This is a special post for quick takes by MathiasKB. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Is there any good write up on the gut/brain connection and the effect fecal transplants?
Watching the South Park episode where everyone tries to steal Tom Brady's poo got me wondering why this isn't actually a thing. I can imagine lots of possible explanations, ranging from "because it doesn't have much of an effect if you're healthy" to "because FDA".
With the release of openAI o1, I want to ask a question I've been wondering about for a few months.
Like the chinchilla paper, which estimated the optimal ratio of data to compute, are there any similar estimates for the optimal ratio of compute to spend on inference vs training?
In the release they show this chart:
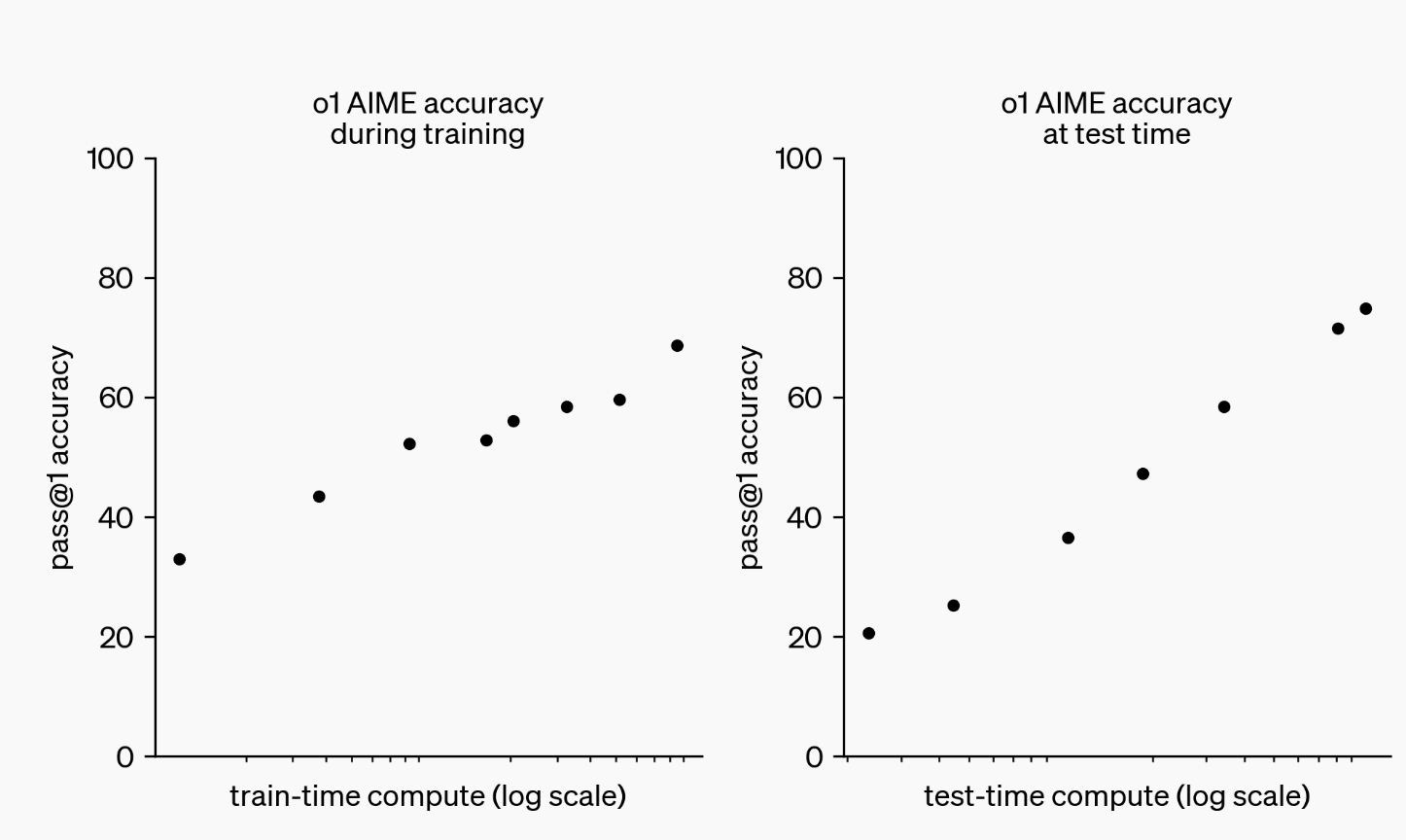
The chart somewhat gets at what I want to know, but doesn't answer it completely. How much additional inference compute would I need a 1e25 o1-like model to perform as well as a one shotted 1e26?
Additionally, for some x number of queries, what is the optimal ratio of compute to spend on training versus inference? How does that change for different values of x?
Are there any public attempts at estimating this stuff? If so, where can I read about it?
The amount of inference compute isn't baked-in at pretraining time, so there is no tradeoff. You train the strongest model, then offer different ways of doing inference with it. Expensive inference probably wasn't offered before OpenAI o1 because it didn't work well enough to expect even a minimal viable number of customers who are willing to pay the inference premium. Many inference setups have significant fixed costs, you need sufficient demand for price per request to settle.
The plots show scaling across 2 orders of magnitude with no diminishing returns. Train-time compute is likely post-training, so it might still be much cheaper than pretraining, feasible to scale further if it doesn't crucially depend on the amount of human labeling. Test-time compute on one trace comes with a recommendation to cap reasoning tokens at 25K, so there might be 1-2 orders of magnitude more there with better context lengths. They are still not offering repeated sampling filtered by consensus or a reward model. If o1 proves sufficiently popular given its price, they might offer even more expensive options.
The amount of inference compute isn't baked-in at pretraining time, so there is no tradeoff.
This doesn't make sense to me.
In a subscription based model, for example, companies would want to provide users the strongest completions for the least amount of compute.
If they estimate customers in total will use 1 quadrillion tokens before the release of their next model, they have to decide how much of the compute they are going to be dedicating to training versus inference. As one changes the parameters (subscription price, anticipated users, fixed costs for a training run, etc.) you'd expect to find the optimal ratio to change.
Test-time compute on one trace comes with a recommendation to cap reasoning tokens at 25K, so there might be 1-2 orders of magnitude more there with better context lengths. They are still not offering repeated sampling filtered by consensus or a reward model. If o1 proves sufficiently popular given its price, they might offer even more expensive options.
Thanks, this is a really good find!
There are open weights Llama 3 models, using them doesn't involve paying for pretraining. The compute used in frontier models is determined by the size of the largest cluster with the latest AI accelerators that hyperscaler money can buy, subject to the time it takes the engineers to get used to the next level of scale, not by any tradeoff with cost of inference. Currently that's about 100K H100s. This is the sense in which there is no tradeoff.
If somehow each model needed to be pretrained for a specific inference setup with specific inference costs and for it alone, then there could've been a tradeoff, but there is no such correspondence. The same model that's used in a complicated costly inference heavy technique can also be used for the cheapest inference its number of active parameters allows. If progress slows down in a few years and it becomes technologically feasible to do pretraining runs that cost over $50bn, it will make sense to consider the shape of the resulting equilibrium and the largest scale of pretraining it endorses, but that's a very different world.