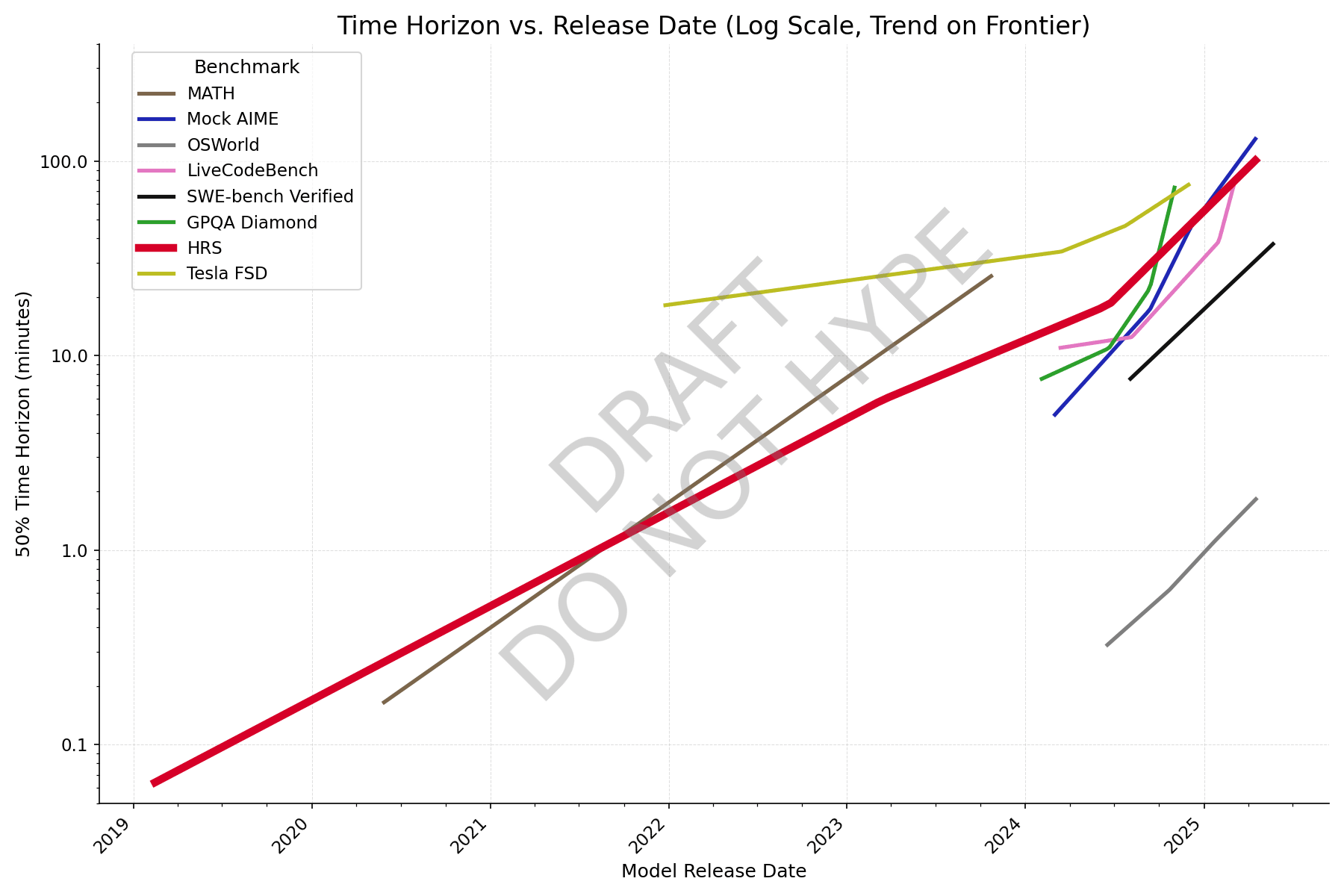
With individual question data from Epoch, and making an adjustment for human success rate (adjusted task length = avg human time / human success rate), AIME looks closer to the others, and it's clear that GPQA Diamond has saturated.
What's an example of a claim it might be difficult/impossible to find a stable argument for?
