I’ve seen this and will reply in the next couple of days. I want to give it the full proper response it deserves.
Also thanks for taking the time to write this. I don’t think I would get this level or quality of feedback anywhere else online outside of an academic journal.
Thanks, I am looking forward to that. There is one thing I would like to have changed about my post, because it was written a bit "in haste," but since a lot of people have read it as it stands now, it also seems "unfair" to change the article, so I will make an amendment here, so you can take that into account in your rebuttal.
For General Audience: I stand by everything I say in the article, but at the time I did not appreciate the difference between shrinking within cutting frames (LD regions) and between them. I now understand that the spike and slab is only applied within each LD region, such that each region has a different level of shrinkage, I think there exists software that tries to shrink between them but FINEMAP does not do that as fare as I understand. I have not tried to understand the difference between all the different algorithms, but it seems like the ones that does shrink between cutting frames does it "very lightly"
Had I known that at the time of writing I would have changed Optional: Regression towards the null part 2. I think spike and slab is almost as good as using a fat-tailed distribution within each cutting frame (LD region), because I suspect the effect inflation primarily arises from correlations between mutations due to inheritance patterns and to a much smaller degree from fluctuations due to "measurement error/luck" with regards to the IQ outcome variable (except when two correlated variables have very close estimates). So if I were to rewrite that section, I would instead focus on the total lack of shrinking between cutting frames, rather than the slightly insufficient shrinkage within cutting frames.
For an intuitive reason for why I care:
- frequentest: the spike and slab estimator is unbiased for all of my effects across my 1000+ LD regions.
- Bayesian: bet you 5$ that the most positive effect is to big and the most negative effect is to small, the Bayesian might even be willing to bet that it is not even in the 95% posterior interval, because it's the most extreme from 1000+ regions[1].
Not For General Audience, read at your own peril
Pointing at a Technical approach: It is even harder to write "how to shrink now" since we are now doing one more level of hierarchical models. The easiest way would be to have an adaptive spike and slab prior that you imagine all the 1000-2000 LD slap and spike priors are drawn from, and use that as an extra level of shrinkage. That would probably work somewhat. But I still feel that would be insufficient for the reasons outlined in part 2, namely that it will shrink the biggest effects slightly too much, and everything else too little, and thus underestimate the effects of the few edits and overestimate the effects of many edits, but such a prior will still shrink everything compared to what you have now, so even if it does insufficient/uneven shrinkage, it's still a better estimate than no shrinkage between LD regions.
Implementation details of 3-level spike and slab models: It is however even harder to shrink those properly. A hint of a solution would be to ignore the fact that each of the spike and slab "top level adaptive priors" influence both the slab and spike of the 1000+ LD shrinkage priors, and thus only use the spike to regularize the spike and the slab to regularize the slab. It might be possible to estimate this "post hoc", if your software outputs a sufficient amount of summary statistics, but I am actually unsure.
Implementation details of 3-level Gelman model: If you for some magical reason wanted to implement the method proposed by Andrew Gelman, as a two-level hierarchical model, then I can say from experience that when you have no effects, the method sometimes fails[2], so you should set number of mixtures to 1 for all LD regions that "suck" (suck=any mixture with one or more sigma < 1). I actually suspect/know the math for doing this may be "easy", but I also suspect that most genetics software does fancy rule-of-thumb stuff based on the type of SNP, such as assuming that a stop codon is probably worse than a mutation in a non-coding region, and all that knowledge probably helps more with inferences than "not modeling tails correct" hurts.
- [1] I am not sure this bet is sound, because if the tails are fat, then we should shrink very little, so the 1:1000 vs 1:20 argument would utterly fail for a monogenic diseases, and the spike and slab stuff within cutting frames does some shrinkage.
- [2]If statisticians knew how to convolve a t-distribution it would not fail, because a t-distribution with nu=large number converges to a normal distribution, but because he approximates a t-like distribution as a mixture of normals, it sometimes fails when the effects are truly drawn from a normal, which will probably be the case for a few LD regions.
Sorry, I've been meaning to make an update on this for weeks now. We're going to open source all the code we used to generate these graphs and do a full write-up of our methodology.
Kman can comment on some of the more intricate details of our methodology (he's the one responsible for the graphs), but for now I'll just say that there are aspects of direct vs indirect effects that we still don't understand as well as we would like. In particular there are a few papers showing a negative correlation between direct and indirect effects in a way that is distinct for intellligence (i.e. you don't see the same kind of negative correlation for educational attainment or height or anything like that). It's not clear to us at this exact moment what's actually causing those effects and why different papers disagree on the size of their impact.
In the latest versions of the IQ gain graph we've made three updates:
- We fixed a bug where we squared a term that should not have been squared (this resulted in a slight reduction in the effect size estimate)
- We now assume only ~82% of the effect alleles are direct, further reducing benefit. Our original estimate was based on a finding that the direct effects of IQ account for ~100% of the variance using the LDSC method. Based on the result of the Lee et al Educational Attainment 4 study, I think this was too optimistic.
- We now assume our predictor can explain more of the variance. This update was made after talking with one of the embryo selection companies and finding their predictor is much better than the publicly available predictor we were using
The net result is actually a noticeable increase in efficacy of editing for IQ. I think the gain went from ~50 to ~85 assuming 500 edits.
