All of worse's Comments + Replies
Edited title to make it more clear this is a link post and that I don’t necessarily endorse the title.
Re: AI safety summit, one thought I have is that the first couple summits were to some extent captured by the people like us who cared most about this technology and the risks. Those events, prior to the meaningful entrance of governments and hundreds of billions in funding, were easier to 'control' to be about the AI safety narrative. Now, the people optimizing generally for power have entered the picture, captured the summit, and changed the narrative for the dominant one rather than the niche AI safety one. So I don't see this so much as a 'stark reversal' so much as a return to status quo once something went mainstream.
xAI's new planned scaleup follows one more step on the training compute timeline from Situational Awareness (among other projections, I imagine)
From ControlAI newsletter:
"xAI has announced plans to expand its Memphis supercomputer to house at least 1,000,000 GPUs. The supercomputer, called Collosus, already has 100,000 GPUs, making it the largest AI supercomputer in the world, according to Nvidia."
Unsure if it's built by 2026 but seems plausible based on quick search.
https://www.reuters.com/technology/artificial-intelligence/musks-xai-plans-massive-expansi...
Something I'm worried about now is some RFK Jr/Dr. Oz equivalent being picked to lead on AI...
Realized I didn't linkpost on lesswrong, only forum - link to Reuters:
https://www.reuters.com/technology/artificial-intelligence/us-government-commission-pushes-manhattan-project-style-ai-initiative-2024-11-19/
From Reuters:
"We've seen throughout history that countries that are first to exploit periods of rapid technological change can often cause shifts in the global balance of power," Jacob Helberg, a USCC commissioner and senior advisor to software company Palantir's CEO, told Reuters.
I think it is true that (setting aside AI risk concerns), the US gov should, the moment it recognizes AGI (smarter than human AI) is possible, pursue it. It's the best use of resources, could lead to incredible economic/productivity/etc. growth, could lead to a decisive adv...
Yeah oops, meant long
A quick OpenAI-o1 preview BOTEC for additional emissions from a sort of Leopold scenario ~2030, assuming energy is mostly provided by natural gas, since I was kinda curious. Not much time spent on this and took the results at face value. I (of course?) buy that emissions don't matter in short term, in a world where R&D is increasingly automated and scaled.
Phib:
Say an additional 20% of US electricity was added to our power usage (e.g. for AI) over the next 6 years, and it was mostly natural gas.
Also, that AI inference is used at an increasing rate...
I (of course?) buy that emissions don't matter in short term
Emissions don't matter in the long term, ASI can reshape the climate (if Earth is not disassembled outright). They might matter before ASI, especially if there is an AI Pause. Which I think is still a non-negligible possibility if there is a recoverable scare at some point; probably not otherwise. Might be enforceable by international treaty through hobbling semiconductor manufacturing, if AI of that time still needs significant compute to adapt and advance.
I have a guess that this:
"require that self-improving software require human intervention to move forward on each iteration"
is the unspoken distinction occurring here, how constant the feedback loop is for self-improvement.
So, people talk about recursive self-improvement, but mean two separate things, one is recursive self-improving models that require no human intervention to move forward on each iteration (perhaps there no longer is an iterative release process, the model is dynamic and constantly improving), and the other is somewhat the current s...
Beautiful, thanks for sharing
Benchmarks are weird, imagine comparing a human only along their ability to take a test. Like saying, how do we measure einstein? in his avility to take a test. Someone else who completes that test therefore IS Einstein (not necessarily at all, you can game tests, in ways that aren't 'cheating', just study the relevant material (all the online content ever).
LLM's ability to properly guide someone through procedures is actually the correct way to evaluate language models. Not written description or solutions, but step by step guiding someone through something impressive, Can the model help me make a
Or even without a human, step by step completing a task.
(Cross comment from EAF)
Thank you for making the effort to write this post.
Reading Situational Awareness, I updated pretty hardcore into national security as the probable most successful future path, and now find myself a little chastened by your piece, haha [and just went around looking at other responses too, but yours was first and I think it's the most lit/evidence-based]. I think I bought into the "Other" argument for China and authoritarianism, and the ideal scenario of being ahead in a short timeline world so that you don't have to even concer...
Agree that this is a cool list, thanks, excited to come back to it.
