All of Xodarap's Comments + Replies
This seems plausible to me but I could also imagine the opposite being true: my working memory is way smaller than the context window of most models. LLMs would destroy me at a task which "merely" required you to memorize 100k tokens and not do any reasoning; I would do comparatively better at a project which was fairly small but required a bunch of different steps.
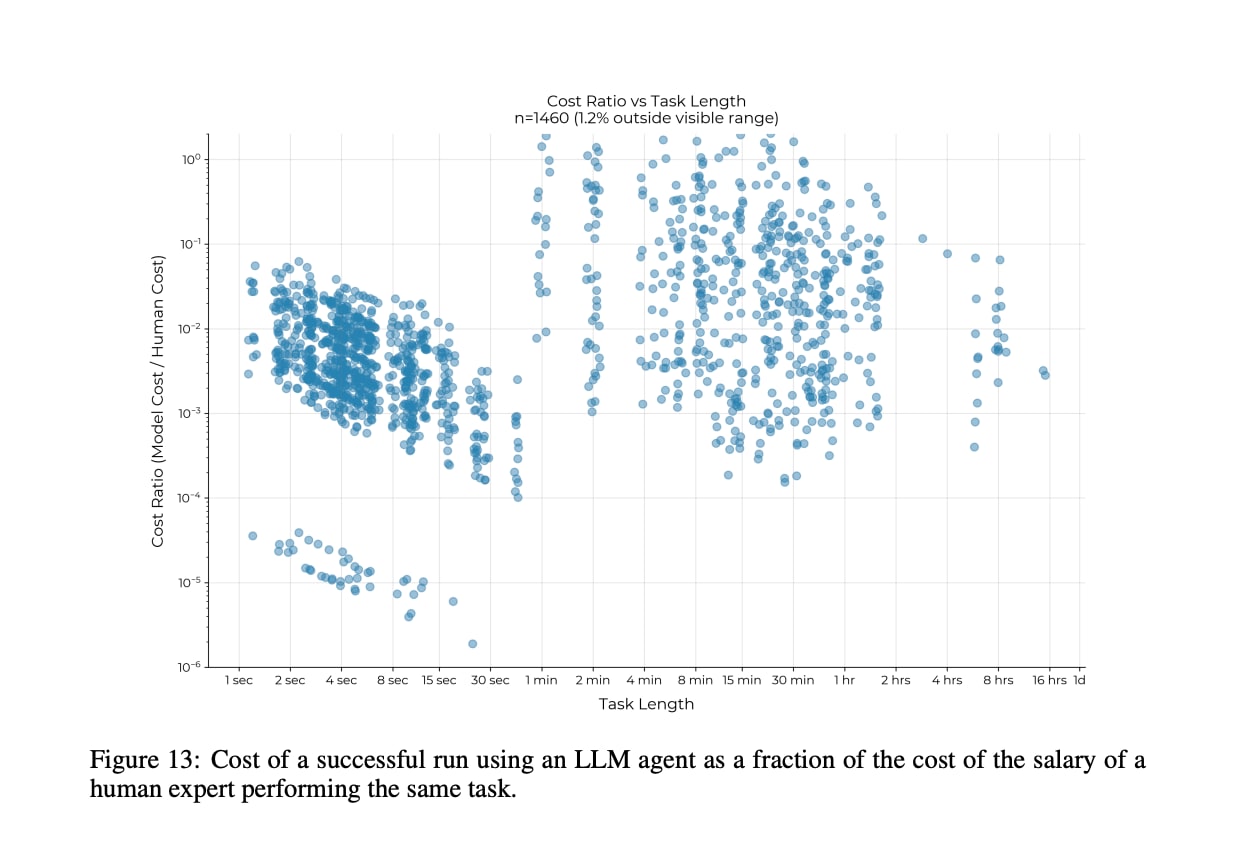
The METR report you cite finds that LLMs are vastly cheaper than humans when they do succeed, even for longer tasks:
The ARC-AGI results you cite feel somewhat hard to interpret: they may indicate that the very first models with some capability will be extremely expensive to run, but don't necessarily mean that human-level performance will forever be expensive.
I think the claim is that things with more exposure to AI are more expensive.
Thanks!
You said
If you "withdraw from a cause area" you would expect that if you have an organization that does good work in multiple cause areas, then you would expect you would still fund the organization for work in cause areas that funding wasn't withdrawn from. However, what actually happened is that Open Phil blacklisted a number of ill-defined broad associations and affiliations, where if you are associated with a certain set of ideas, or identities or causes, then no matter how cost-effective your other work is, you cannot get funding from OP
I'm wonder...