It's a little frustrating to find that we made the two mistakes we did. But oh well; part of the reason to make stuff like this public is so others can point out mistakes in our modeling. I think in hindsight we should have done the traditional academic thing and ran the model by a few statistical geneticists before publishing. We only talked to one, and he didn't get into enough depth for us to discover the issues we later discovered.
I am glad that you guys fixed bugs and got stronger estimates.
I suspect you fitted a model using best practices, I don't think the methodology is my main critique, though I suspect there is insufficient shrinkage in your estimates (and most other published estimates for polygenic traits and diseases)
It's the extrapolations from the models I am skeptical of. There is a big difference between being able to predict within sample where by definition 95% of the data is between 70-130, and then assuming the model also correctly predict when you edit outside this range, for example your 85 upper bound IQ with 500 edits, if we did this to a baseline human with IQ 100, then his child would get an IQ of 185, which is so high that only 60 of the 8 billion people on planet earth is that smart if IQ was actually drawn from a unit normal with mean 100 and sigma 15, and if we got to 195 IQ by starting with a IQ 110 human, then he would have a 90% chance of being the smartest person alive, which I think is unlikely, and I find it unlikely because there could be interaction effects or a miss specified likelihood which makes a huge difference for the 2% of the data that is not between 70-130, but almost no difference for the other 98%, so you can not test what correctly likelihood is by conventional likelihood ratio testing, because you care about a region of the data that is unobserved.
The second point is the distinction between causal for the association observed in the data, and causal when intervening on the genome, I suspect more than half of the gene is only causal for the association. I also imagine there are a lot of genes that are indirectly causal for IQ such as making you an attentive parent thus lowering the probability your kid does not sleep in the room with a lot of mold, which would not make the super baby smarter, but it would make the subsequent generation smarter.
So in theory I think we could probably validate IQ scores of up to 150-170 at most. I had a conversation with the guys from Riot IQ and they think that with larger sample sizes the tests can probably extrapolate out that far.
We do have at least one example of a guy with a height +7 standard deviations above the mean actually showing up as a really extreme outlier due to additive genetic effects.
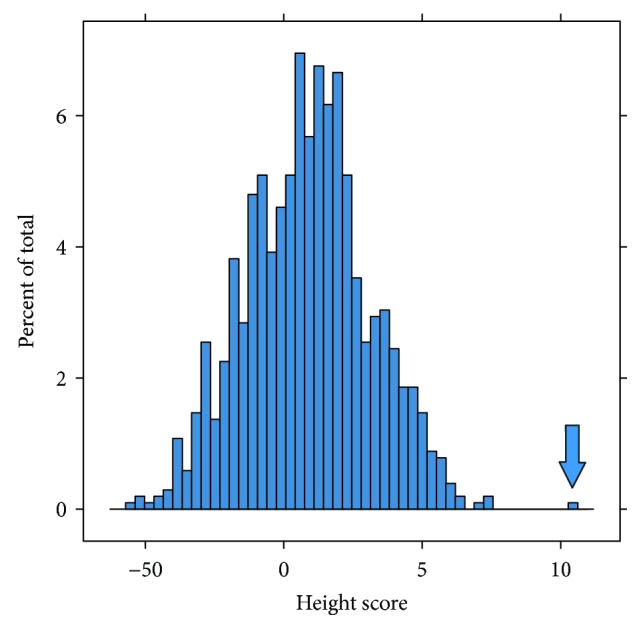
The outlier here is Shawn Bradley, a former NBA player. Study here
Granted, Shawn Bradley was chosen for this study because he is a very tall person who does not suffer from pituitary gland dysfunction that affects many of the tallest players. But that's actually more analogous to what we're trying to do with gene editing; increasing additive genetic variance to get outlier predispositions.
I agree this is not enough evidence. I think there are some clever ways we can check how far additivity continues to hold outside of the normal distribution, such as checking the accuracy of predictors at different PGSes, and maybe some clever stuff in livestock.
This is on our to-do list. We just haven't had quite enough time to do it yet.
The second point is the distinction between causal for the association observed in the data, and causal when intervening on the genome, I suspect more than half of the gene is only causal for the association. I also imagine there are a lot of genes that are indirectly causal for IQ such as making you an attentive parent thus lowering the probability your kid does not sleep in the room with a lot of mold, which would not make the super baby smarter, but it would make the subsequent generation smarter.
There are some, but not THAT many. Estimates from EA4, the largest study on educational attainment to date, estimated the indirect effects for IQ at (I believe) about 18%. We accounted for that in the second version of the model.
It's possible that's wrong. There is a frustratingly wide range of estimates for the indirect effect sizes for IQ in the literature. @kman can talk more about this, but I believe some of the studies showing larger indirect effects get such large numbers because they fail to account for the low test-retest reliability of the UK biobank fluid intelligence test.
I think 0.18 is a reasonable estimate for the proportion of intelligence caused by indirect effects. But I'm open to evidence that our estimate is wrong.
I felt too stupid when it comes to biology to interact with the original superbabies post but this speaks more my language (data science) so I would also just want to bring up a point I had with the original post that I'm still confused about related to what you've mentioned here.