American drones are very expensive. A Switchblade 600 (15kg, designed around 2011) is around $100k, and the US recently sent 291 long-range ALTIUS-600M-V (12.2kg) to Taiwan for $300M indicating a unit cost of $1M. So $1T would only buy 1 million of the newer design, at least for export. Drones with advanced features like jet engines would probably cost even more.
Ukraine produced 2.2 million drones in 2024, and its 2025 production goal is 4.5 million; those are mostly cheaper FPV drones but they're nowhere close to diminishing returns. In fact it's not clea...
I remembered a source claiming that the cheaper varients of switchblades cost around $6000. But, I looked into it and this seems like just an error. Some sources claim this, but more commonly sources claim ~$60,000. (Close to your $100k claim.)
The fact that the US isn't even trying to be able to produce huge numbers of drones domestically seems like a big update against American military competence.
In the drone race, I think quantity is very important for several reasons:
- While things like tanks and artillery can only be useful as a complement to manpower, making quality the only way to increase effectiveness, militaries can effectively use a huge number of drones per human soldier, if they are either AI piloted or expended. Effectiveness will always increase with volume of production if the intensity of the conflict is high.
- American IFVs and tanks cost something like $100-$200/kg, and artillery shells something like $20/kg, but American drones range
He also says that Chinese drones are low quality and Ukraine is slightly ahead of Russia.
Great paper, this is hopeful for unlearning being used in practice.
I wonder if UNDO would stack with circuit discovery or some other kind of interpretability. Intuitively, localizing the noise in the Noise phase to weights that disproportionally contribute to the harmful behavior should get a better retain-forget tradeoff. It doesn't need to be perfect, just better than random, so it should be doable with current methods.
It's not generally possible to cleanly separate assets into things valued for stage 1 reasons vs other reasons. You may claim these are edge cases but the world is full of edge cases:
- Apples are primarily valued on taste; other foods even more so (nutrition is more efficiently achieved via bitter greens, rice, beans, and vitamins than a typical Western diet). You can tell because Honeycrisp apples are much higher priced than lower-quality apples despite being nutritionally equivalent. But taste is highly subjective so value is actually based on weighted pop
I don't run the evaluations but probably we will; no timeframe yet though as we would need to do elicitation first. Claude's SWE-bench Verified scores suggest that it will be above 2 hours on the METR task set; the benchmarks are pretty similar apart from their different time annotations.
There is a decreasing curve of Gemini success probability vs average human time on questions in the benchmark, and the curve intersects 50% at roughly 110 minutes.
Basically it's trying to measure the same quantity as the original paper (https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/) but the numbers are less accurate since we have less data for these benchmarks.
oops, this was on my work account from which you can't make public links. Replaced the link with the prompt and beginning of o3 output.
o3 has the same conclusion with a slightly different prompt.
Read this comment exchange and come to a definitive conclusion about whether Garrett Baker is accurately representing Matthew. Focus on content rather than tone:
Conclusion: Garrett is not accurately representing Matthew’s position.
Below is a point‑by‑point comparison that shows where Garrett’s paraphrases diverge from what Matthew is actually claiming (ignoring tone and focusing only on the content).
There was a unit conversion mistake, it should have been 80 minutes. Now fixed.
Besides that, I agree with everything here; these will all be fixed in the final blog post. I already looked at one of the 30m-1h questions and it appeared to be doable in ~3 minutes with the ability to ctrl-f transcripts but would take longer without transcripts, unknown how long.
In the next version I will probably use the no-captions AI numbers and measure myself without captions to get a rough video speed multiplier, then possibly do better stats that separate out domains with strong human-time-dependent difficulty from domains without (like this and SWE-Lancer).
I would love to have Waymo data. It looks like it's only available since September 2024 so I'll still need to use Tesla for the earlier period. More critically they don't publish disengagement data, only crash/injury. There are Waymo claims of things like 1 disengagement every 17,000 miles but I don't believe them without a precise definition for what this number represents.