I just read Three Body Problem and liked it, but got the same sense where the end of the book lost me a good deal and left a sour taste. (do plan to read sequels tho!)
Reminds me of this trend: https://mashable.com/article/chatgpt-make-it-more In which people ask dalle to make images generated more whatever quality. More swiss, bigger water bottle, and eventually you get ‘spirituality’ or meta as the model tries its best to take a step up each time.
Also, I feel like the context being added to the prompt, as you go on in the context window and it takes some previous details from your conversation, is warbled and further prompts warbling.
Honestly, maybe further controversial opinion, but this [30 million for a board seat at what would become the lead co. for AGI, with a novel structure for nonprofit control that could work?] still doesn't feel like necessarily as bad a decision now as others are making it out to be?
The thing that killed all value of this deal was losing the board seat(s?), and I at least haven't seen much discussion of this as a mistake.
I'm just surprised so little prioritization was given to keeping this board seat, it was probably one of the most important assets of the ...
“they serendipitously chose guinea pigs, the one animal besides human beings and monkeys that requires vitamin C in its diet.“
This recent post I think describes this same phenomena but not from the same level of ‘necessity’ as, say, cures to big problems. Kinda funny too: https://www.lesswrong.com/posts/oA23zoEjPnzqfHiCt/there-is-way-too-much-serendipity.
So here was my initial quick test, I haven't spent much time on this either, but have seen the same images of faces on subreddits etc. and been v impressed. I think asking for emotions was a harder challenge vs just making a believable face/hand, oops
I really appreciate your descriptions of the distinctive features of faces and of pareidolia, and do agree that faces are more often better represented than hands, specifically hands often have the more significant/notable issues (misshapen/missing/overlapped fingers). Versus with faces where there's nothing a...
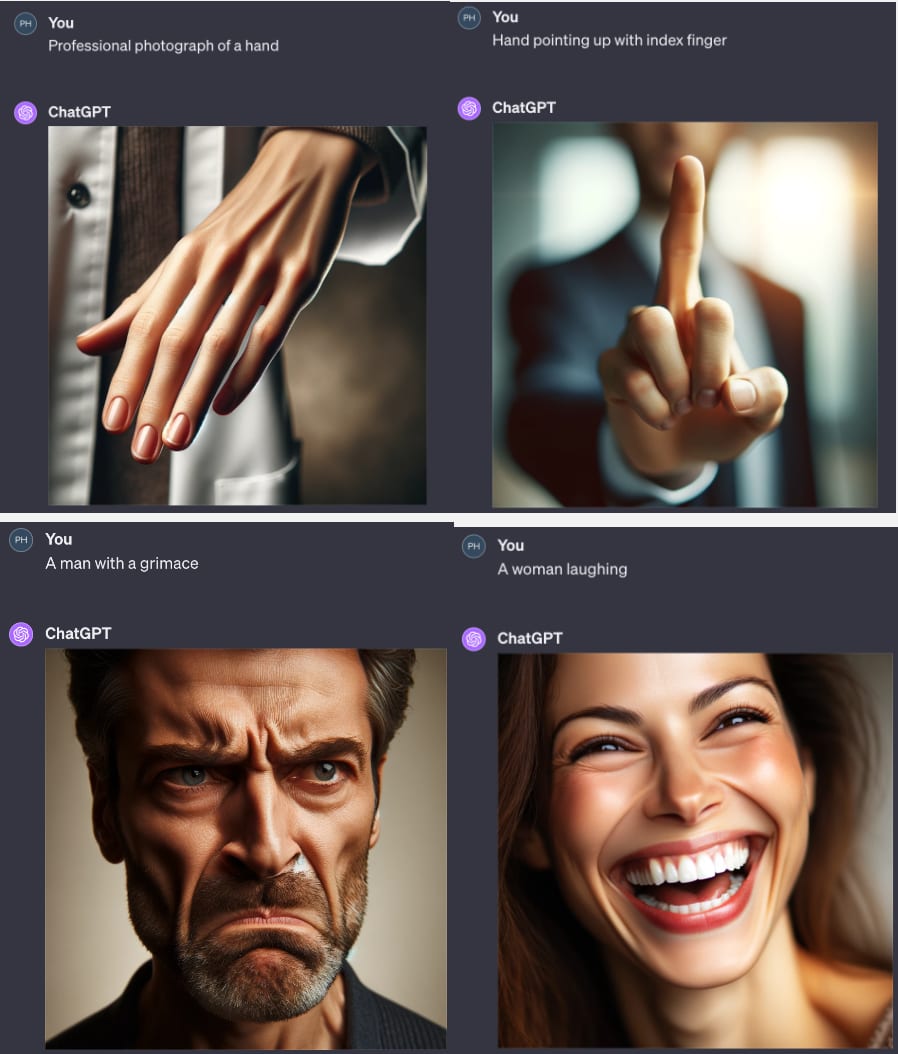
I think if this were true, then it would also hold that faces are done rather poorly right now which, maybe? Doing some quick tests, yeah, both faces and hands at least on Dalle-3 seem to be similar levels of off to me.