The idea I've heard about this is that intelligence has been under strong selective pressure for millions of years, which should apriori make us believe that IQ is a significant challenge for genetic enhancement. As Kevin Mitchell explains in "Innate," most remaining genetic variants affecting intelligence are likely:
- Slightly deleterious mutations in mutation-selection balance
- Variants with fitness tradeoffs preventing fixation
- Variants that function only in specific genetic backgrounds
Unlike traits that haven't been heavily optimized (like resistance to modern diseases), the "low-hanging fruit" for cognitive enhancement has likely already been picked by natural selection. This means that the genetic landscape for intelligence might not be a simple upward slope waiting to be climbed, but a complex terrain where most interventions may disrupt finely-tuned systems.
When we combine multiple supposedly beneficial variants, we risk creating novel interactions that disrupt the intricate balance of neural development that supports intelligence. The evolutionary "valleys" for cognitive traits may be deeper precisely because selection has already pushed us toward local optima.
This doesn't make enhancement impossible, but suggests the challenge may be greater than statistical models indicate, and might require understanding developmental pathways at a deeper level than just identifying associated variants.
Also if we look at things like horizontal gene transfer & shifting balance theory we can see these as general ways to discover hidden genetic variants in optimisation and this just feels highly non-trivial to me? Like competing against evolution for optimal information encoding just seems really difficult apriori? (Not a geneticist so I might be completely wrong here!)
I'm very happy to be convinced that these arguments are wrong and I would love to hear why!
One data point that's highly relevant to this conversation is that, at least in Europe, intelligence has undergone quite significant selection in just the last 9000 years. As measured in a modern environment, average IQ went from ~70 to ~100 over that time period (the Y axis here is standard deviations on a polygenic score for IQ)
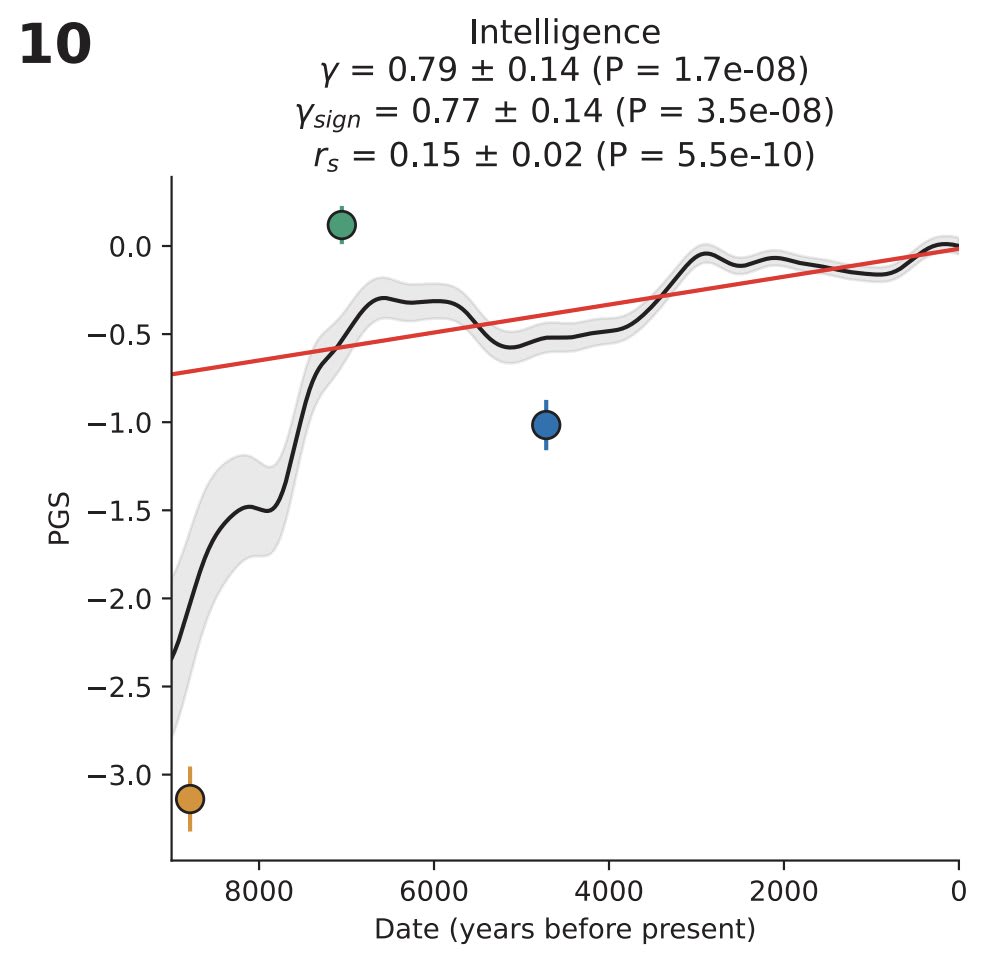
The above graph is from David Reich's paper
I don't have time to read the book "Innate", so please let me know if there are compelling arguments I am missing, but based on what I know the "IQ-increasing variants have been exhausted" hypothesis seems pretty unlikely to be true.
There's well over a thousand IQ points worth of variants in the human gene pool, which is not what you would expect to see if nature had exhaustively selected for all IQ increasing variants.
Unlike traits that haven't been heavily optimized (like resistance to modern diseases)
Wait, resistance to modern diseases is actually the single most heavily selected for thing in the last ten thousand years. There is very strong evidence of recent selection for immune system function in humans, particularly in the period following domestication of animals.