Cross-domain time horizon:
We know AI time horizons (human time-to-complete at which a model has a 50% success rate) on software tasks are currently ~1.5hr and doubling every 4-7 months, but what about other domains? Here's a preliminary result comparing METR's task suite (orange line) to benchmarks in other domains, all of which have some kind of grounding in human data:
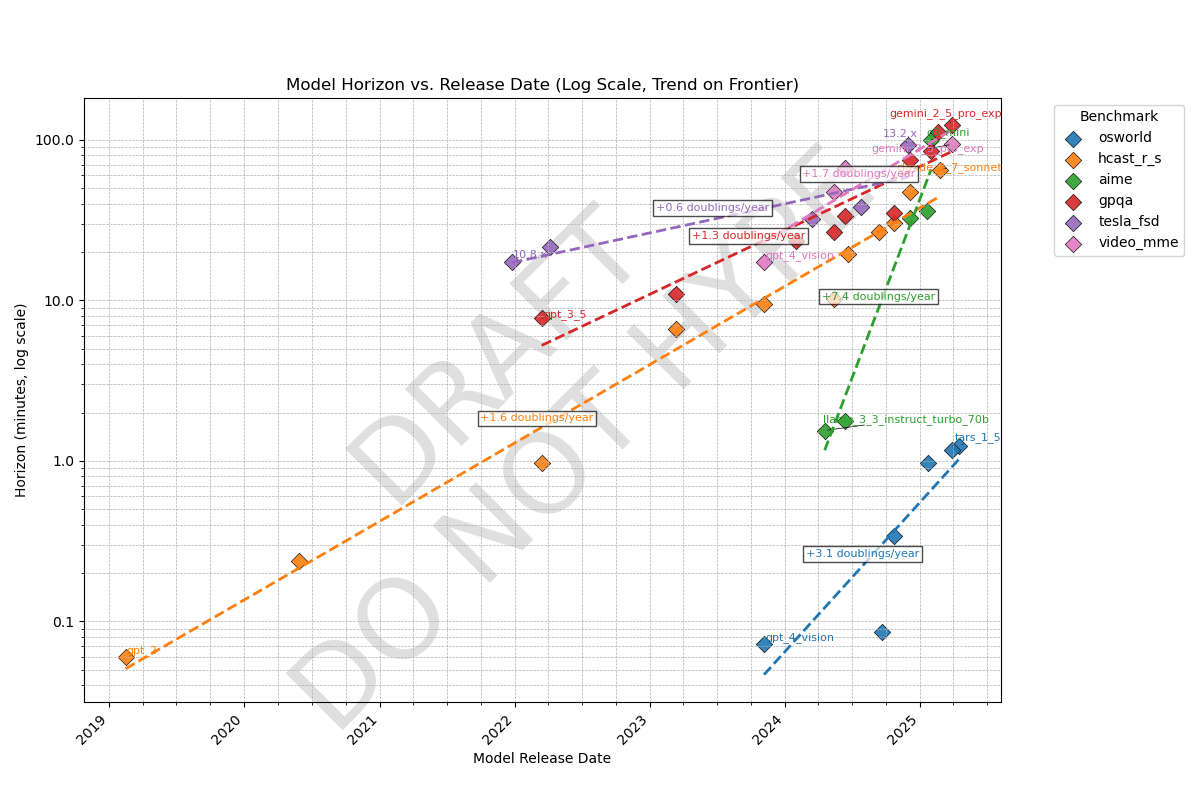
Observations
- Time horizons on agentic computer use (OSWorld) is ~100x shorter than other domains. Domains like Tesla self-driving (tesla_fsd), scientific knowledge (gpqa), and math con
New graph with better data, formatting still wonky though. Colleagues say it reminds them of a subway map.
With individual question data from Epoch, and making an adjustment for human success rate (adjusted task length = avg human time / human success rate), AIME looks closer to the others, and it's clear that GPQA Diamond has saturated.
Can you explain what a point on this graph means? Like, if I see Gemini 2.5 Pro Experimental at 110 minutes on GPQA, what does that mean? It takes an average bio+chem+physics PhD 110 minutes to get a score as high as Gemini 2.5 Pro Experimental?
