People seem to be continually surprised, over and over again, by the new capabilities of big machine learning models, such as PaLM, DALL-E, Chinchilla, SayCan, Socratic Models, Flamingo, and Gato (all in the last two months!). Luckily, there is a famous paper on how AI progress is governed by scaling laws, where models predictably get better as they get larger. Could we forecast AI progress ahead of time by seeing how each task gets better with model size, draw out the curve, and calculate which size model is needed to reach human performance?
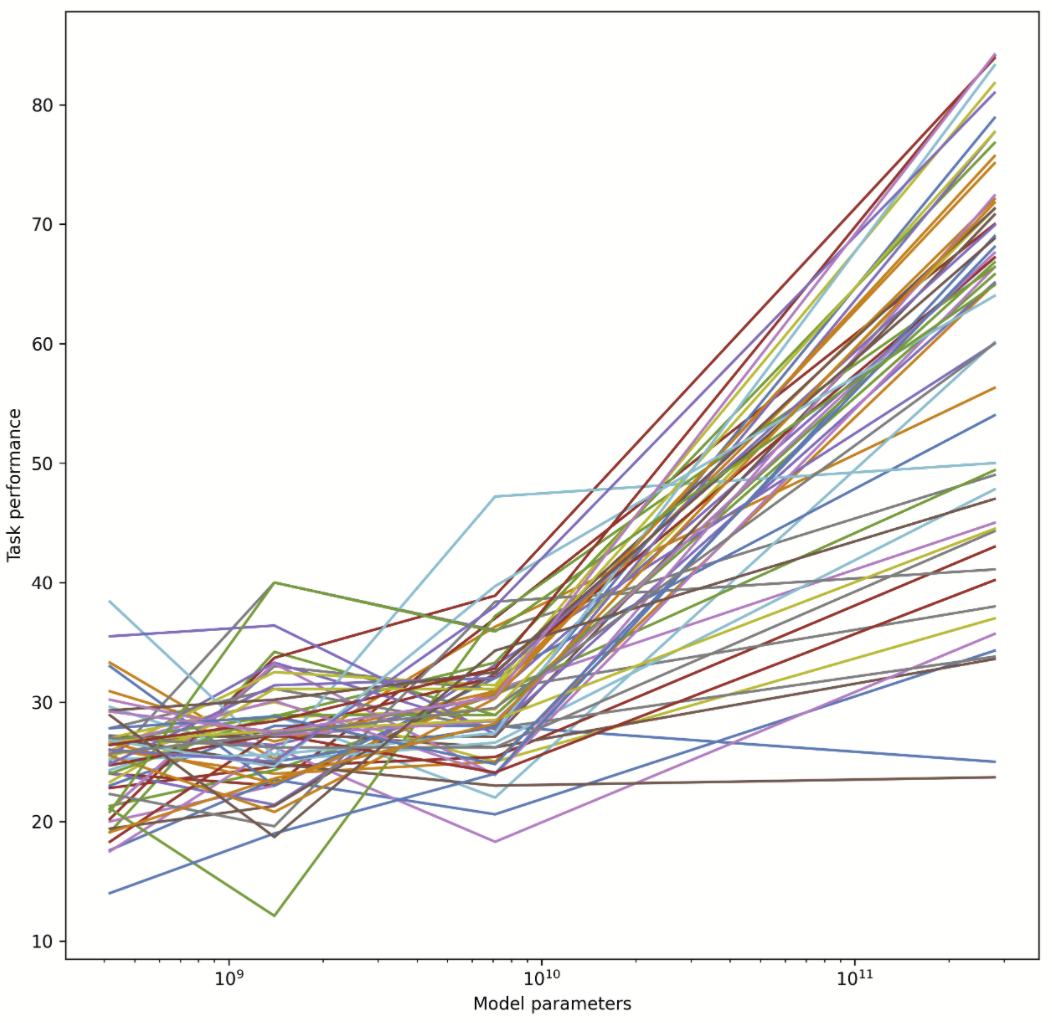
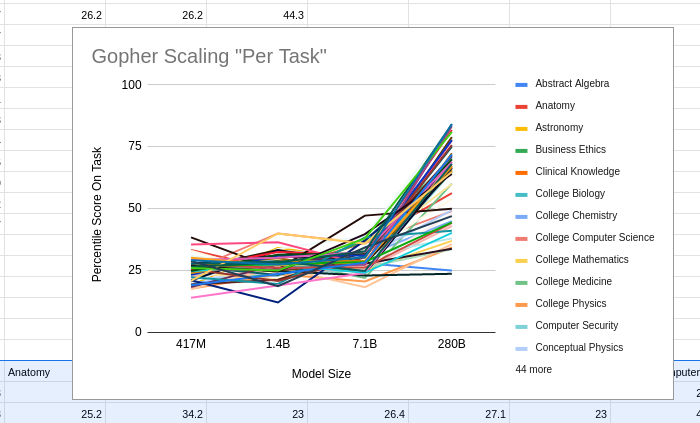
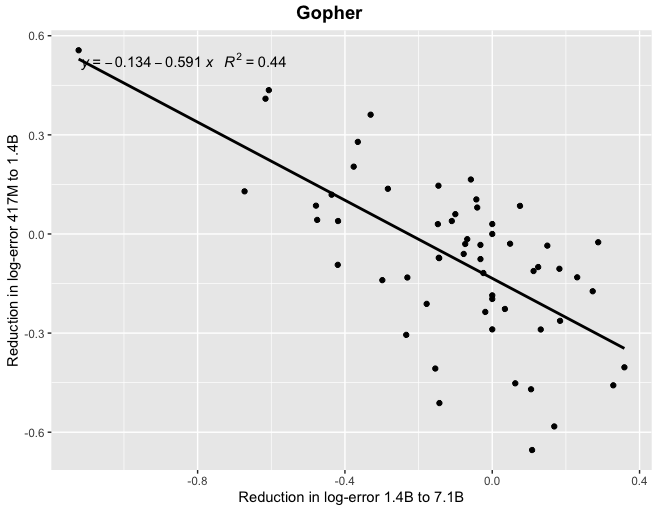
I tried this, and apparently the answer is no. In fact, whether AI has improved on a task recently gives us