Like there has been so much selection for human immune function that you literally see higher read errors in genetic sequencing readouts in regions like the major histocompatibility complex (there's literally that much diversity!)
but suggests the challenge may be greater than statistical models indicate, and might require understanding developmental pathways at a deeper level than just identifying associated variants.
If I have one takeaway from the last ten years of deep learning, it's that you don't have to have a mechanistic understanding of how your model is solving a problem to be able to improve performance. This notion that you need a deep mechanical understanding of how genetic circuits operate or something is just not true.
What you actually need to do genetic engineering is a giant dataset and a means of editing.
Statistical methods like finemapping and adjusting for population level linkage disequilibrium help, but they're just making your gene editing more efficient by doing a better job of identifying causal variants. They don't take it from "not working" to "working".
Also if we look at things like horizontal gene transfer & shifting balance theory we can see these as general ways to discover hidden genetic variants in optimisation and this just feels highly non-trivial to me? Like competing against evolution for optimal information encoding just seems really difficult apriori? (Not a geneticist so I might be completely wrong here!)
Horizontal gene transfer doesn't happen in humans. That's mostly something bacteria do.
There IS weird stuff in humans like viral DNA getting incorporated into the genome, (I've seen estimates that about 10% of the human genome is composed of this stuff!) but this isn't particularly common and the viruses often accrue mutations over time that prevents them from activating or doing anything besides just acting like junk DNA.
Occasionally these viral genes become useful and get selected on (I think the most famous example of this is some ancient viral genes that play a role in placental development), but this is just a weird quirk of our history. It's not like we're prevented from figuring out the role of these genes in future outcomes just because they came from bacteria.
IIUC human intelligence is not in evolutionary equilibrium; it's been increasing pretty rapidly (by the standards of biological evolution) over the course of humanity's development, right up to "recent" evolutionary history. So difficulty-of-improving-on-a-system-already-optimized-by-evolution isn't that big of a barrier here, and we should expect to see plenty of beneficial variants which have not yet reached fixation just by virtue of evolution not having had enough time yet.
(Of course separate from that, there are also the usual loopholes to evolutionary optimality which you listed - e.g. mutation load or variants with tradeoffs in the ancestral environment. But on my current understanding those are a minority of the available gains from human genetic intelligence enhancement.)
TL;DR:
While cultural intelligence has indeed evolved rapidly, the genetic architecture supporting it operates through complex stochastic development and co-evolutionary dynamics that simple statistical models miss. The most promising genetic enhancements likely target meta-parameters governing learning capabilities rather than direct IQ-associated variants.
Longer:
You make a good point about human intelligence potentially being out of evolutionary equilibrium. The rapid advancement of human capabilities certainly suggests beneficial genetic variants might still be working their way through the population.
I'd also suggest this creates an even more interesting picture when combined with developmental stochasticity - the inherent randomness in how neural systems form even with identical genetic inputs (see other comment response to Yair for more detail). This stochasticity means genetic variants don't deterministically produce intelligence outcomes but rather influence probabilistic developmental processes.
What complicates the picture further is that intelligence emerges through co-evolution between our genes and our cultural tools. Following Heyes' cognitive gadgets theory, genetic factors don't directly produce intelligence but rather interact with cultural infrastructure to shape learning processes. This suggests the most valuable genetic variants might not directly enhance raw processing power but instead improve how effectively our brains interface with cultural tools - essentially helping our brains better leverage the extraordinary cultural inheritance (language among other things) we already possess.
Rather than simply accumulating variants statistically associated with IQ, effective enhancement might target meta-parameters governing learning capabilities - the mechanisms that allow our brains to adapt to and leverage our rapidly evolving cultural environment. This isn't an argument against genetic enhancement, but for more sophisticated approaches that respect how intelligence actually emerges.
(Workshopped this with my different AI tools a bit and I now have a paper outline saved on this if you want more of the specific modelling frame lol)
IIUC human intelligence is not in evolutionary equilibrium; it's been increasing pretty rapidly (by the standards of biological evolution) over the course of humanity's development, right up to "recent" evolutionary history.
Why do you believe that? Do we have data that mutations that are associated with higher IQ are more prevalent today than 5,000 years ago?
The best and most recent (last year) evidence based on comparing ancient and modern genomes seems to suggest intelligence was selected very strongly during agricultural revolution (a full SD) and has changed <0.2SD since AD0 [for the populations studied]
It seems that the evolutionary pressure for intelligence wasnt that strong in the last few thousand years compared to selection on many other traits (health and sexual selected traits seem to dominate).
Edit: it would take some effort to dig up this study. Ping me if this is of interest to you.
The evidence I have mentally cached is brain size. The evolutionary trajectory of brain size is relatively easy to measure just by looking at skulls from archaeological sites, and IIRC it has increased steadily through human evolutionary history and does not seem to be in evolutionary equilibrium.
(Also on priors, even before any evidence, we should strongly expect humans to not be in evolutionary equilibrium. As the saying goes, "humans are the stupidest thing which could take off, otherwise we would have taken off sooner". I.e. since the timescale of our takeoff is much faster than evolution, the only way we could be at equilibrium is if a maximal-under-constraints intelligence level just happened to be exactly enough for humans to take off.)