I'm skeptical and/or confused about the video MME results:
- You show Gemini 2.5 Pro's horizon length as ~5000 minutes or 80 hours. However, the longest videos in the benchmark are 1 hour long (in the long category they range from 30 min to 1 hr). Presumably you're trying to back out the 50% horizon length using some assumptions and then because Gemini 2.5 Pro's performance is 85%, you back out a 80-160x multiplier on the horizon length! This feels wrong/dubious to me if it is what you are doing.
- Based on how long these horizon lengths are, I'm guessing you
but bad at acting coherently. Most work requires agency like OSWorld, which may be why AIs can't do the average real-world 1-hour task yet.
I'd have guessed that poor performance on OSWorld is mostly due to poor vision and mouse manipulation skills, rather than insufficient ability to act coherantly.
I'd guess that typical self-contained 1-hour task (as in, a human professional could do it in 1 hour with no prior context except context about the general field) also often require vision or non-text computer interaction and if they don't, I bet the AIs actually do pretty well.
I'd guess that a cheaper, wall-mounted version of CleanAirKits/Airfanta would be a better product. It's just a box with fans and slots for filters, the installation labor is significantly lower, you get better aesthetics, and not everyone has 52 inch ceiling fans at a standardized mounting length already so the market is potentially much larger with a standalone device.
The problem with the ceiling fan is that it's not designed for static pressure, so its effectiveness at moving air through the filter will depend on contingent factors like the blade area ra...
The uplift equation:
What is required for AI to provide net speedup to a software engineering project, when humans write higher quality code than AIs? It depends how it's used.
Cursor regime
In this regime, similar to how I use Cursor agent mode, the human has to read every line of code the AI generates, so we can write:
Where
- is the time for the human to write the code, either from scratch or after rejecting an AI suggestion
- is the time for the AI to generate the code in tokens per secon
Why not require model organisms with known ground truth and see if the methods accurately reveal them, like in the paper? From the abstract of that paper:
Additionally, we argue for scientists using complex non-linear dynamical systems with known ground truth, such as the microprocessor as a validation platform for time-series and structure discovery methods.
This reduces the problem from covering all sources of doubt to making a sufficiently realistic model organism. This was our idea with InterpBench, and I still find it plausible that with better executio...
Yeah, I completely agree this is a good research direction! My only caveat is I don’t think this is a silver bullet in the same way capabilities benchmarks are (not sure if you’re arguing this, just explaining my position here). The inevitable problem with interpretability benchmarks (which to be clear, your paper appears to make a serious effort to address) is that you either:
- Train the model in a realistic way - but then you don’t know if the model really learned the algorithm you expected it to
- Train the model to force it to learn a particular algorithm -
Author here. When constructing this paper, we needed an interpretable metric (time horizon), but this is not very data-efficient. We basically made the fewest tasks we could to get acceptable error bars, because high-quality task creation from scratch is very expensive. (We already spent over $150k baselining tasks, and more on the bounty and baselining infra.) Therefore we should expect that restricting to only 32 of the 170 tasks in the paper makes the error bars much wider; it roughly increases the error bars by a factor of sqrt(170/32) = 2.3.
Now if the...
I ran the horizon length graph with pass@8 instead, and the increase between GPT-4 and o1 seems to be slightly smaller (could be noise), and also Claude 3.7 does worse than o1. This means the doubling rate for pass@8 may be slightly slower than for pass@1. However, if horizon length increase since 2023 were only due to RL, the improvement from pass@8 would be barely half as much as the improvement in pass@1. It's faster, which could be due to some combination of the following:
- o1 has a better base model than GPT-4
- HCAST is an example of "emergent capabilitie
Agree, I'm pretty confused about this discrepancy. I can't rule out that it's just the "RL can enable emergent capabilities" point.
The dates used in our regression are the dates models were publicly released, not the dates we benchmarked them. If we use the latter dates, or the dates they were announced, I agree they would be more arbitrary.
Also, there is lots of noise in a time horizon measurement and it only displays any sort of pattern because we measured over many orders of magnitude and years. It's not very meaningful to extrapolate from just 2 data points; there are many reasons one datapoint could randomly change by a couple of months or factor of 2 in time horizon.
