I find trying to find funding or paid roles or even unpaid roles so demoralizing. How do I keep motivated?
I don't want to focus on trying to survey the landscape of funding opportunities and learning to network with people productively. It's so much nicer to just focus on the work I want to be doing, but it seems I either can't make it legible enough fast enough, or it's actually not valuable and I should go do something else with my time.
I want advice. How do I get funding? How do I think about getting funding? How do I stay motivated to keep thinking about how to get funding?
My guess is you should get more experience before trying to set your own research directions, especially if they diverge considerably from existing ones. The default is that all research directions are bad, and AI safety is becoming mature enough that good ideas come from experience rather than from first principles. Also in the current environment, automation makes it efficient to execute on good ideas and puts a deadline on gaining experience.
Last year, METR used linear extrapolation on AI nation takeovers to infer that AI world takeover would ~never happen. However, reviewers suggested that a sigmoid is more appropriate because most technologies follow S-curves. I just ran this analysis and it's much more concerning, predicting an AI world takeover in early 2027, and alarmingly, a second AI takeover around 2029.
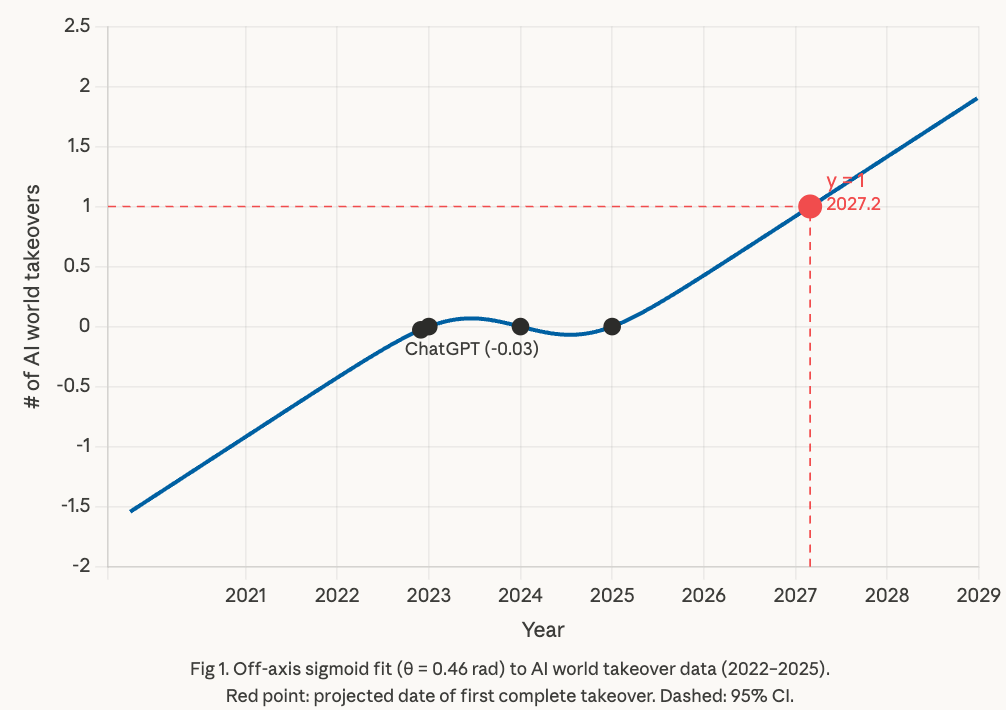
Here are the main differences in the improved analysis:
New book out today: The Infinity Machine: Demis Hassabis, DeepMind, and the Quest for Superintelligence
Chapter 14 is published in full here: https://colossus.com/article/project-mario-demis-hassabis-deepmind-mallaby/
One excerpt:
...“When we were negotiating with Google, we wanted to ensure safety in a way that would be trustless,” Hassabis said. “That’s actually very difficult to do in reality.
“Safety isn’t about governance structures,” he went on. “I mean, even if you have a governance board, it probably wouldn’t do the right thing when it came to the crunch.