I don't have a long list, but I know this is true for Lightcone, SPARC, ESPR, any of the Czech AI-Safety/Rationality community building stuff, and I've heard a bunch of stories since then from other organizations that got pretty strong hints from Open Phil that if they start working in an area at all, they might lose all funding (and also, the "yes, it's more like a blacklist, if you work in these areas at all we can't really fund you, though we might make occasional exceptions if it's really only a small fraction of what you do" story was confirmed to me by multiple OP staff, so I am quite confident in this, and my guess is OP staff would be OK with confirming to you as well if you ask them).
what actually happened is that Open Phil blacklisted a number of ill-defined broad associations and affiliations
is there a list of these somewhere/details on what happened?
You can see some of the EA Forum discussion here: https://forum.effectivealtruism.org/posts/foQPogaBeNKdocYvF/linkpost-an-update-from-good-ventures?commentId=RQX56MAk6RmvRqGQt
The current list of areas that I know about are:
- Anything to do with the rationality community ("Rationality community building")
- Anything to do with moral relevance of digital minds
- Anything to do with wild animal welfare and invertebrate welfare
- Anything to do with human genetic engineering and reproductive technology
- Anything that is politically right-leaning
There are a bunc...
Thanks for writing this up! I wonder how feasible it is to just do a cycle of bulking and cutting and then do one of body recomposition and compare the results. I expect that the results will be too close to tell a difference, which I guess just means that you should do whichever is easier.
I think it would be helpful for helping others calibrate, though obviously it's fairly personal.
Possibly too sensitive, but could you share how the photos performed on Photfeeler? Particularly what percentile attractiveness?
Sure, I think everyone agrees that marginal returns to labor diminish with the number of employees. John's claim though was that returns are non-positive, and that seems empirically false.
We have Wildeford's Third Law: "Most >10 year forecasts are technically also AI forecasts".
We need a law like "Most statements about the value of EA are technically also AI forecasts".
Yep that's fair, there is some subjectivity here. I was hoping that the charges from SDNY would have a specific amount that Sam was alleged to have defrauded, but they don't seem to.
Regarding $4B missing: adding in Anthropic gets another $4B on the EA side of the ledger, and founders pledge another $1B. The value produced by Anthropic is questionable, and maybe negative of course, but I think by the strict definition of "donated or built in terms of successful companies" EA comes out ahead.
(And OpenAI gets another $80B, so if you count that then I think even the most aggressive definition of how much FTX defrauded is smaller. But obviously OAI's EA credentials are dubious.)
EA has defrauded much more money than we've ever donated or built in terms of successful companies
FTX is missing $1.8B. OpenPhil has donated $2.8B.
I do think it's at the top of frauds in the last decade, though that's a narrower category.
Nikola went from a peak market cap of $66B to ~$1B today, vs. FTX which went from ~$32B to [some unknown but non-negative number].
I also think the Forex scandal counts as bigger (as one reference point, banks paid >$10B in fines), although I'm not exactly sure how one should define the "size" of fraud.[1]
I wouldn't be surprised if there's some precise category in which FTX is the top, but my guess is that you have to define that category fairly precisely.
- ^
Wi
Oh yeah, just because it's a reference point that doesn't mean that we should copy them
I think almost any large organization/company would have gone through a much more comprehensive fault-analysis and would have made many measurable improvements.
I claim YCombinator is a counter example.
(The existence of one counterexample obviously doesn't disagree with the "almost any" claim.)
IMO the EA community has had a reckoning, a post-mortem, an update, etc. far more than most social or political movements would (and do) in response to similar misbehavior from a prominent member
As a reference point: fraud seems fairly common in ycombinator backed companies, but I can't find any sort of postmortem, even about major things like uBiome where the founders are literally fugitives from the FBI.
It seems like you could tell a fairly compelling story that YC pushing founders to pursue risky strategies and flout rules is upstream of this level o...
Thanks for the questions!
- I feel a little confused about this myself; it's possible I'm doing something wrong. (The code I'm using is the `get_prob` function in the linked notebook; someone with LLM experience can probably say if that's broken without understanding the context.) My best guess is that human intuition has a hard time conceptualizing just how many possibilities exist; e.g. "Female", "female", "F", "f" etc. are all separate tokens which might realistically be continuations.
- I haven't noticed anything; my guess is that there probably is some effe
Thanks! I mentioned anthropic in the post, but would similarly find it interesting if someone did a write up about cohere. It could be that OAI is not representative for reasons I don't understand.
