A big bottleneck in interpretability is neural networks are non-local. That is, given the layer setup
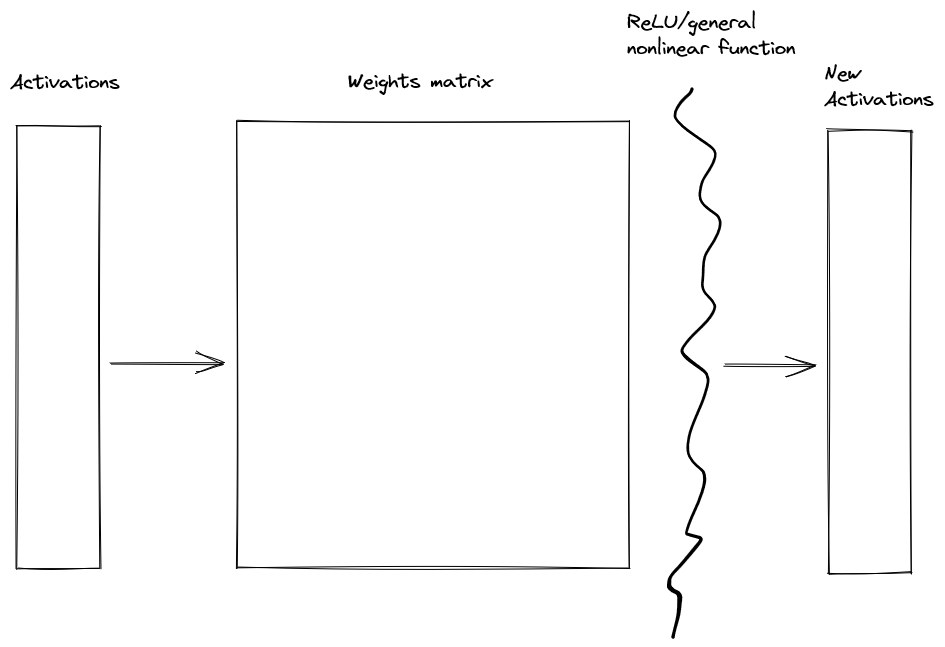
if we change a small bit of the original activations, then a large bit of the new activations are affected.
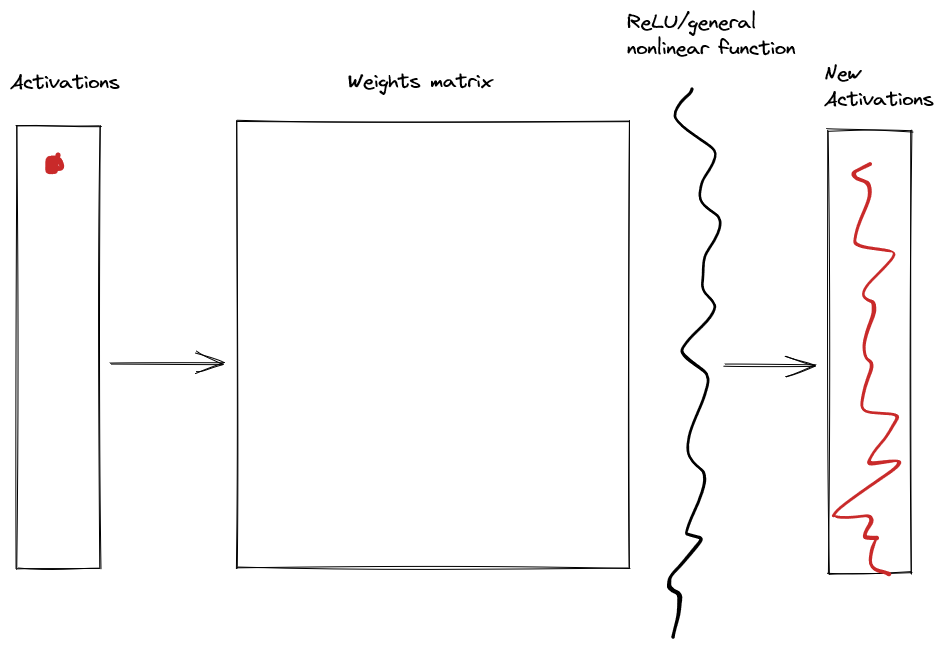
This is an impediment to finding the circuit-structure of networks. It is difficult to figure out how something works when changing one thing affects everything.
The project I'm currently working on aims to fix this issue, without affecting the training dynamics of networks or the function which the network is implementing[1]. The idea is to find a rotation matrix and insert it with its inverse like below, then group together the rotation with the original activations, and the inverse with the weights and nonlinear function.
