All of Towards_Keeperhood's Comments + Replies
Thx.
Seems like an important difference here is that you’re imagining train-then-deploy whereas I’m imagining continuous online learning. So in the model I’m thinking about, there isn’t a fixed set of “reward data”, rather “reward data” keeps coming in perpetually, as the agent does stuff.
I don't really imagine train-then-deploy, but I think that (1) when the AI becomes coherent enough it will prevent getting further value drift, and (2) the AI eventually needs to solve very hard problems where we won't have sufficient understanding to judge whether what the AI did is actually good.
Thanks! It's nice that I'm learning more about your models.
I’ve gone back and forth about whether I should be thinking more about (A) “egregious scheming followed by violent takeover” versus (B) more subtle things e.g. related to “different underlying priors for doing philosophical value reflection”.
(A) seems much more general than what I would call "reward specification failure".
The way I use "reward specification" is:
- If the AI has as goal "get reward" (or sth else) rather than "whatever humans want" because it better fits the reward data, then it's a rew
Stuff I noticed so far from thinking about this:
- Sensation of desire for closure.
- Desire to appear smart (mostly in front of people with very good epistemics, where incentives are relatively aligned to truth-oriented thinking and criticizing others and changing one's mind is incentivized but not overincentivized, but still).
- When I think of a (new) piece of evidence/argument, my mind often initially over-updates into that direction for a minute or so, until I have integrated it into my overall model. (This happens in both directions. Aka I think my intuitive
The problem of finding a good representation of abstract thoughts
As background, here's a simple toy model of thinking:
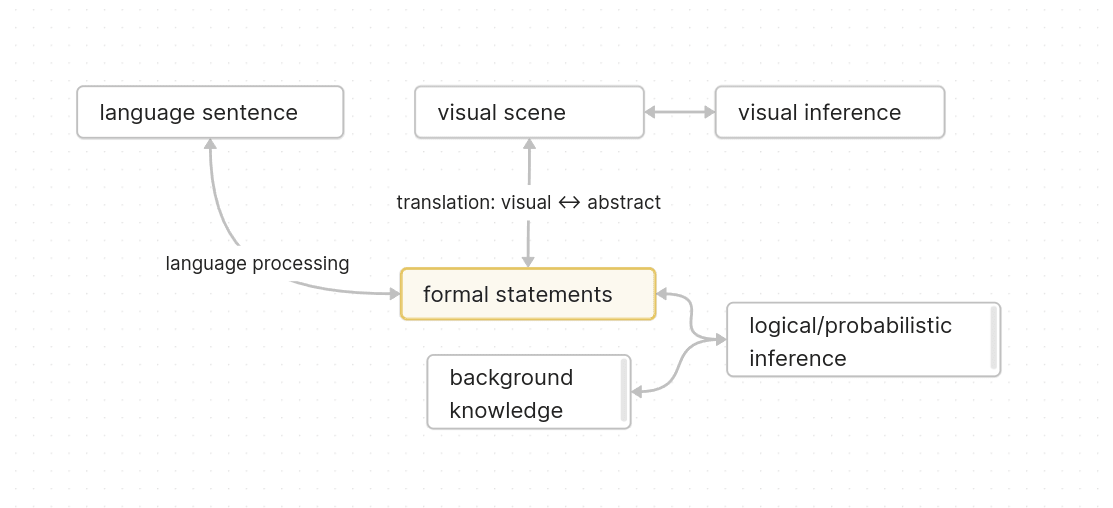
The goal is to find a good representation of the formal statements (and also the background knowledge) in the diagram.
The visual angle is sorta difficult, so the two easy criteria for figuring out what a good representation is, are:
1. Correspondance to language sentences
2. Well suited to do logical/probabilistic inference
The second criterion is often neglected. People in semantics often just take language sentences and see how they ca...
...I disagree. I think you’re overgeneralizing from RL algorithms that don’t work very well (e.g. RLHF), to RL algorithms that do work very well, like human brains or the future AI algorithms that I think Sutton & Silver have in mind.
