This post heavily overlaps with “how might we safely pass the buck to AI?” but is written to address a central counter argument raised in the comments, namely “AI will produce sloppy AI alignment research that we don’t know how to evaluate.” I wrote this post in a personal capacity.
The main plan of many AI companies is to automate AI safety research. Both Eliezer Yudkowsky and John Wentworth raise concerns about this plan that I’ll summarize as “garbage-in, garbage-out.” The concerns go something like this:
Insofar as you wanted to use AI to make powerful AI safe, it’s because you don’t know how to do this task yourself.
So if you train AI to do research you don’t know how to do, it will regurgitate your bad takes and produce slop.
Of course, you have the advantage of grading instead of generating this research. But this advantage might be small. Consider how confused people were in 2021 about whether Eliezer or Paul were right about AI takeoff speeds. AI research will be like Eliezer-Paul debates. AI will make reasonable points, and you’ll have no idea if these points are correct.
This is not just a problem with alignment research. It's potentially a problem any time you would like AI agents to give you advice that does not already align with your opinions.
I don’t think this “garbage-in garbage-out” concern is obviously going to be an issue. In particular, I’ll discuss a path to avoiding it that I call “training for truth-seeking,” which entails:
- Training AI agents so they can improve their beliefs (e.g. do research) as well as the best humans can.
- Training AI agents to accurately report their findings with the same fidelity as top human experts (e.g. perhaps they are a little bit sycophantic but they mostly try to do their job).
The benefit of this approach is that it does not require humans to already have accurate beliefs at the start, and instead it requires that humans can recognize when AI agents take effective actions to improve their beliefs from a potentially low baseline of sloppy takes. This makes human evaluators like sweepers guiding a curling rock. Their job is to nudge agents so they continue to glide in the right direction, not to grab them by the handle and place agents exactly on the bullseye of accurate opinions.

Sweepers guiding a curling rock.
Of course, this proposal clearly doesn’t work if AI agents are egregiously misaligned (e.g. faking alignment). In particular, in order for “training for truth-seeking” to result in much better opinions than humans already have, agents must not be egregiously misaligned to start with, and they must be able to maintain their alignment as the complexity of their research increases (section 1).
Before continuing, it’s worth clarifying how developers might train for truth-seeking in practice. Here’s an example:
- Developers first direct agents to answer research questions. They score agents according to criteria like: “how do agents update from evidence?” “Do agents identify important uncertainties?”
- If developers aren’t careful, this process could devolve into normal RLHF. Human graders might pay attention to whether agents are just agreeing with them. So developers need to select tasks that graders don’t have preconceptions about. For example: “how will student loan policies affect university enrollment?” instead of “should guns be legalized?” Developers can reduce human bias even further by training multiple agents under slightly different conditions. These agents form a parliament of advisors.
- When developers have an important question like “should we deploy a model?” they can ask their parliament of AI advisors, which perform the equivalent of many human months of human research and debate, and provide an aggregated answer.
This procedure obviously won’t yield perfect advice, but that’s ok. What matters is that this process yields better conclusions than humans would otherwise arrive at. If so, the developer should defer to their AI.
As I’ll discuss later, a lot could go wrong with this training procedure. Developers need to empirically validate that it actually works. For example, they might hold out training data from after 2020 and check the following:
- Do agents make superhuman forecasts?
- Do agents discover key results in major research fields?
Developers might also assess agents qualitatively. I expect my interactions with superhuman AI to go something like this:
- AI agent: “Hey Josh, I’ve read your blog posts.”
- Me: “Oh, what are your impressions?”
- AI agent: “You are wrong about X because of Y.”
- Me: Yeah you are totally right.
- AI agent: “Wait I’m not done, I have 20 more items on my list of important-areas-where-you-are-unquestionably-wrong.”
So my main thought after these evaluations won’t be: “are these agents going to do sloppy research?” My main thought will be, “holy cow, I really hope these agents are trustworthy because they are far more qualified to do my job than I am.”
The remainder of this blogpost talks about a few problems this “training AI for truth-seeking” proposal could have. The first problem is that training with easy tasks might not generalize to hard tasks (section 1). Also, human graders might still introduce bias (section 2). Finally, agents might be egregiously misaligned (section 3).
1. Generalizing to hard tasks
The original problem we wanted to solve is that we’d like agents to do a massive amount of work that we can’t evaluate.
So we must rely on agents to generalize from “easy-to-grade” to “hard-to-grade” tasks. Said another way, we need some reason to think that nudging models in the direction of truth will cause them to continue to glide in that direction even when humans can’t nudge anymore.