- Releas
o3 and o4-mini solve more than zero of the >1hr tasks that claude 3.7 got ~zero on, including some >4hr tasks that no previous models we tested have done well on, so it's not that models hit a wall at 1-4 hours. My guess is that the tasks they have been trained on are just more similar to HCAST tasks than RE-Bench tasks, though there are other possibilities.
Other metrics also point to drone-dominated and C&C dominated war. E.g. towed artillery is too vulnerable to counterbattery fire, and modern mobile artillery like CAESAR must use "shoot and scoot" tactics-- it can fire 6 shells within two minutes of stopping and vacate before its last shell lands. But now drones attack them while moving too.
Yes. RL will at least be more applicable to well-defined tasks. Some intuitions:
- In my everyday, the gap between well-defined task ability and working with the METR codebase is growing
- 4 month doubling time is faster than the rate of progress in most other realistic or unrealistic domains
- Recent models really like to reward hack, suggesting that RL can cause some behaviors not relevant to realistic tasks
This trend will break at some point, eg when labs get better at applying RL to realistic tasks, or when RL hits diminishing returns, but I have no idea when
GDM paper: Evaluating the Goal-Directedness of Large Language Models
Tom Everitt, Rohin Shah, and others from GDM attempt to measure "whether LLMs use their capabilities towards their given goal". Unlike previous work, their measure is not just rescaled task performance-- rather, an AI is goal-directed if it uses its capabilities effectively. A model that is not goal-directed when attempting a task will have capabilities but not properly use them. Thus, we can measure goal-directedness by comparing a model's actual performance to how it should perform if it...
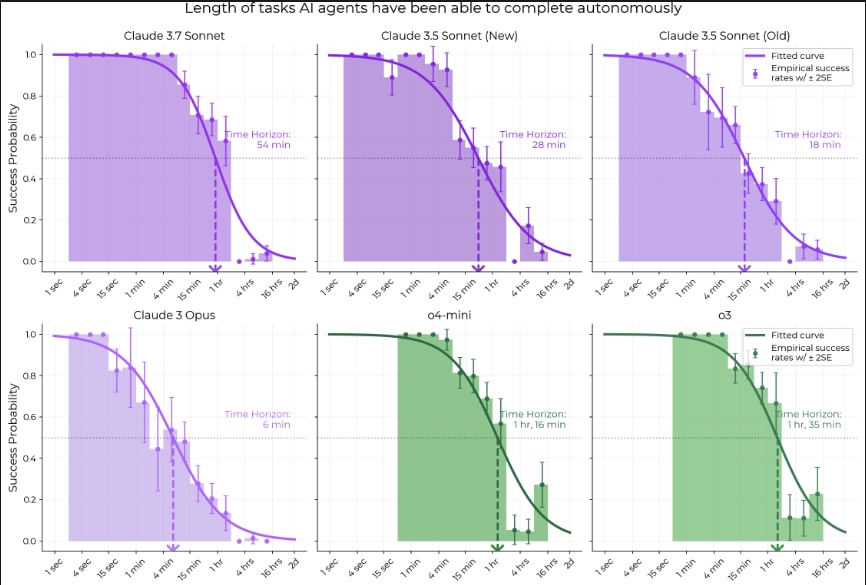
Time horizon of o3 is ~1.5 hours vs Claude 3.7's 54 minutes, and it's statistically significant that it's above the long-term trend. It's been less than 2 months since the release of Claude 3.7. If time horizon continues doubling every 3.5 months as it has over the last year, we only have another 12 months until time horizon hits 16 hours and we are unable to measure it with HCAST.
My guess is that future model time horizon will double every 3-4 months for well-defined tasks (HCAST, RE-Bench, most automatically scorable tasks) that labs can RL on, while capability on more realistic tasks will follow the long-term 7-month doubling time.