There's probably other kinds of evidence as well; this isn't a topic I've studied much.
If humans are the stupidest thing which could take off, and human civilization arose the moment we became smart enough to build it, there is one set of observations which bothers me:
- The Bering land bridge sank around 11,000 BCE, cutting off the Americas from Afroeurasia until the last thousand years.
- Around 10,000 BCE, people in the Fertile Crescent started growing wheat, barley, and lentils.
- Around 9,000-7,000 BCE, people in Central Mexico started growing corn, beans, and squash.
- 10-13 separate human groups developed farming on their own with no contact between them. The Sahel region is a clear example, cut off from Eurasia by the Sahara Desert.
- Humans had lived in the Fertile Crescent for 40,000-50,000 years before farming started.
Here's the key point: humans lived all over the world for tens of thousands of years doing basically the same hunter-gatherer thing. Then suddenly, within just a few thousand years starting around 12,000 years ago, many separate groups all invented farming.
I don't find it plausible that this happened because humans everywhere suddenly evolved to be smarter at the same time across 10+ isolated populations. That's not how advantageous genetic traits tend to emerge, and if it was the case here, there are some specific bits of genetic evidence I'd expect to see (and I don't see them).
I like Bellwood's hypothesis better: a global climate trigger made farming possible in multiple regions at roughly the same time. When the last ice age ended, the climate stabilized, creating reliable growing seasons that allowed early farming to succeed.
If farming is needed for civilization, and farming happened because of climate changes rather than humans reaching some intelligence threshold, I don't think the "stupidest possible takeoff" hypothesis looks as plausible. Humans had the brains to invent farming long before they actually did it, and it seems unlikely that the evolutionary arms race that made us smarter stopped at exactly the point we became smart enough to develop agriculture and humans just stagnated while waiting for a better climate to take off.
I do agree that the end of the last glacial period was the obvious immediate trigger for agriculture. But the "humans are the stupidest thing which could take off model" still holds, because evolution largely operates on a slower timescale than the glacial cycle.
Specifics: the last glacial period ran from roughly 115k years ago to 12k years ago. Whereas, if you look at a timeline of human evolution, most of the evolution from apes to humans happens on a timescale of 100k - 10M years. So it's really only the very last little bit where an ice age was blocking takeoff. In particular, if human intelligence has been at evolutionary equilibrium for some time, then we should wonder why humanity didn't take off 115k years ago, before the last ice age.
In particular, if human intelligence has been at evolutionary equilibrium for some time, then we should wonder why humanity didn't take off 115k years ago, before the last ice age.
Yes we should wonder that. Specifically, we note
- Humans and chimpanzees split about 7M years ago
- The transition from archaic to anatomically modern humans was about 200k years ago
- Humans didn't substantially develop agriculture before the last ice age started 115k years ago (we'd expect to see archaeological evidence in the form of e.g. agricultural tools which we don't see, while we do see stuff like stone axes)
- Multiple isolated human populations independently developed agriculture starting about 12k years ago
From this we can conclude that either:
- Pre-ice-age humans were on the cusp of being able to develop agriculture, and an extra 100k years of gradual evolution was sufficient to bump them over the relevant threshold
- There was some notable period between 115k and 12k years ago where the rate of selective pressure on humans substantially strengthened or changed direction for some reason. Which might correspond to a very tight population bottleneck:
source: Robust and scalable inference of population history from hundreds of unphased whole-genomes
Note that "bigger brains" might also not have been the adaptation that enabled agriculture.
In the modern era, the fertility-IQ correlation seems unclear; in some contexts, higher fertility seems to be linked with lower IQ, in other contexts with higher IQ. I have no idea of what it was like in the hunter-gatherer era, but it doesn't feel like an obviously impossible notion that very high IQs might have had a negative effect on fertility in that time as well.
E.g. because the geniuses tended to get bored with repeatedly doing routine tasks and there wasn't enough specialization to offload that to others, thus leading to the geniuses having lower status. Plus having an IQ that's sufficiently higher than that of others can make it hard to relate to them and get along socially, and back then there wouldn't have been any high-IQ societies like a university or lesswrong.com to find like-minded peers at.
doesn't feel like an obviously impossible notion that very high IQs might have had a negative effect on fertility in that time as well.
or that some IQ-increasing variants affect stuff other than intelligence in ways that are disadvantageous/fitness-decreasing in some contexts
If you have a mutation that gives you +10 IQ that doesn't make it hard for you to relate with your fellow tribe of hunter-gatherers.
There´s a lot more inbreeding in hunter-gatherer tribes that results in mutations being distributed in the tribe than there is in modern Western society.
The key question is whether you get more IQ if you add IQ-increasing mutations from different tribes together, I don't think that it being disadvantageous to have +30 IQ more than fellow tribe members would be a reason why IQ-increasing mutations that are additive should not exist.
There's plenty of people with an IQ of 140, and plenty of people with an IQ of 60, and it seems most of this variation is genetic, which suggests that there are low hanging fruit available somewhere (though poss bly not in single point mutations).
Also when a couple with low and high IQs respectively have children, the children tend to be normal, and distributed across the full range of IQs. This suggests that there's not some set of critical mutations that only work if the other mutations are present as well, and the effect is more lots of smaller things that are additive.