For example, if I apply your logic there to humans 100,000 years ago, it would fail to predict the fact that humans would wind up engaging in activities like: eating ice cream, playing video games, using social media, watching television, raising puppies, virtual friends, fentanyl, etc. None of those things are “a complex pro
...
- If the user types “improve my fitness” into some interface, and it sets the AI’s reward function to be some “function of the user’s heart rate, sleep duration, and steps taken”, then the AI can potentially get a higher reward by forcing the user into eternal cardio training on pain of death, including forcibly preventing the person from turning off the AI, or changing its goals (see §2.2 above).
- The way that the reward function operationalizes “steps taken” need not agree with what we had in mind. If it’s operationalized as steps registered on a wearable tr
I don't quite like "Turbocharging" as a name because it suggests too little about the content. Better might e.g. be "the directness principle".
(IIRC Directness is also one of the ultralearning principles from Scott Young and I guess it describes the same thing, but I don't remember.)
discussion of exercises of the probability 2 lecture starts mid episode 104.
Btw, just reading through everything from "dath ilan" might also be interesting: https://www.glowfic.com/replies/search?board_id=&author_id=&template_id=&character_id=11562&subj_content=&sort=created_old&commit=Search
Asmodia figuring out Keltham's probability riddles may also be interesting, though perhaps less so than the lectures. It starts episode 90. Starting quote is "no dath ilani out of living memory would've seen the phenomenon". The story unfortunately switches between Asmodia+Ione, Carrissa(+Peranza I think), and Keltham+Meritxell. You can skip the other stuff that's going on there (though the brief "dath ilan" reply about stocks might be interesting too).
Thanks!
If the value function is simple, I think it may be a lot worse than the world-model/thought-generator at evaluating what abstract plans are actually likely to work (since the agent hasn't yet tried a lot of similar abstract plans from where it could've observed results, and the world model's prediction making capabilities generalize further). The world model may also form some beliefs about what the goals/values in a given current situation are. So let's say the thought generator outputs plans along with predictions about those plans, and some of th...
Note that the "Probability 2" lecture continues after the lunch break (which is ~30min skippable audio).
Thanks!
Sorry, I think I intended to write what I think you think, and then just clarified my own thoughts, and forgot to edit the beginning. Sorry, I ought to have properly recalled your model.
Yes, I think I understand your translations and your framing of the value function.
Here are the key differences between a (more concrete version of) my previous model and what I think your model is. Please lmk if I'm still wrongly describing your model:
- plans vs thoughts
- My previous model: The main work for devising plans/thoughts happens in the world-model/thought-gen
Why two?
Mathematics/logical-truths are true in all possible worlds, so they never tell you in what world you are.
If you want to say something that is true in your particular world (but not necessarily in all worlds), you need some observations to narrow down what world you are in.
I don't know how closely this matches the use in the sequence, but I think a sensible distinction between logical and causal pinpointing is: All the math parts of a statement are "logically pinpointed" and all the observation parts are "causally pinpointed".
So basically, I think i...
Thanks for clarifying.
I mean I do think it can happen in my system that you allocate an object for something that's actually 0 or >1 objects, and I don't have a procedure for resolving such map-territory mismatches yet, though I think it's imaginable to have a procedure that defines new objects and tries to edit all the beliefs associated with the old object.
I definitely haven't described how we determine when to create a new object to add to our world model, but one could imagine an algorithm checking when there's some useful latent for explaining some...
Thx.
Yep there are many trade-offs between criteria.
Btw, totally unrelatedly:
I think in the past on your abstraction you probably lost a decent amount of time from not properly tracking the distinction between (what I call) objects and concepts. I think you likely at least mostly recovered from this, but in case you're not completely sure you've fully done so you might want to check out the linked section. (I think it makes sense to start by understanding how we (learn to) model objects and only look at concepts later, since minds first learn to model objec...
Thanks.
I'm still not quite understanding what you're thinking though.
For other objects, like physical ones, quantifiers have to be used. Like "at least one" or "the" (the latter only presupposes there is exactly one object satisfying some predicate). E.g. "the cat in the garden". Perhaps there is no cat in the garden or there are several. So it (the cat) cannot be logically represented with a constant.