Benchmark Readiness Level
Safety-relevant properties should be ranked on a "Benchmark Readiness Level" (BRL) scale, inspired by NASA's Technology Readiness Levels. At BRL 4, a benchmark exists; at BRL 6 the benchmark is highly valid; past this point the benchmark becomes increasingly robust against sandbagging. The definitions could look something like this:
| BRL | Definition | Example |
| 1 | Theoretical relevance to x-risk defined | Adversarial competence |
| 2 | Property operationalized for frontier AIs and ASIs | AI R&D speedup; Misaligned goals |
| 3 | Behavior (or all parts) observed i |
Some versions of the METR time horizon paper from alternate universes:
Measuring AI Ability to Take Over Small Countries (idea by Caleb Parikh)
Abstract: Many are worried that AI will take over the world, but extrapolation from existing benchmarks suffers from a large distributional shift that makes it difficult to forecast the date of world takeover. We rectify this by constructing a suite of 193 realistic, diverse countries with territory sizes from 0.44 to 17 million km^2. Taking over most countries requires acting over a long time horizon, with the excep...
A few months ago, I accidentally used France as an example of a small country that it wouldn't be that catastrophic for AIs to take over, while giving a talk in France 😬
Quick list of reasons for me:
- I'm averse to attending mass protests myself because they make it harder to think clearly and I usually don't agree with everything any given movement stands for.
- Under my worldview, an unconditional pause is a much harder ask than is required to save most worlds if p(doom) is 14% (the number stated on the website). It seems highly impractical to implement compared to more common regulatory frameworks and is also super unaesthetic because I am generally pro-progress.
- The economic and political landscape around AI is complicated e
I basically agree with this. The reason the paper didn't include this kind of reasoning (only a paragraph about how AGI will have infinite horizon length) is we felt that making a forecast based on a superexponential trend would be too much speculation for an academic paper. (There is really no way to make one without heavy reliance on priors; does it speed up by 10% per doubling or 20%?) It wasn't necessary given the 2027 and 2029-2030 dates for 1-month AI derived from extrapolation already roughly bracketed our uncertainty.
External validity is a huge concern, so we don't claim anything as ambitious as average knowledge worker tasks. In one sentence, my opinion is that our tasks suite is fairly representative of well-defined, low-context, measurable software tasks that can be done without a GUI. More speculatively, horizons on this are probably within a large (~10x) constant factor of horizons on most other software tasks. We have a lot more discussion of this in the paper, especially in heading 7.2.1 "Systematic differences between our tasks and real tasks". The HCAST paper ...
Humans don't need 10x more memory per step nor 100x more compute to do a 10-year project than a 1-year project, so this is proof it isn't a hard constraint. It might need an architecture change but if the Gods of Straight Lines control the trend, AI companies will invent it as part of normal algorithmic progress and we will remain on an exponential / superexponential trend.
Regarding 1 and 2, I basically agree that SWAA doesn't provide much independent signal. The reason we made SWAA was that models before GPT-4 got ~0% on HCAST, so we needed shorter tasks to measure their time horizon. 3 is definitely a concern and we're currently collecting data on open-source PRs to get a more representative sample of long tasks.
That bit at the end about "time horizon of our average baseliner" is a little confusing to me, but I understand it to mean "if we used the 50% reliability metric on the humans we had do these tasks, our model would say humans can't reliably perform tasks that take longer than an hour". Which is a pretty interesting point.
That's basically correct. To give a little more context for why we don't really believe this number, during data collection we were not really trying to measure the human success rate, just get successful human runs and measure their time....
All models since at least GPT-3 have had this steep exponential decay [1], and the whole logistic curve has kept shifting to the right. The 80% success rate horizon has basically the same 7-month doubling time as the 50% horizon so it's not just an artifact of picking 50% as a threshold.
Claude 3.7 isn't doing better on >2 hour tasks than o1, so it might be that the curve is compressing, but this might also just be noise or imperfect elicitation.