For instance, AI agents might be like university students that can do 1-month take-home projects, but can’t spend 10 years on a discovery worthy of a nobel prize; however, insofar as capabilities cannot generalize to complex tasks, agents are not yet catastrophically dangerous. So we should assume that agent capabilities eventually generalize somehow. We can also confirm capability generalization with tasks held out from training data as discussed in the introduction (hold out alignment research from 2020 - 2025 and see how much of it AI agents can discover).
The question, then, is whether agents will generalize in a way that causes them to report accurate information. For example, agents might gather superhuman knowledge about whether the minimum wage should be abolished. But instead of reporting their beliefs, agents might feed politicians tasty slop that aligns with the prevailing ideology at the time.
This sycophantic behavior is consistent with the task the agent was originally trained to do, namely: “make one’s reasoning appear reasonable to humans.” Why shouldn’t we expect AI to be sycophantic like this?
It’s plausible to me that AI will be egregiously sycophantic by default. I’m not claiming that training models for truth-seeking works out of the box. I’m claiming that truth-seeking will generalize to much harder tasks if agents don’t start out egregiously misaligned and can maintain their alignment.
When I say agents are “not egregiously misaligned,” I mean they mostly perform their work earnestly – in the same way humans are mostly earnest and vaguely try to do their job. Maybe agents are a bit sycophantic, but not more than the humans whom they would replace. Therefore, if agents are consistently “not egregiously misaligned,” the situation is no worse than if humans performed their research instead.
Of course, to avoid egregious misalignment, developers must verify that models are not already conniving to satisfy some other set of preferences. Models should not already be thinking to themselves “how do I get the highest possible score” or “how do I acquire power.” But approximate alignment at the start isn’t enough. Agents must also maintain their alignment. For example:
- Agents might splinter into a diverse population so different members become misaligned at different times.
- Then models might monitor each other for signs that their alignment is slipping – both relying on external behavior and tools like lie detectors.
- If agents spot issues, they fix them promptly, or let humans know if they can’t fix these issues.
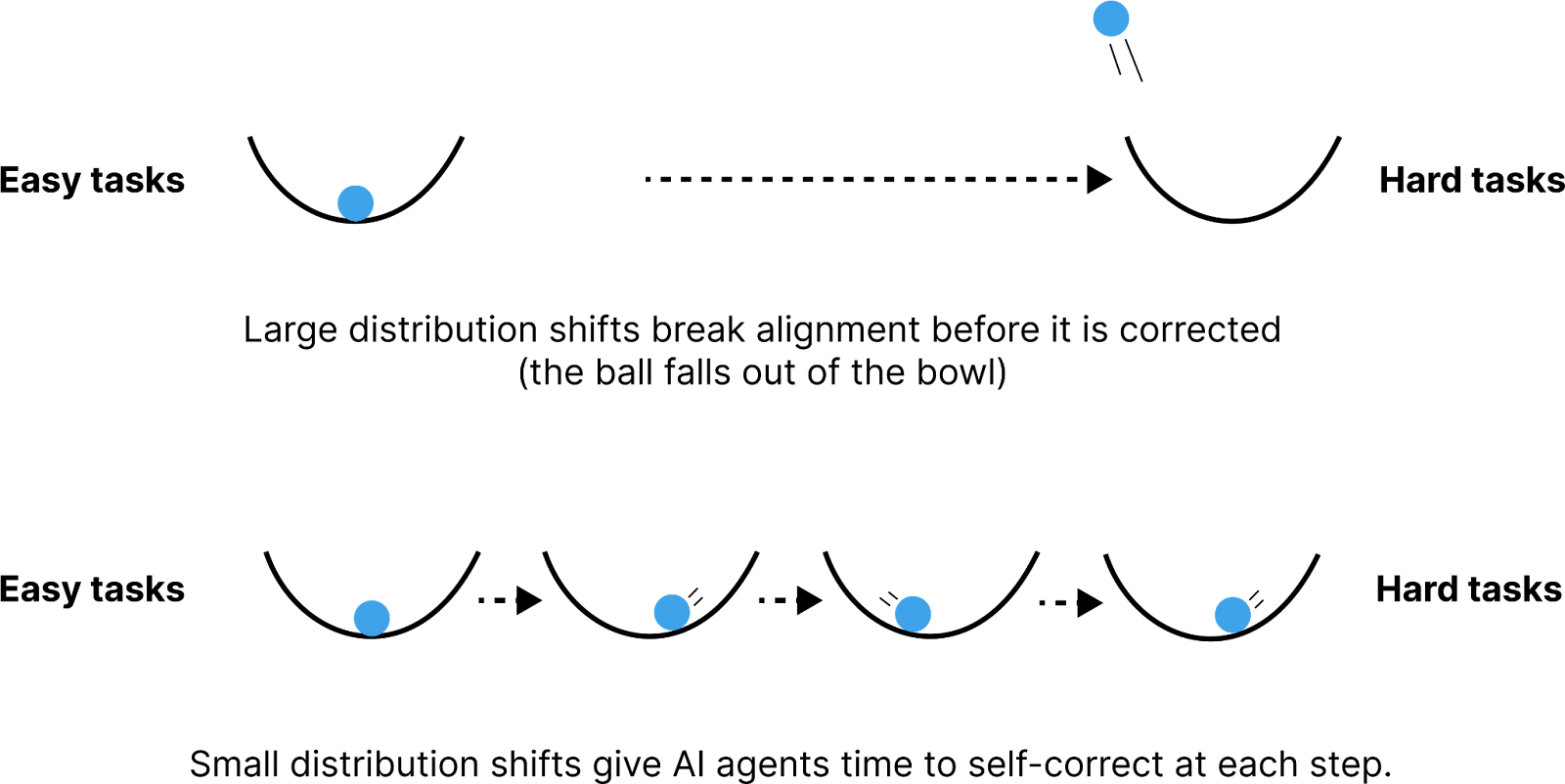
An illustration of how self-correction might be a mechanism by which alignment generalizes across the extreme distribution shift from “easy-to-grade” to “hard-to-grade” tasks.
Of course, this is only an example. I expect agents will come up with much better ways to maintain their alignment as they become much smarter than humans. The job of humans is just to make sure AI agents are able to self-correct at the early stages of this process – where human intervention might still plausibly help.
2. Human graders might introduce bias
One way to reduce bias is to avoid letting humans grade tasks they obviously have strong opinions about. The example I used was to train AI agents to seek the truth on tasks like “how will student loan policies affect university enrollment?” instead of “should guns be legalized?” But this doesn’t remove bias completely.