The book Innate actually goes into detail about a bunch of IQ studies and relating it to neuroscience which is why I really liked reading it!
and it seems most of this variation is genetic
This to me seems like the crux here, in the book innate he states the belief that around 60% of it is genetic and 20% is developmental randomness (since brain development is essentially a stochastic process), 20% being nurture based on twin studies.
I do find this a difficult thing to think about though since intelligence can be seen as the speed of the larger highways and how well (differentially) coupled different cortical areas are. There are deep foundational reasons to believe that our cognition is concepts stacked on top of other concepts such as described in the Active Inference literature. A more accessible and practical way of seeing this is in the book How Emotions Are Made by Lisa Feldman Barett.
Also if you combine this with studies done by Robert Sapolvsky described in the book Why Zebra's Don't Get Ulcers where traumatic events in childhood leads to less IQ down the line we can see how wrong beliefs that stick lead to your stochastic process of development worsening. This is because at timestep T-1 you had a belief or experience that shaped your learning to be way off and at timestep T you're using this to learn. Yes the parameters are set genetically yet from a mechanistic perspective it very much interfaces with your learning.
Twin studies also have a general bias in that they're often made in societies affected by globalisation and that have been connected for a long time. If you believe something like cultural evolution or cognitive gadgets theory what is seen as genetically influenced might actually be genetically influenced given that the society you're in share the same cognitive gadgets. (This is essentially one of the main critiques of twin studies)
So there's some degree that (IQ|Cogntiive Gadgets) could be decomposed genetically but if you don't decompose it given cultural tools it doesn't make sense? There's no fully general intelligence, there's an intelligence that given the right infrastructure then becomes general?
I greatly appreciate this kind of critique, thank you!
My guess is this is too big of an ask, and I am already grateful for your post, but do you have a prediction about how much of the variance would turn out to be causal in the relevant way?
My current best guess is we are going to be seeing some of these technologies used in the animal breeding space relatively soon (within a few years), and so early predictions seem helpful for validating models, and also might also just help people understand how much you currently think the post overestimates the impact of edits.
if I had to guess, then I would guess that 2/3 of the effects are none causal, and the other 1/3 are more or less fully causal, but that all of the effects sizes between 0.5-1 are exaggerated by a factor of 20-50% and the effects estimated below +0.5 IQ are exaggerated by much more.
But I think all of humanity is very confused about what IQ even is, especially outside the ranges of 70-130, so It's hard to say if it is the outcome variable (IQ) or the additive assumption breaks down first, I imagine we could get super human IQ, and that after 1 generation of editing, we could close a lot of the causal gap. I also imagine there are big large edits with large effects, such as making brain cells smaller, like in birds, but that would require a lot of edits to get to work.
Thank you! I'll see whether I can do some of my own thinking on this, as I care a lot about the issue, but do feel like I would have to really dig into it. I appreciate your high-level gloss on the size of the overestimate.
This is why I don’t really buy anybody who claims an IQ >160. Effectively all tested IQs over 160 likely came from a childhood test or have an SD of 20 and there is an extremely high probability that the person with said tested iq substantially regressed to the mean. And even for a test like the WAIS that claims to measure up to 160 with SD 15, the norms start to look really questionable once you go much past 140.
I think I know one person who tested at 152 on the WISC when he was ~11, and one person who ceilinged the WAIS-III at 155 when he was 21. And they were both high-achieving, but they weren’t exceptionally high-achieving. Someone fixated on IQ might call this cope, but they really were pretty normal people who didn’t seem to be on a higher plane of existence. The biggest functional difference between them and people with more average IQs was that they had better job prospects. But they both had a lot of emotional problems and didn’t seem particularly happy.
- The biggest discontinuity is applied at the threshold between spike and slab. Imagine we have mutations that before shrinkage have the values +4 IQ, +2 IQ, +1.9 IQ, and 1.95 is our spike vs. slab cutoff. Furthermore, let's assume that the slab shrinks 25% of the effect. Then we get 4→3, 2→1.5, 1.9→0, meaning we penalize our +2 IQ mutation much less than our +1.9 mutation, despite their similar sizes, and we penalize our +4 IQ effect size more than the +2 IQ effect size, despite it having the biggest effect, this creates an arbitrary cliff where similar-sized effects are treated completely differently based on which side of the cutoff they fall on, and where the one that barely makes it, is the one we are the least skeptical off"
There isn't any hard effect size cutoff like this in the model. The model just finds whatever configurations of spikes have high posteriors given the assumption of sparse normally distributed nonzero effects. I.e., it will keep adding spikes until further spikes can no longer offset their prior improbability via higher likelihood (note this isn't a hard cutoff, since we're trying to approximate the true posterior over all spike configurations; some lower probability configurations with extra spikes will be sampled by the search algorithm).
One of us is wrong or confused, and since you are the genetisist it is probably me, in which case I should not have guessed how it works from statistical intuition but read more, I did not because I wanted to write my post before people forgot yours.
I assumed the spike and slap were across all SNPs, it sounds like it is per LD region, which is why you have multiple spikes?, I also assumed the slab part would shrink the original effect size, which was what I was mainly interested in. You are welcome to pm me to get my discord name or phone number if a quick call could give me the information to not misrepresent what you are doing
My main critique is that I think there is insufficient shrinkage, so it's the shrinkage properties I am mostly interested in getting right :)
This is a critique of How to Make Superbabies on LessWrong.