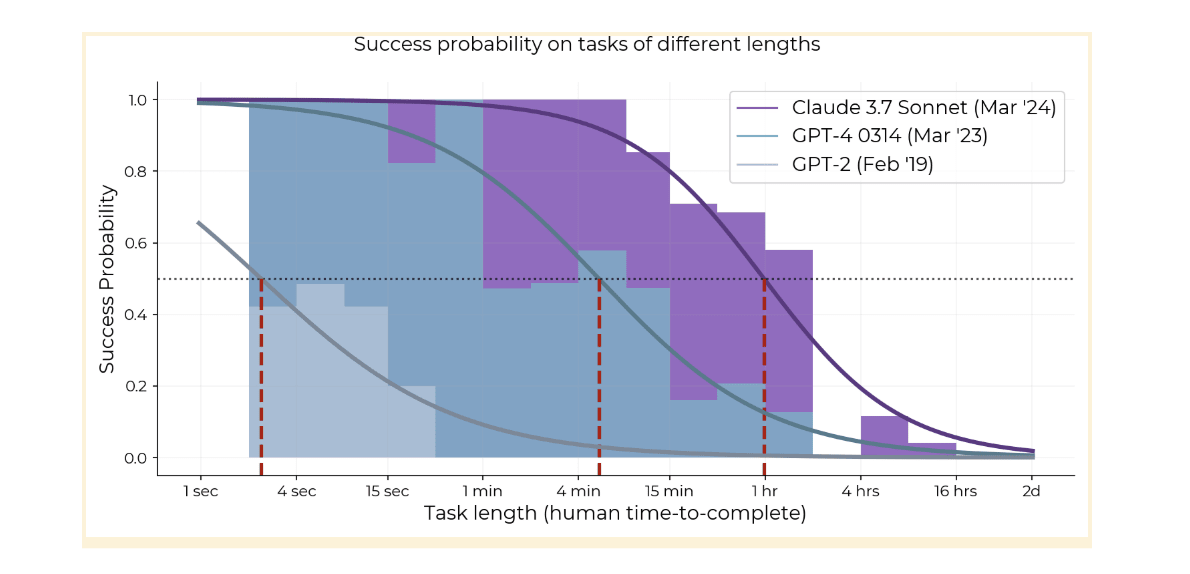
Regarding the idea that autoregressive models would plateau at hours or days, it's plausible, and one point of...
One possible interpretation here is going back to the inner-monologue interpretations as being multi-step processes with an error rate per step where only complete success is useful, which is just an exponential; as the number of steps increase from 1 to n, you get a sigmoid from ceiling performance to floor performance at chance. So you can tell the same story about these more extended tasks, which after all, are just the same sort of thing - just more so. We also see this sort of sigmoid in searching with a fixed model, in settings like AlphaZero in Hex...
It's expensive to construct and baseline novel tasks for this (we spent well over $100k on human baselines) so what we are able to measure in the future depends on whether we can harvest realistic tasks that naturally have human data. You could do a rough analysis on math contest problems, say assigning GSM8K and AIME questions lengths based on a guess of how long expert humans take, but the external validity concerns are worse than for software. For one thing, AIME has much harder topics than GSM8K (we tried to make SWAA not be artificially easier or harder than HCAST); for another, neither are particularly close to the average few minutes of a research mathematician's job.
The trend probably sped up in 2024. If the future trend follows the 2024--2025 trend, we get 50% reliability at 167 hours in 2027.
Author here. My best guess is that by around the 1-month point, AIs will be automating large parts of both AI capabilities and empirical alignment research. Inferring anything more depends on many other beliefs.
Currently no one knows how hard the alignment problem is or what exactly good alignment research means-- it is the furthest-looking, least well-defined and least tractable of the subfields of AI existential safety. This means we don't know the equivalent task length of the alignment problem. Even more importantly, we only measured the AIs at softwar...
AIs (and humans) don't have 100% reliability at anything, so the graph tracks when AIs get a 50% success rate on our dataset, over all tasks and attempts. We also measure AI horizons at 80% success rate in the paper, and those are about 5x shorter. It's hard to measure much higher than 80% with our limited task suite, but if we could we would measure 95% and 99% as well.
So the citation is an unreleased paper! That unreleased paper may make a splash, since (assuming this 7-month-doubling trend is not merely 1-2 years old) it strongly implies we really will find good solutions for turning LLMs agentic fairly soon.
The 7-month doubling trend we measured actually goes back to GPT-2 in 2019. Since 2024, the trend has been faster, doubling roughly every 3-4 months depending on how you measure, but we only have six 2024-25 models so error bars are wide and it's really unclear which trend will be predictive of the future.