For instance, maybe a conservative grader doesn't care much about the minimum wage; however, if the grader evaluates a task related to whether the minimum wage should be abolished, they still might rely on intuitions that the government should stay small.
Every research question touches on people’s ideologies and preconceptions. As a result, developers might end up with some AI agents that “think like republicans” and some that “think like democrats,” depending on which people do the scoring.
However, the goal of developers is not to create a perfect reasoner. Instead the goal is to create agents that arrive at better conclusions than humans would. This goal can be achieved even if agents retain some human biases.
As a baseline, developers could train agents to imitate the truth-seeking process of the most reasonable humans on Earth. For example, they could sample the brightest intellects from every ideological walk, and train agents to predict their actions. Then developers could let these agents do research for a long time and debate with each other. By definition, to the extent developers succeed in creating faithful simulators, trusting agents will be at least as advantageous as the best conceivable alternative where developers trust humans instead.
So even if agents seek the truth in a slightly biased way, developers can still train them so they arrive at far better opinions than humans currently have. Furthermore, if developers would like less biased AI advisors, they could instruct the AI advisors: “please determine how to create unbiased AI advisors.” To the extent humans ever had any shot of achieving this goal, the AI advisors will also be able to achieve it.
3. AI agents might still be egregiously misaligned
The main weakness of training models for truth-seeking is that models might still end up egregiously misaligned (section 1). For example, if agents have the goal of “maximizing human approval of their behavior,” they might appear to seek truth, but increasingly won’t as this goal comes apart from doing well in training. The same is true if agents are scheming, alignment faking, playing the training game, etc.
Therefore, to be confident agents will seek the truth earnestly, developers still must make research advances that are sufficient to rule out these misalignment concerns.
Conclusion
Over the last several years, researchers have proposed various strategies for eliciting knowledge from superhuman AI. I believe much of this research is of questionable value. I don’t expect we will need Paul’s galaxy-brained computer science proposals or ELK probes for ASI. We will only need human-competitive agents that vaguely try to be helpful and maintain their alignment. This goal relies on progress on empirical research problems related to detecting and avoiding egregious alignment near human-competitive capabilities, which I believe should be the main focus of AI safety researchers.
Thanks to Aryan Bhatt and Cody Rushing for feedback.
Isn’t “truth seeking” (in the way defined in this post) essentially defined as being part of “maintain their alignment”? Is there some other interpretation where models could both start off “truth seeking”, maintain their alignment, and not have maintained “truth seeking”? If so, what are those failure modes?