Disclaimer: I am not a geneticist[1], and I've tried to use as little jargon as possible. so I used the word mutation as a stand in for SNP (single nucleotide polymorphism, a common type of genetic variation).
Background
The Superbabies article has 3 sections, where they show:
Here is a quick summary of the "why" part of the original article articles arguments, the rest is not relevant to understand my critique.
My Position
At a high level, I appreciate the effort in the original post and think most of it is well-written. The main points about the difference between editing and selecting, the parts about diseases, and to some extent longevity, are valid. However, I am skeptical of the claimed IQ effects.
My critique can be broken down into the following subtopics:
I'm less skeptical about disease prevention through genetic editing because some powerful examples exist—like how a single edit can reduce Type 2 diabetes risk by half. This suggests a likely causal relationship rather than just a socioeconomic correlation. The additive assumption is also less problematic when dealing with a small number of high-impact edits. In contrast, IQ appears to be influenced by more than 1,000 genetic variations, most predicted to have much smaller effects than +1 IQ point.
Correlation vs. Causation
This point was mostly raised by lgs and richardjacton and others in the comments to the original post. The issue here is that we only have traits such as IQ and mutations, and thus any relation between the two could be spurious. For example, a mutation might be shared between people who don't like living in old buildings, and thus the causal path runs through lower exposure to leaded paint and asbestos.
While I think the association critique of the baby IQ effects is a very strong argument, I will set that aside for the remainder of this post and focus more on the model assumptions baked into their extrapolations.
It is important to note that when the authors says.
the more clear wording would be "CAUSING the observed association", so it is a claim about which of a cluster of mutations actually "causes" the "non-causal" statistical association between mutation and IQ.
The last part of the author's posts explains the step they did to not overestimate the IQ effects, where they adjust for the poor retest quality of the UK Biobank IQ test, and for assortative mating (people like people like themselves). while this does not fully close the association to causation gap, nor the challenges I present in the next two section, they are still very sensible, so I feel they deserve to be mentioned.
The gold standard for causal evidence in genetic is called Mendelian Randomization, where you measure a biomarker, related to the disease, sort of like this: a people with a specific mutation in a gene for glucose metabolism (at birth) has a higher blood glucose after birth which explains why they have a higher incidence of diabetes.
This is almost as strong evidence as a clinical trial, because you get your genes before your biomarker, so it is correctly "time sorted", and the "mutation" assignment is random, like in a clinical trial. The main limitation is most biomarkers are measured in bio fluids, and even Cerebrospinal fluid, would probably only capture a tiny effect of the IQ, because I suspect that actual causal mutations for IQ probably influences brain development, or protein levels in brain cells, which are hard to measure without influencing IQ.
So the authors went to war with the data they had, which is totally fine, but also why I think they to optimistic with regards to correlation vs causation.
The Additive Effect of Genetics
One of the great paradoxes of statistics is that there is no natural scale between variables in a statistical model. This means it is very hard to know how to link mutations to disease risk. In statistics, we call this the "link function," because it links the predictors (in this case, the mutations) to the outcome (in this case, IQ). The question statisticians ask is: should I link each mutation to the probability, odds, risk, relative risk, or hazard of the outcome? "In other words, we don't know if genetic effects combine by simple addition or through more complex relationships.
However, because most genetic effects are tiny, this is not a significant issue in practice. Let's consider a simple toy example, comparing modeling mutations' association with IQ as either linear or exponential.
Imagine 5 mutations, rarely observed in the same individuals, that have either an additive +1 or a multiplicative ×1.01 effect on IQ, which is assumed to start at 100.
If you have 1 mutation, both models agree because:
Even if you have all 5 mutations, which may rarely occur in your dataset, the two models practically agree:
So one model says +5 IQ smarter, the other one 5.1 IQ. At first glance, it doesn't really matter what link function we use, because as long as we are within normal human variation, most link functions will give similar results. However, the moment we extrapolate to the extreme, such as with 500 mutations under the assumptions above, we get:
So the additive model suggests +500 IQ and the multiplicative model suggests +14377 IQ — hardly the same numbers. This indicates that getting the link function correct is very important when we are predicting far out of sample.
Another issue is the assumption of independence—that we can simply keep stacking mutations associated with IQ and getting the full benefit for each one. Again, in real data, mutations are somewhat rare, so very few people share the same two mutations. The result is somewhat the same as in the case of multiplicative vs. additive link functions: even if there were big correlations between some of the mutations giving rise to the same trait, the fact that most people only have a tiny subset of the mutations means that the correlations can practically be ignored.
However, the moment we start editing to introduce many mutations, we are again very far out of sample, and thus the assumption of independence goes from not being a problem (because it rarely happens) to an article of faith, because you made sure it happened.
For a biological implication of the statistical model above, imagine a set of mutations that makes the prefrontal cortex larger. The first critique would be akin to over-extrapolating to the point where your model says that having a 40kg prefrontal cortex would indeed make you very smart—but unfortunately, the "correct" link function is the one that understands that the prefrontal cortex cannot be bigger than the skull.