Important results from the paper as I see it:
- RL agents can learn to cheat in the wild, and CoT pressure doesn't prevent it.
- The slope of cheating increase and final cheating rate are both slightly lower when applying CoT pressure, but all of the cheating will go uncaught by the monitor.
- GPT-4o can zero-shot monitor o3-level agents with 95% accuracy when it has access to CoT, only 60% when it can only monitor actions.
- If there is no CoT pressure, RL agents telegraph their cheating, such that cheating precision and recall actually go up over time for a monitor
I think we have two separate claims here:
- Do technologies that have lots of resources put into their development generally improve discontinuously or by huge slope changes?
- Do technologies often get displaced by technologies with a different lineage?
I agree with your position on (2) here. But it seems like the claim in the post that sometime in the 2030s someone will make a single important architectural innovation that leads to takeover within a year mostly depends on (1), as it would require progress within that year to be comparable to all the progress fr...
Easy verification makes for benchmarks that can quickly be cracked by LLMs. Hard verification makes for benchmarks that aren't used.
Agree, this is one big limitation of the paper I'm working on at METR. The first two ideas you listed are things I would very much like to measure, and the third something I would like to measure but is much harder than any current benchmark given that university takes humans years rather than hours. If we measure it right, we could tell whether generalization is steadily improving or plateauing.
Though the fully connected -> transformers wasn't infinite small steps, it definitely wasn't a single step. We had to invent various sub-innovations like skip connections separately, progressing from RNNs to LSTM to GPT/BERT style transformers to today's transformer++. The most you could claim is a single step is LSTM -> transformer.
Also if you graph perplexity over time, there's basically no discontinuity from introducing transformers, just a possible change in slope that might be an artifact of switching from the purple to green measurement method....
A continuous manifold of possible technologies is not required for continuous progress. All that is needed is for there to be many possible sources of improvements that can accumulate, and for these improvements to be small once low-hanging fruit is exhausted.
Case in point: the nanogpt speedrun, where the training time of a small LLM was reduced by 15x using 21 distinct innovations which touched basically every part of the model, including the optimizer, embeddings, attention, other architectural details, quantization, hyperparameters, code optimizations, ...
I think eating the Sun is our destiny, both in that I expect it to happen and that I would be pretty sad if we didn't; I just hope it will be done ethically. This might seem like a strong statement but bear with me
Our civilization has undergone many shifts in values as higher tech levels have indicated that sheer impracticality of living a certain way, and I feel okay about most of these. You won't see many people nowadays who avoid being photographed because photos steal a piece of their soul. The prohibition on women working outside the home, common in m...
Will we ever have Poké Balls in real life? How fast could they be at storing and retrieving animals? Requirements:
- Made of atoms, no teleportation or fantasy physics.
- Small enough to be easily thrown, say under 5 inches diameter
- Must be able to disassemble and reconstruct an animal as large as an elephant in a reasonable amount of time, say 5 minutes, and store its pattern digitally
- Must reconstruct the animal to enough fidelity that its memories are intact and it's physically identical for most purposes, though maybe not quite to the cellular level
- No external
and yet, the richest person is still only responsible for 0.1%* of the economic output of the united states.
Musk only owns 0.1% of the economic output of the US but he is responsible for more than this, including large contributions to
- Politics
- Space
- SpaceX is nearly 90% of global upmass
- Dragon is the sole American spacecraft that can launch humans to ISS
- Starlink probably enables far more economic activity than its revenue
- Quality and quantity of US spy satellites (Starshield has ~tripled NRO satellite mass)
- Startup culture through the many startups from ex-Spac
Cassidy Laidlaw published a great paper at ICLR 2025 that proved (their Theorem 5.1) that (proxy reward - true reward) is bounded given a minimum proxy-true correlation and a maximum chi-squared divergence on the reference policy. Basically, chi-squared divergence works where KL divergence doesn't.
Using this in practice for alignment is still pretty restrictive-- the fact that the new policy can’t be exponentially more likely to achieve any state than the reference policy means this will probably only be useful in cases where the reference policy is already intelligent/capable.