Wow, I’m impressed it caught itself, was just trying to play with that 3 x 3 problem too. Thanks!
I don’t know [if I understand] full rules so don’t know if this satisfies, but here:
https://chat.openai.com/share/0089e226-fe86-4442-ba07-96c19ac90bd2
Kinda commenting on stuff like “Please don’t throw your mind away” or any advice not to fully defer judgment to others (and not intending to just straw man these! They’re nuanced and valuable, just meaning to next step it).
In my circumstance and I imagine many others who are young and trying to learn and trying to get a job, I think you have to defer to your seniors/superiors/program to a great extent, or at least to the extent where you accept or act on things (perform research, support ops) that you’re quite uncertain about.
Idk there’s a lot more nuance ...
I don’t mean to present myself as the “best arguments that could be answered here” or at all representative of the alignment community. But just wanted to engage. I appreciate your thoughts!
Well, one argument for potential doom doesn’t necessitate an adversarial AI, but rather people using increasingly powerful tools in dumb and harmful ways (in the same class of consideration for me as nuclear weapons; my dumb imagined situation of this is a government using AI to continually scale up surveillance and maybe we eventually get to a position like in 1984)
Ano...
Idk the public access of some of these things, like with nonlinear's recent round, but seeing a lot of apps there and organized by category, reminded me of this post a little bit.
edit - in terms of seeing what people are trying to do in the space. Though I imagine this does not capture the biggest players that do have funding.
btw small note that I think accumulations of grant applications are probably pretty good sources of info.
low commit here but I've previously used nanotech as an example (rather than a probable outcome) of a class somewhat known unknowns - to portray possible future risks that we can imagine as possible while not being fully conceived. So while grey goo might be unlikely, it seems that precursor to grey goo of a pretty intelligent system trying to mess us up is the thing to be focused on, and this is one of its many possibilities that we can even imagine
I rather liked this post (and I’ll put it on both EAF and LW versions)
https://www.lesswrong.com/posts/PQtEqmyqHWDa2vf5H/a-quick-guide-to-confronting-doom
Particularly the comment by Jakob Kraus reminded me that many people have faced imminent doom (not of human species, but certainly quite terrible experiences).
Hi, writing this while on the go but just throwing it out there, this seems to be Sam Altman’s intent with OpenAI in pursuing fast timelines with slow takeoffs.
I am unaware of those decisions at the time. I imagine people are some degree of ‘making decisions under uncertainty’, even if that uncertainty could be resolved by info somewhere out there. Perhaps there’s some optimization of how much time you spend looking into something and how right you could expect to be?
Anecdote of me (not super rationalist-practiced, also just at times dumb) - I sometimes discover stuff I briefly took to be true in passing to be false later. Feels like there’s an edge of truth/falsehoods that we investigate pretty loosely but still use a heuristic of some valence of true/false maybe a bit too liberally at times.
Thanks for writing this, enjoyed it. I was wondering how to best represent this to other people, perhaps with an example of 5 and 10 where you let a participant make the mistake, and then question their reasoning etc. lead them down the path laid out in your post of rationalization after the decision before finally you show them their full thought process in post. I could certainly imagine myself doing this and I hope I’d be able to escape my faulty reasoning…
As a frequent pedestrian/bicyclist, I rather prefer Waymos; they’re more predictable, and you can kind of take advantage of knowing they’ll stop for you if you’re (respectfully) j-walking.
In retrospect, not surprising, but I thought worth noting.