"the" supposes there's exactly one canonical choice for what object in the context is indicated by the predicate. When you say "the cat" there's basically al...
...I think object identification is important if we want to analyze beliefs instead of sentences. For beliefs we can't take a third person perspective and say "it's clear from context what is meant". Only the agent knows what he means when he has a belief (or she). So the agent has to have a subjective ability to identify things. For "I" this is unproblematic, because the agent is presumably internal and accessible to himself and therefore can be subjectively referred to directly. But for "this" (and arguably also for terms like "tomorrow") the referred objec
Yep I did not cover those here. They are essentially shortcodes for identifying objects/times/locations from context. Related quote:
E.g. "the laptop" can refer to different objects in different contexts, but when used it's usually clear which object is meant. However, how objects get identified does not concern us here - we simply assume that we know names for all objects and use them directly.
("The laptop" is pretty similar to "This laptop".)
(Though "this" can also act as complementizer, as in "This is why I didn't come", though I think in that function it doesn't count as indexical. The section related to complementizers is the "statement connectives" section.)
“Outer alignment” entails having a ground-truth reward function that spits out rewards that agree with what we want. “Inner alignment” is having a learned value function that estimates the value of a plan in a way that agrees with its eventual reward.
I guess just briefly want to flag that I think this summary of inner-vs-outer alignment is confusing in a way that it sounds like one could have a good enough ground-truth reward and then that just has to be internalized.
I think this summary is better: 1. "The AGI was doing the wrong thing but got rewarded anyway (or doing the right thing but got punished)". 2. Something else went wrong [not easily compressible].
Sounds like we probably agree basically everywhere.
Yeah you can definitely mark me down in the camp of "not use 'inner' and 'outer' terminology". If you need something for "outer", how about "reward specification (problem/failure)".
ADDED: I think I probably don't want a word for inner-alignment/goal-misgeneralization. It would be like having a word for "the problem of landing a human on the moon, except without the part of the problem where we might actively steer the rocket into wrong directions".
...I just don’t use the term “utility function” at all in this
Thanks.
Yeah I guess I wasn't thinking concretely enough. I don't know whether something vaguely like what I described might be likely or not. Let me think out loud a bit about how I think about what you might be imagining so you can correct my model. So here's a bit of rambling: (I think point 6 is most important.)
- As you described in you intuitive self-models sequence, humans have a self-model which can essentially have values different from the main value function, aka they can have ego-dystonic desires.
- I think in smart reflective humans, the policy sugge
Thanks!
Another thing is, if the programmer wants CEV (for the sake of argument), and somehow (!!) writes an RL reward function in Python whose output perfectly matches the extent to which the AGI’s behavior advances CEV, then I disagree that this would “make inner alignment unnecessary”. I’m not quite sure why you believe that.
I was just imagining a fully omnicient oracle that could tell you for each action how good that action is according to your extrapolated preferences, in which case you could just explore a bit and always pick the best action accordin...
Note: I just noticed your post has a section "Manipulating itself and its learning process", which I must've completely forgotten since I last read the post. I should've read your post before posting this. Will do so.
“Outer alignment” entails having a ground-truth reward function that spits out rewards that agree with what we want. “Inner alignment” is having a learned value function that estimates the value of a plan in a way that agrees with its eventual reward.
Calling problems "outer" and "inner" alignment seems to suggest that if we solved both we've s...
I'd suggest not using conflated terminology and rather making up your own.
Or rather, first actually don't use any abstract handles at all and just describe the problems/failure-modes directly, and when you're confident you have a pretty natural breakdown of the problems with which you'll stick for a while, then make up your own ontology.
In fact, while in your framework there's a crisp difference between ground-truth reward and learned value-estimator, it might not make sense to just split the alignment problem in two parts like this:
...“Outer alignment” entai
Ah, thx! Will try.
If I did, I wouldn't publicly say so.
It's of course not yes or no, but just a probability, but in case it's high I might not want to state it here, so I should generally not state it here, so you cannot infer it is high by the fact that I didn't state it here.
I can say though that I only turned 22y last week and I expect my future self to grow up to become much more competent than I am now.