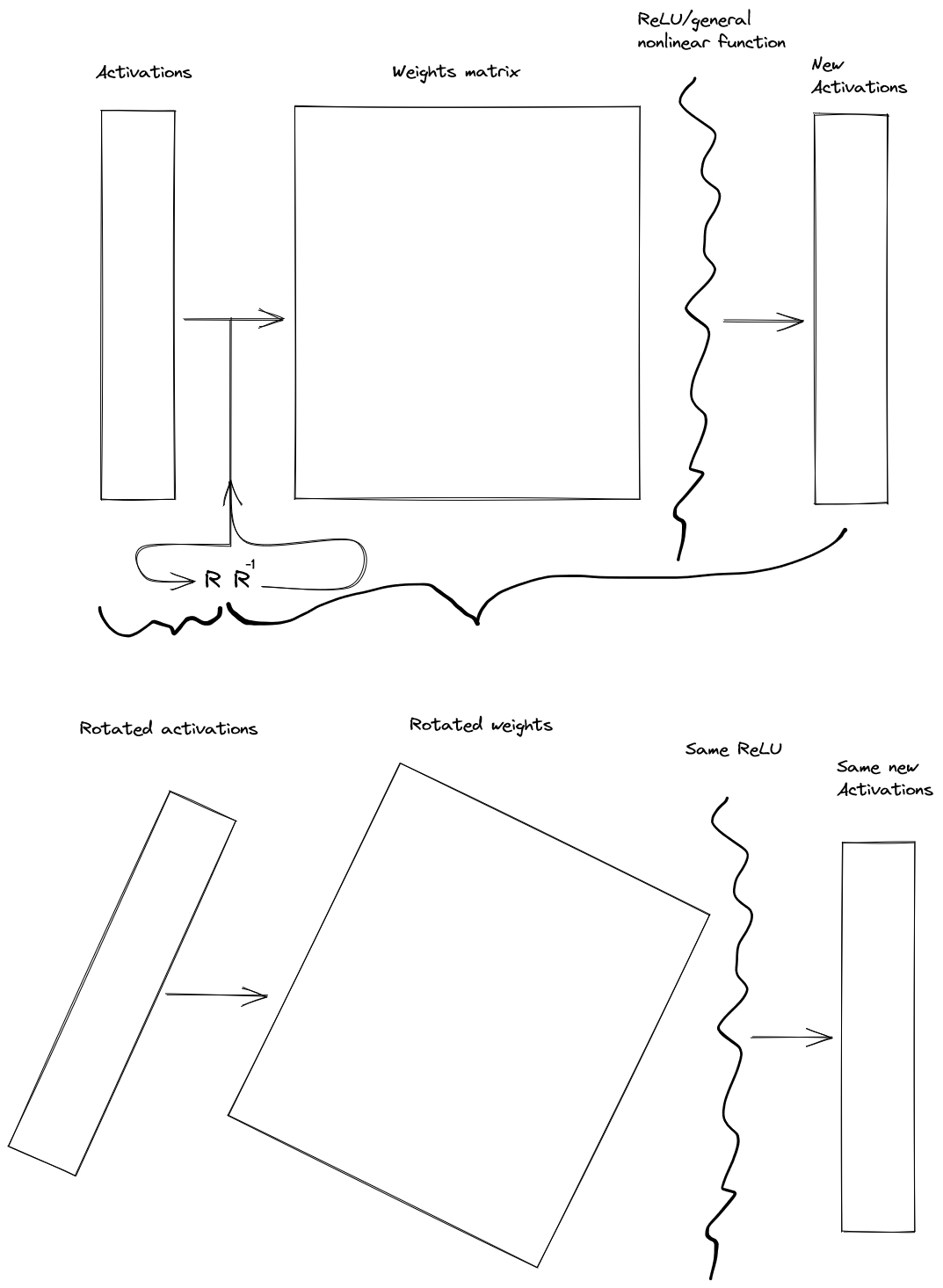
We then can optimize the rotation matrix and its inverse so that local changes in the rotated activation matrix have local effects on the outputted activations. This locality is measured by the average sparsity of the jacobian across all the training inputs.
We do this because the jacobian is a representation of how each of the inputs affects each of the outputs. Large entries represent large effects. Small entries represent small effects. So if many entries are zero, this means that fewer inputs have an effect on fewer outputs. I.e. local changes to the input cause local changes to the output.