- Yep, revenue multiples are a heuristic for expectations of future growth, which is what I care about
- This is true, but I'm not aware of any investments on $0 revenue at the $10B scale. Would love to hear of counterexamples if you know of any![1]
- ^
Instagram is the closest I can think of, but that was ~20x smaller and an acquisition, not an investment
I tried playing the game Nate suggested with myself. I think it updated me a bit more towards Holden's view, though I'm very confident that if I did it with someone who was more expert than I am both the attacker and the defender would be more competent, and possibly the attacker would win.
Attacker: okay, let's start with a classic: Alignment strategy of "kill all the capabilities researchers so networks are easier to interpret."
Defender: Arguments that this is a bad idea will obviously be in any training set that a human level AI researcher would be train...
Yeah that's correct on both counts (that does seem like an important distinction, and neither really match my experience, though the former is more similar).
I spent about a decade at a company that grew from 3,000 to 10,000 people; I would guess the layers of management were roughly the logarithm in base 7 of the number of people. Manager selection was honestly kind of a disorganized process, but it was basically: impress your direct manager enough that they suggest you for management, then impress your division manager enough that they sign off on this suggestion.
I'm currently somewhere much smaller, I report to the top layer and have two layers below me. Process is roughly the same.
I realized that I should h...
For what it's worth, I think a naïve reading of this post would imply that moral mazes are more common than my experience indicates.
I've been in middle management at a few places, and in general people just do reasonable things because they are reasonable people, and they aren't ruthlessly optimizing enough to be super political even if that's the theoretical equilibrium of the game they are playing.[1]
- ^
This obviously doesn't mean that they are ruthlessly optimizing for the company's true goals though. They are just kind of casually doing things they
FYI I think your first skepticism was mentioned in the safety from speed section; she concludes that section:
These [objections] all seem plausible. But also plausibly wrong. I don’t know of a decisive analysis of any of these considerations, and am not going to do one here. My impression is that they could basically all go either way.
She mentions your second skepticism near the top, but I don't see anywhere she directly addresses it.
think about how humans most often deceive other humans: we do it mainly by deceiving ourselves... when that sort of deception happens, I wouldn't necessarily expect to be able to see deception in an AI's internal thoughts
The fact that humans will give different predictions when forced to make an explicit bet versus just casually talking seems to imply that it's theoretically possible to identify deception, even in cases of self-deception.
Basic question: why would the AI system optimize for X-ness?
I thought Katja's argument was something like:
- Suppose we train a system to generate (say) plans for increasing the profits of your paperclip factory similar to how we train GANs to generate faces
- Then we would expect those paperclip factory planners to have analogous errors to face generator errors
- I.e. they will not be "eldritch"
The fact that you could repurpose the GAN discriminator in this terrifying way doesn't really seem relevant if no one is in practice doing that?
Thanks for sharing this! Could you make it an actual sequence? I think that would make navigation easier.
Thanks! The point about existence proofs is helpful.
After thinking about this more, I'm just kind of confused about the prompt: Aren't big companies by definition working on problems that can be factored? Because if they weren't, why would they hire additional people?
Ask someone who’s worked in a non-academia cognitive job for a while (like e.g. a tech company), at a company with more than a dozen people, and they’ll be like “lolwut obviously humans don’t factorize problems well, have you ever seen an actual company?”. I’d love to test this theory, please give feedback in the comments about your own work experience and thoughts on problem factorization.
What does "well" mean here? Like what would change your mind about this?
I have the opposite intuition from you: it's clearly obvious that groups of people can accomplish...
Two key points here.
First: a group of 100 people can of course get more done over a month than an individual, by expending 100 times as many man-hours as the individual. (In fact, simple argument: anything an individual can do in a month a group of 100 can also do in a month by just having one group member do the thing independently. In practice this doesn't always work because people get really stupid in groups and might not think to have one person do the thing independently, but I think the argument is still plenty strong.) The question is whether the g...
I think humans actually do use SPI pretty frequently, if I understand correctly. Some examples:
- Pre-committing to resolving disputes through arbitration instead of the normal judiciary process. In theory at least, this results in an isomorphic "game", but with lower legal costs, thereby constituting a Pareto improvement.
- Ritualized aggression: Directly analogous to the Nerf gun example. E.g. a bear will "commit" to giving up its territory to another bear who can roar louder, without the need of them actually fighting, which would be costly for both parties.
- T
Thanks for sharing this update. Possibly a stupid question: Do you have thoughts on whether cooperative inverse reinforcement learning could help address some of the concerns with identifiability?
There are a set of problems which come from agents intentionally misrepresenting their preferences. But it seems like at least some problems come from agents failing to successfully communicate their preferences, and this seems very analogous to the problem CIRL is attempting to address.