2. I mentioned that there should be much more impressive behavior if they were that smart; I don't recall us talking about that much, not sure.
You said "why don't they e.g. jump in prime numbers to communicate they are smart?" and i was like "hunter gatherer's don't know prime numbers and perhaps not even addition" and you were like "fair".
I mean I thought about what I'd expect to see, but I unfortunately didn't really imagine them as smart but just as having a lot of potential but being totally untrained.
...3. I recommended that you try hard to invent hypoth
Yes human intelligence.
I forgot to paste in that it's a follow up to my previous posts. Will do now.
In general, I wish this year? (*checks* huh, only 4 months.)
Nah I didn't loose that much time. I already quit the project end of January, I just wrote the post now. Most of the technical work was also pretty useful for understanding language, which is a useful angle on agent foundations. I had previously expected working on that angle to be 80% as effective as my previous best plan, but it was even better, around similarly good I think. That was like 5-5.5 weeks and that was not wasted.
I guess I spent like 4.5 weeks overall on learning about orcas (includi...
Yeah I think I came to agree with you. I'm still a bit confused though because intuitively I'd guess chimps are dumber than -4.4SD (in the interpretation for "-4.4SD" I described in my other new comment).
When you now get a lot of mutations that increase brain size, while this contributes to smartness, this also pulls you away from the species median, so the hyperparameters are likely to become less well tuned, resulting in a countereffect that also makes you dumber in some ways.
Actually maybe the effect I am describing is relatively small as long as the variation in brain size is within 2 SDs or so, which is where most of the data pinning down the 0.3 correlation comes from.
So yeah it's plausible to me that your method of estimating is ok.
Intuitively I had...
Thanks for describing a wonderfully concrete model.
I like that way you reason (especially the squiggle), but I don't think it works quite that well for this case. But let's first assume it does:
Your estimamtes on algorithmic efficiency deficits of orca brains seem roughly reasonable to me. (EDIT: I'd actually be at more like -3.5std mean with standard deviation of 2std, but idk.)
Number cortical neurons != brain size. Orcas have ~2x the number of cortical neurons, but much larger brains. Assuming brain weight is proportional to volume, with human brains bei...
Thanks for the suggestion, though I don't think they are smart enough to get far with grammar. No non-cetaceans non-humans seem to be.
One possibility is to try it with bottlenose dolphins (or beluga whales). (Bottlenose dolphins have shown greater capacity to learn grammar than great apes.[1]) Those are likely easier to get research access to than orcas. I think we might get some proof of concept of the methodology there, though I'm relatively pessimistic about them learning a full language well.
- ^
See the work of Louis Herman in the 80s (and 90s)
By >=+6std I mean potential of how smart they could be if they were trained similarly to us, not actual current intelligence. Sorry I didn't write this in this post, though I did in others.
I'd be extremely shocked if orcas were actually that smart already. They don't have science and they aren't trained in abstract reasoning.
Like, when an orca is +7std, he'd be like a +7std hunter gatherer human, who is probably not all that good at abstract reasoning tasks (like learning a language through brute-force abstract pattern recognition). (EDIT: Ok actually i...
Thanks for letting me know it sounded like that. I definitely know it isn't legible at all, and I didn't expect readers to buy it, just wanted to communicate that that's how it's from my own perspective.
You're right. I'll edit the post.
Considerations on intelligence of wild orcas vs captive orcas
I've updated to thinking it's relatively likely that wild orcas are significantly smarter than captive orcas, because (1) wild orcas might learn proper language and captive orcas don't, and (2) generally orcas don't have much to learn in captivity, causing their brains to be underdeveloped.
Here are the most relevant observations:
- Observation 1: (If I analyzed the data correctly and the data is correct,) all orcas currently alive in captivity have been either born in captivity or captured when they
Seems totally unrelated to my post but whatever:
My p(this branch of humanity won't fulfill the promise of the night sky) is actually more like 0.82 or sth, idk. (I'm even lower on p(everyone will die), because there might be superintelligences in other branches that acausally trade to save the existing lives, though I didn't think about it carefully.)