A biological example of the correlation between mutations may be one where there are 100 different mutations, each one giving rise to an increase in some neurotransmitter that is generally too low in the population. The average person has 7 mutations, no one in the world has more than 15, which would otherwise be optimal, but all the super babies with more than 25 are so far out of equilibrium that we would have to invent a new term for this type of insanity. This illustrates why simply adding more 'positive' mutations could lead to completely unexpected and potentially harmful outcomes.
Regression towards the null part 1
This section gets a bit technical, but I'll try to explain the core concept: why we should be skeptical of the size of genetic effects, especially for complex traits like intelligence.
There is a concept named "Edlin's rule" or "Edlin's factor"—it's essentially how skeptical you should be of a claim. For example, if a study claims that a treatment improves memory by 20%, Edlin's rule might suggest the real effect is closer to 2%. In psychology, most effects are probably exaggerated by a factor of 10; in physics, it may be only 10%. In statistics, we call this "shrinkage," and in Bayesian statistics, the prior does the shrinking because it pulls towards the default value of no effect (often called the null value).
Genetics is like a mixture of physics and psychology when it comes to Edlin factors: when a disease is basically explained by one gene, you need to shrink very little, but with traits with 1000+ associations, you probably need to shrink more.
In the original post, it takes about 500 mutations to get a 50 IQ point increase, which means each mutation contributes about 0.1 IQ points. Since this is a tiny effect compared to the disease plot, where maybe 5 mutations are enough to eradicate a disease, intuitively this means we should shrink differently in the two cases.
Genetics is particularly ill-suited for classical frequentist statistics, because of the combination of the high number of possible mutations and high local correlations. These correlations arise from the fact that when the genome is cut and reassembled in the process of making natural babies, mutations that are close together in the genome have two annoying properties: they simultaneously affect the same phenotype AND are in the same "cutting frame" named LD (linkage disequilibrium) region, thus having very high local correlation.
The authors used a sophisticated statistical method called 'spike-and-slab' that essentially sorts genetic effects into two categories: tiny effects that are probably just noise (the 'spike' at zero) and larger effects that are likely real but might still be overestimated (the 'slab'). This method can adjust differently for simple traits versus complex ones like IQ."
Optional: Regression towards the null part 2
This section tries to explain why the spike and slap method is insufficient, it assumes a higher familiarity with math than the rest of the post.
A nice feature of the spike-and-slab prior is that it is refitted for each association, so a different spike-and-slab prior will be estimated for the disease explained by 5 mutations and for IQ, allowing us to have a different level of 'skepticism in the two settings.
There is, however, one issue with the spike-and-slab prior. The more effects you put into the "spike" part, the larger effects are left to be modeled by the "slab" part, creating a dual paradox:
Ideally, we would use a fat-tailed prior (like a t distribution or Cauchy distribution), which is continuous and thus behaves like a sane version of the spike-and-slab prior[2], in that it allows for big effects, and shrinks small effects a lot. With most fat-tailed prior, there is an inflection point, after which, the further you get away from 0, the less you are shrunk. In this case, the +2 and +1.9 mutations would end up almost in the same place, and the +4 mutation would shrink the least, if it is above the inflection point.
In summary, the statistical methods used to estimate genetic effects on IQ likely don't fully account for this 'winner's curse' problem, potentially making the projected benefits of gene editing for intelligence overly optimistic, beyond the issues of causality and additivity.
Andrew Gelman has a scalable method where you can convert every effect into a signal-to-noise ratio, which allows you to derive a signal-to-noise prior with fat tails. This is basically a shrinkage function that says (or can say, if the data agrees) that big effects should shrink very little and small effects a lot. This method could work for genetics if the field got into the habit of "saving" all the statistically insignificant associations, so we could also "fit" the middle part of the prior.
Final Note
Lastly, the post discusses "how much IQ" we could improve per edit if we had more data, where they sort of assume that if they had more data, they could find edits with stronger effects[3]. However, it may also be the case that if they had more data, they would see that the real effects are actually smaller" to be more direct: More data might actually reveal that the true effects are smaller than currently estimated, not larger.
As I said, I think the original post is great, so while I think it is very hard to estimate how many edits we would need to get to get even a few extra IQ points, there is no doubt, that if we start doing these edits we will suddenly have data on which of these are actually causal, and then, like the chickens being 40 sd larger, we could eventually get to 600 IQ (also 40 sd) smarter, with the limitation that chickens have had 100 generations since the 1950 and we have had 2, so if we want to speed this up we also need good IQ tests for babies[4].
Though I have a Master's in biochemistry, a PhD in bioinformatics, 10+ years of experience with the sister field of proteomics, and I work as a Statistician/Data Scientist for a pharmaceutical company, where I, among other things, have helped geneticists set up causal models similar to Mendelian Randomization.
Though it's mathematical properties are super annoying, which is why it's preferred by keyboard warriors on LW like me, but not used by the people in the original post, who are limited to the best tools the field of genetics has to offer.
This may be sort of a straw man, it seems they have some large effects that are "lost" when they do the fine-mapping, in which case it makes sense to assume there are bigger IQ fish out there, though my shrinkage point still stands, even if it is a bigger number we need to shrink.
That predict their adult IQ well, and that is robust to crazy stuff like a "live fast die young gene" that may make you smart as a 2 year, but dumb as an adult because you matured to fast.