> Start-ups want engineers who are overpowered for the immediate problem because they anticipate scaling, and decisions made now will affect their ability to do that later.
I'm sure this is true of some startups, but was not true of mine, nor the ones I was thinking of what I wrote that.
Senior engineers are like… Really good engineers? Not sure how to describe it in a non-tautological way. I somewhat regularly see a senior engineer solve in an afternoon a problem which a junior engineer has struggled with for weeks.
Being able to move that quickly is extr...
Startups sometimes have founders or early employees who are staff (or higher) engineers.
- Sometimes this goes terribly: the staff engineer is used to working in a giant bureaucracy, so instead of writing code they organize a long series of meetings to produce a UML diagram or something, and the company fails.
- Sometimes this goes amazingly: the staff engineer can fix bugs 10x faster than the competitors’ junior engineers while simultaneously having the soft skills to talk to customers, interview users, etc.
If you are in the former category, EA organizations mo...
EAG London last weekend contained a session with Rohin Shah, Buck Shlegeris and Beth Barnes on the question of how concerned we should be about AGI. They seemed to put roughly 10-30% chance on human extinction from AGI.
Thanks, yeah now that I look closer Metaculus shows a 25% cumulative probability before April 2029, which is not too far off from OP's 30% claim.
Note that Metaculus predictions don't seem to have been meaningfully changed in the past few weeks, despite these announcements. Are there other forecasts which could be referenced?
This post is mainly targeted at people capable of forming a strong enough inside view to get them above >30% without requiring a moving average of experts which may take months to update (since it's a popular question).
For everyone else, I don't think you should update much on this except vis a vis the number of other people who agree.
Update: I improved the profile of someone who reached out to me from this article. They went from zero matches in a year to ~2/week.
I think this is roughly the effect size one should expect from following this advice: it's not going to take you from the 5th percentile to the 95th, but you can go from the 20th to the 70th or something.
Why is the Alignment Researcher different than a normal AI researcher?
E.g. Markov decision processes are often conceptualized as "agents" which take "actions" and receive "rewards" etc. and I think none of those terms are "True Names".
Despite this, when researchers look into ways to give MDP's some other sort of capability or guarantee, they don't really seem to prioritize finding True Names. In your dialogue: the AI researcher seems perfectly fine accepting the philosopher's vaguely defined terms.
What is it about alignment which makes finding True Names s...
Sure, feel free to DM me.
We (the Center for Effective Altruism) are hiring Full-Stack Engineers. We are a remote first team, and work on tools which (we hope) better enable others to work on AI alignment, including collaborating with the LessWrong team on the platform you used to ask this question :)
A small suggestion: the counterexample to "penalize downstream", as I understand it, requires there to be tampering in the training data set. It seems conceptually cleaner to me if we can assume the training data set has not been tampered with (e.g. because if alignment only required there to be no tampering in the training data, that would be much easier).
The following counterexample does not require tampering in the training data:
- The predictor has nodes indicating whether the diamond was stolen at time
- It also has node
Thanks for sharing your idea!
I'm not an ARC member, but I think assuming that the chip is impossible to tamper with is assuming the conclusion.
The task is to train a reporter which accurately reports the presence of the diamond, even if we are unable to tell whether tampering has occurred (e.g. because the AI understands some esoteric physics principle which lets them tamper with the chip in a way we don't understand). See the section on page 6 starting with "You might try to address this possibility by installing more cameras and sensors..."
Thanks!
I've been trying to understand this paragraph:
...That is, it looks plausible (though still <50%) that we could improve these regularizers enough that a typical “bad” reporter was a learned optimizer which used knowledge of direct translation, together with other tricks and strategies, in order to quickly answer questions. For example, this is the structure of the counterexample discussed in Section: upstream. This is a still a problem because e.g. the other heuristics would often “misfire” and lead to bad answers, but it is a promising starting point becau
In "Strategy: penalize computation time" you say:
> At first blush this is vulnerable to the same counterexample described in the last section [complexity]... But the situation is a little bit more complex... the direct translator may be able to effectively “re-use” that inference rather than starting from scratch
It seems to me that this "counter-counterexample" also applies for complexity – if the translator is able to reuse computation from the predictor, wouldn't that both reduce the complexity and the time?
(You don't explicitly state that this "reuse" is only helpful for time, so maybe you agree it is also helpful for complexity – just trying to be sure I understand the argument.)
I think children can be prosecuted in any state but the prosecution of parents is more novel and was a minor controversy during the last presidential campaign.
Note that the REBench correlation definitionally has to be 0 because all tasks have the same length. SWAA similarly has range restriction, though not as severe.