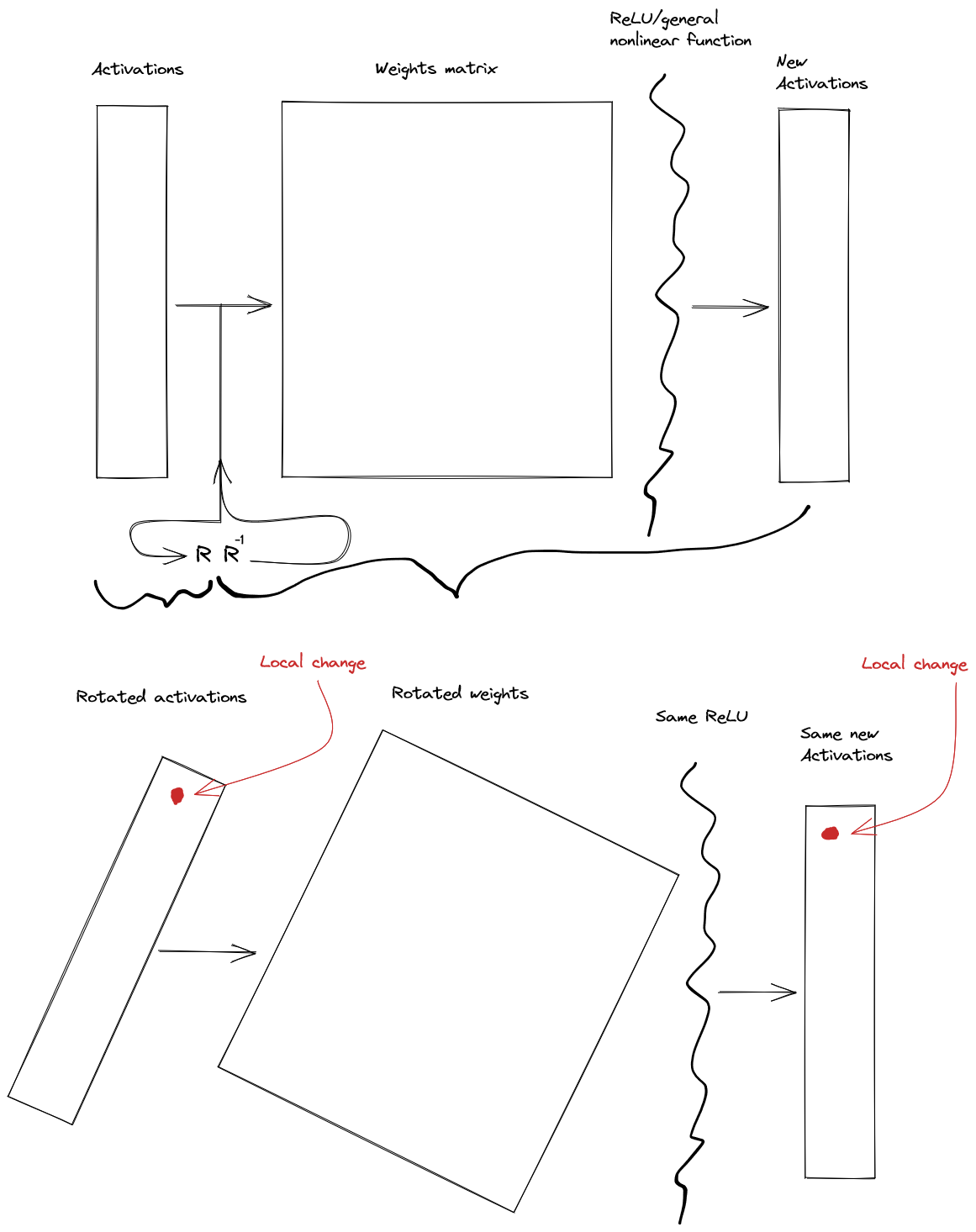
This should find us a representation of the activations and interpretations of matrix multiplies that "make sense" in the context of the rest of the network.
Another way of thinking about this is that our goal is to find the basis our network is thinking in.
Currently I'm getting this method to work on a simple, 3-layer, fully connected MNIST number classifying network. If this seems to give insight into the mechanics of the network after application, the plan is to adapt it to a more complicated network such as a transformer or resnet.
I only have preliminary results right now, but they are looking promising:
This is the normalized jacobian the middle layer before a rough version of my method:

And here is the normalized jacobian after a rough version of my method (the jacobian's output has been set to a basis which maximizes it's sparsity):

Thanks David Udell for feedback on the post. I did not listen to everything you said, and if I did the post would have been better
- ^
This seems important if we'd like to use interpretability work to produce useful conjectures about agency and selection more generally.
Interesting idea, and I'm generally very in favour of any efforts to find more understandable and meaningful "elementary units" of neural networks right now. I think this is currently the research question that most bottlenecks any efforts to get a deeper understanding of NN internals and NN selection, and I think those things are currently the biggest bottlenecks to any efforts at generating alignment strategies that might actually work. So we should be experimenting with lots of ideas for different NN "bases" to use and construct our theory of Deep Learning on top of, until we get a strong signal that we've found the right one.
Both bases that keep the layer structure the same, such as the one you propose here, or the one we're planning to investigate next, and bases that assume the layer structure doesn't quite match the way we should be thinking about the time ordering of computations in the network, and allow basis transformations that put activations that used to be in different layers into the same layer.
If anyone is looking to come up with more promising ideas for basis transformations, some guiding heuristics to generate candidates might be: bases that seem to spontaneously show up when you're investigating the math behind some property of neural networks, bases that seem to make neural networks a lot more understandable to humans without requiring a lot of effort to compute, bases that come out of some theory or hypothesis of what neural networks are "really doing", bases that have less degrees of freedom than the neuron basis but still seem to accurately capture the behaviour of the network in many aspects of training and deployment both.
I agree entirely with this bottleneck analysis, and am also very excited about the work you're doing and have just posted.