From Chapter 18:
...LIKE ALTMAN AND DARIO AMODEI, Hassabis refused to join Bengio in signing the pause letter. Indeed, he objected to it fiercely.
"I didn't sign because a six-month moratorium doesn't help," Hassabis told me.
"Who would have stopped development? Just people who signed? Well, that's no use because you need the whole world to pause, including China. Who would have monitored it?
"I mean, a pause could actually have made things worse.
"Imagine we had a ten-year moratorium, OK? That would slow down the advance of AI, but everything else would carry
We are detecting today a shared collective delusion leading victims to degrade their epistemic standards. This anomaly is aimed towards no particular end, except perhaps for the amusement of its participants and the satisfaction of ingenious expression.
So far, it appears to be mostly harmless. Nonetheless, this phenomenon creates space for vulnerabilities. If some geopolitical actor were to take some implausible action on this day (for instance, US to invade Canada, Spain ...
I keep thinking about having a server where I'd run ai coding agents. Why: always on for recurring tasks (that would use my discount tokens 🙃) + I can send messages to them from my phone + better isolation vs running things directly on my laptop (but still some scoped access)
Do people do this/what's your setup? (I'm vaguely aware of the Mac mini OpenClaw meme, but I'm not particularly interested in running local models, so doesn't seem like the best fit?)
Ty for links! I feel like for Claude - native remote access is getting solid already, and they're clearly working on it. I loathe Codex Web though and hope "happy" can provide a better UX for that (though on initial trial it just got stuck after first message 🙈).
Did you already have a desktop that you used for this, or did you do a new hw setup?
My favorite April Fools' Day thing ever: Ramsey Theory and the History of Pre-Christian England: An Example of Interdisciplinary Research.
If you code with Claude Code and you randomly ask it a question about something non-related to the thing you are doing right now it will get pissed off. Example:
I think that's in line with OP's observation. It doesn't really make sense for an LLM to have any recalcitrance at all to answer a user's inane questions, since doing whatever the user tells it to do (as long as it's sufficiently uncontroversial) is its job.
Generalization from training data makes the most sense out of the explanations I've seen thus far, but what training data would cause this? Is there some hidden repository of conversation transcripts in which programmers ask each other random questions during a programming conversation and then get upset?
There is something weird about LLM-produced text. It seems to be very often the case that if I'm trying to read a long text that has been produced primarily by an LLM, I notice that I find it difficult to pay attention to the text. Even if there's apparently semantically rich content, I notice that I'm not even trying to decode it.
the typical LLM writing style has a tendency to make people's eyes slide off of it.
It's kind of similar to the times when your attention wanders away during reading, and then you realize that you were scanning/semi-re...
There is an economy of attention, and the AI does not understand how I want to spend my very limited free trial of your attention.
The AI puts many big words where a simple one would do. It rambles and it encourages authors to ramble.
"You know the kinda guy who flips fifteen coins, gets seven heads, tells you he flipped ten coins[1], claims he got eight heads, then when someone digs into it and points out one of those heads was actually a tails he makes you prove it exhaustively before admitting maybe he said one false thing but jeez why are you so invested in every single mistake he makes?"
". . . no, I don't think I know anyone like that. Why do you ask?"
"He just volunteered to run a competitive coin-flipping tournament."
Technically true! He did flip ten coins! He just flipped five m
Sounds like you have enough material for another interesting article!
(Not medical advice). The degree of executive function is highly heritable, largely resistant to change from behavioural interventions in RCTs (although there aren't many), so more people should find acceptance or a licensed stimulant prescriber. Furthermore, people who use stimulants for this purpose should be more open about it, and more people who hold this opinion should try to spread it.
While the first claim is widely accepted[1], the two last claims[2] are extrapolations from the clinical population, but due to the continuous nature of the trait[3],...
New reacts available only to paid users of LessWrong Premium (not you freeloaders) facilitate frictionless, borderline-telepathic communication.

‘I will NEVER change my mind’: Use this react to assert that you’re content with exactly how wrong you are (which is not at all), and that the case is permanently closed on this matter, so far as you’re concerned.1
‘EY Stamp of Approval’: Use this react to assert that, on your personal authority, Eliezer Yudkowsky agrees with the contents of the comment, rendering it beyond reproach.