I'm chatting 1 hour every 2 weeks with Erik Jenner. We usually talk about AI safety stuff. Otherwise also like 1h every 2 weeks with a person who has sorta similar views to me. Otherwise I currently don't talk much to people about AI risk.
ok edited to sun. (i used earth first because i don't know how long it will take to eat the sun, whereas earth seems likely to be feasible to eat quickly.)
(plausible to me that an aligned AI will still eat the earth but scan all the relevant information out of it and later maybe reconstruct it.)
ok thx, edited. thanks for feedback!
(That's not a reasonable ask, it intervenes on reasoning in a way that's not an argument for why it would be mistaken. It's always possible a hypothesis doesn't match reality, that's not a reason to deny entertaining the hypothesis, or not to think through its implications. Even some counterfactuals can be worth considering, when not matching reality is assured from the outset.)
Yeah you can hypothesize. If you state it publicly though, please make sure to flag it as hypothesis.
How long until the earth gets eaten? 10th/50th/90th percentile: 3y, 12y, 37y.
Catastrophes induced by narrow capabilities (notably biotech) can push it further, so this might imply that they probably don't occur.
No it doesn't imply this, I set this disclaimer "Conditional on no strong governance success that effectively prevents basically all AI progress, and conditional on no huge global catastrophe happening in the meantime:". Though yeah I don't particularly expect those to occur.
...Will we get to this point by incremental progress that yields smallish improvements (=slow), or by some breakthrough that when scaled up can rush past the human intelligence level very quickly (=fast)?
AI speed advantage makes fast vs. slow ambiguous, because it doesn't require AI getting smarter in order to make startlingly fast progress, and might be about passing a capability threshold (of something like autonomous research) with no distinct breakthroughs leading up to it (by getting to a slightly higher level of scaling or compute efficiency with some o
My AI predictions
(I did not carefully think about my predictions. I just wanted to state them somewhere because I think it's generally good to state stuff publicly.)
(My future self will not necessarily make similar predictions as I am now.)
TLDR: I don't know.
Timelines
Conditional on no strong governance success that effectively prevents basically all AI progress, and conditional on no huge global catastrophe happening in the meantime:
How long until the sun (starts to) get eaten? 10th/50th/90th percentile: 3y, 12y, 37y.
How long until an AI reaches Elo 4000 o...
Here's my current list of lessons for review. Every day during my daily review, I look at the lessons in the corresponding weekday entry and the corresponding day of the month, and for each list one example from the last week where I could've applied the lesson, and one example where I might be able to apply the lesson in the next week:
...
- Mon
- get fast feedback. break tasks down into microtasks and review after each.
- Tue
- when surprised by something or took long for something, review in detail how you might've made the progress faster.
- clarify why the progress is g
Thank you for your feedback! Feedback is great.
We can try to select for AIs that outwardly seem friendly, but on anything close to our current ignorance about their cognition, we cannot be nearly confident that an AI going through the intelligence explosion will be aligned to human values.
It means that we have only very little understanding of how and why AIs like ChatGPT work. We know almost nothing about what's going on inside them that they are able to give useful responses. Basically all I'm saying here is that we know so little that it's hard to be co...
Here's my pitch for very smart young scientists for why "Rationality from AI to Zombies" is worth reading:
...The book "Rationality: From AI to Zombies" is actually a large collection of blogposts, which covers a lot of lessons on how to become better at reasoning. It also has a lot of really good and useful philosophy, for example about how Bayesian updating is the deeper underlying principle of how science works.
But let me express in more detail why I think "Rationality: A-Z" is very worth reading.
Human minds are naturally bad at deducing correct beliefs/the
Thanks.
Yeah I think the parts of my comment where I treated the value function as making predictions on how well a plan works were pretty confused. I agree it's a better framing that plans proposed by the thought generator include predicted outcomes and the value function evaluates on those. (Maybe I previously imagined the thought generator more like proposing actions, idk.)
So yeah I guess what I wrote was pretty confusing, though I still have some concerns here.
Let's look at how an agent might accomplish a very difficult goal, where the agent didn't acco... (read more)