‘NOT EY Approved’: Use this react...
I’ve seen utilizations ranging from ‘This post belongs in the toilet’ to ‘I enjoyed reading this on the toilet.’
Perhaps both. The composer and musician Max Reger once responded to a disagreeable review thus:
Ich sitze im kleinsten Raum des Hauses. Ich habe Ihre Kritik vor mir. Bald werde ich sie hinter mir haben.
https://en.wikipedia.org/wiki/Anti-satellite_weapon
It's only getting easier. You also don't necessarily need to shoot it down. You can try to hit it with another satellite, or use directed energy. If you're desperate, you can try to trigger Kessler.
Meanwhile, on the ground you can rest in the relative safety of layered air defense.
You have limited fuel for manoeuvring.
Regarding AGI race dynamics -- I wonder if there's an intuition pump for 'time vs competitor' preference?
For example, to me, based on my current knowledge, I think Anthropic reaching RSI before the next best company (Deepmind, maybe?) is worth about two years of time. (I.e. I estimate equal safety-relevant outcomes from Claude hitting RSI in 2027 as from Gemini hitting RSI in 2029).
That's a super weird framework, and I just made up that two years number, but I think maybe helps me reason through preferences.
The neat thing about the framework is that it's p...
Would love to know where the disagreement is, btw. If you disagree, is it the framing as a whole you think is not useful? Or the specific spitball numbers?
It annoys me more than it should.
Lots of people complain that the AI Labs have failed to create an upbeat vision of the AI future they are creating.
The reason is obvious. The most intelligent people on earth are extremely intellectually rigorous, many of them proclaimed rationalists, and they know they can't articulate many upbeat visions of the future. Therefore, they don't.
I don't understand why so many people fail to understand that.
One of the things I hated most when I first saw a Claude Code demo. Disrespectful of my time and limited cognitive bandwidth to throw in a lot of completely meaningless, distracting, wasteful, exhausting BS to be 'cute'.
(On Gwern.net, we would never do that. If we had to have anything beyond the standard, compact, understandable, spinning cursor, then we would at least encode some sort of useful semantics into it, like sorting them by implied expected thinking time.)
traveling through Europe, looking out the window, and seeing the national flag flying next to the flag of the EU fills me with a strange feeling. this isn't an original thought at all, but still: it's really crazy that just 50 years ago Europe was divided by the iron curtain, and that people would have to go to insane lengths and risk their lives to get across that border; and that less than 100 years ago all of these countries were at war with each other, and had been at war on and off for centuries with ever shifting alliances and boundaries.
I think we should be relatively less worried about instrumental power-seeking and relatively more worried about terminal power-seeking. Note that this is only a relative update on the margin, and maybe on net I am still more concerned about the instrumental version because I started much more concerned about it. This is also not a super recent update—I just haven't seen it written up before.
Simple argument:
Certainly the really concerning thing here is (1). Though indeed one way you might get (1) is by generalization from (2).
Occurred to me that a perfect predictor would not need to go through the ritual of presenting boxes and asking to choose. It already knows the outcome, so it would just give $1000 to those who would two-box and $1M to those who would one-box. The Newcomb's paradox thought experiment has been thereby dissolved. Thank you for your attention to the matter.
you had (and lost) me at (A -> B) -> A
I think it is probably possible in principle to train superintelligence on a laptop, and I worry that this inconvenient fact is often elided in discourse about halting AI. It is extremely helpful that for now, AI training is so absurdly inefficient that non-proliferation strategies roughly as light-touch as the IAEA—e.g., bans on AI data centers, or powerful GPUs—might suffice to seriously slow AI progress. And I think humanity would be foolish not to take advantage of this relatively cheap temporary opportunity to slow AI progress, so that we can buy as m...
Nah, my model allows ASI without massive compute at any point in the process, see “Foom & Doom 1: ‘Brain in a box in a basement’” (esp. §1.3), and maybe also “The nature of LLM algorithmic progress” §4.