exactly zero predictive power for how much the next model will improve on the same task. The sheer consistency of this unpredictability is remarkable, almost like a law of statistical thermodynamics. No matter what I plug in, the correlation is always zero! For example, does a task improving rapidly when you go from a small model to a 7B parameter model predict similar improvement when you go from a 7B model to Gopher's 280B? No:
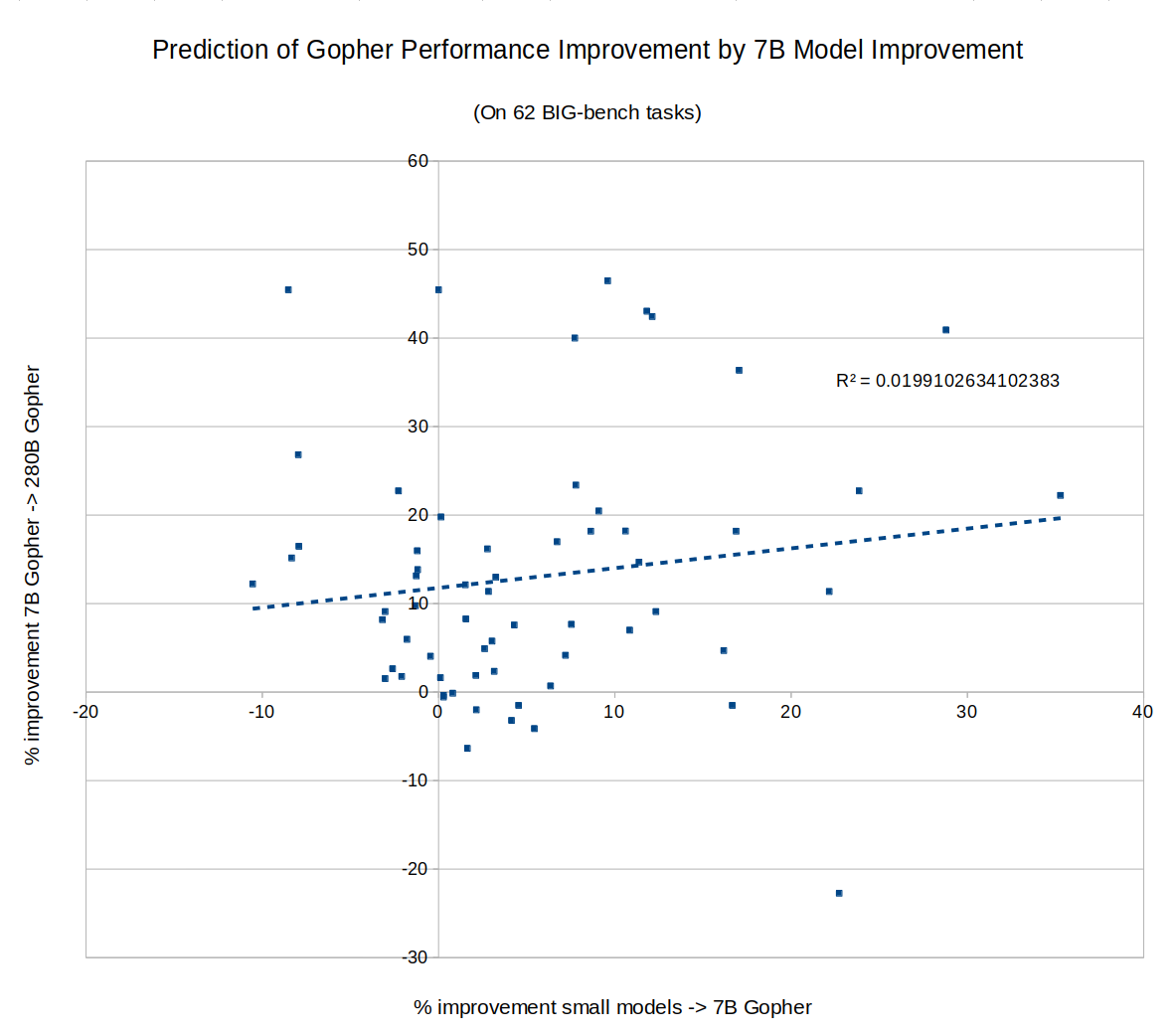
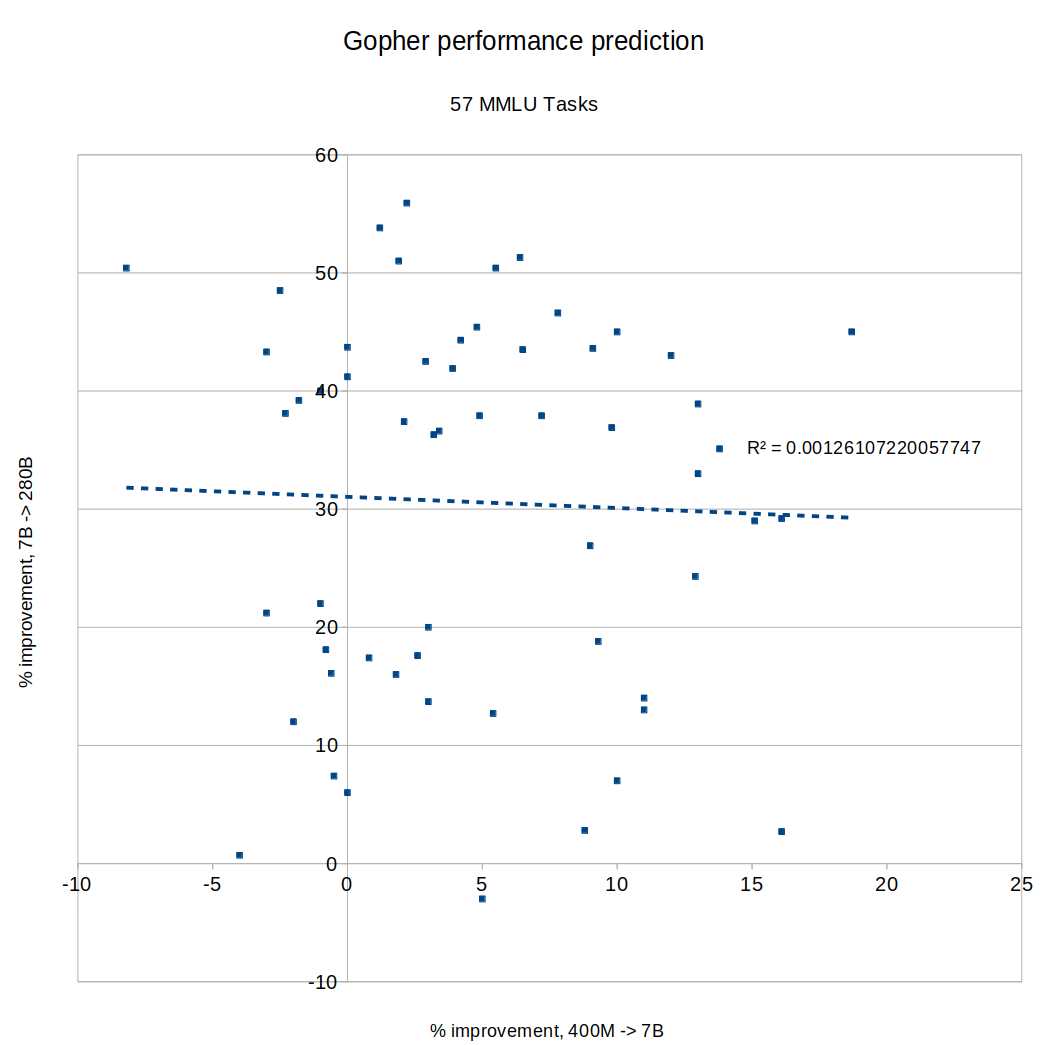
I tried making the same graph with MMLU tasks instead of BIG-bench, same result:
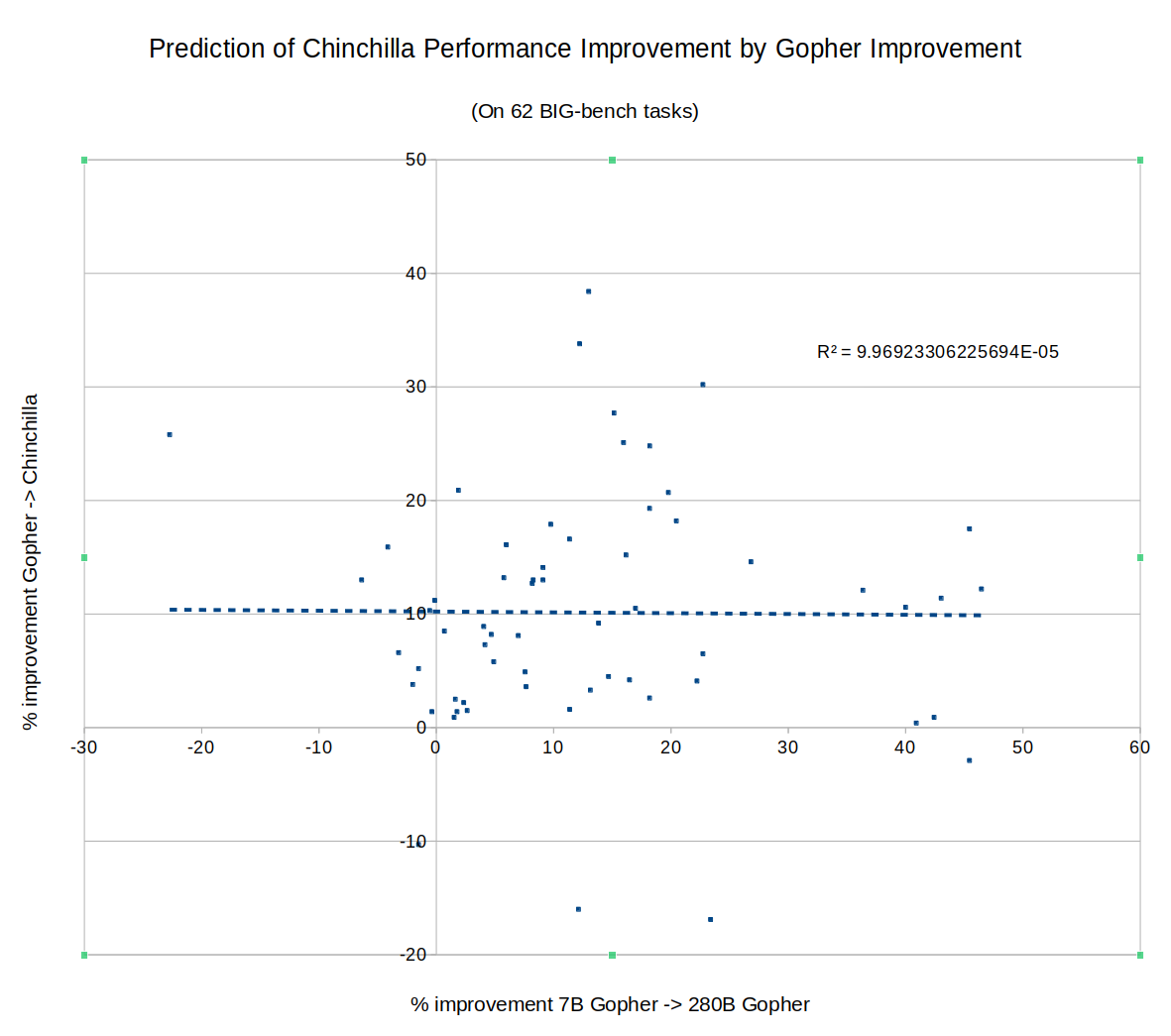
What about DeepMind's new Chinchilla? Did rapid improvement of a task on Gopher predict continued improvement going from Gopher to Chinchilla? Nope:
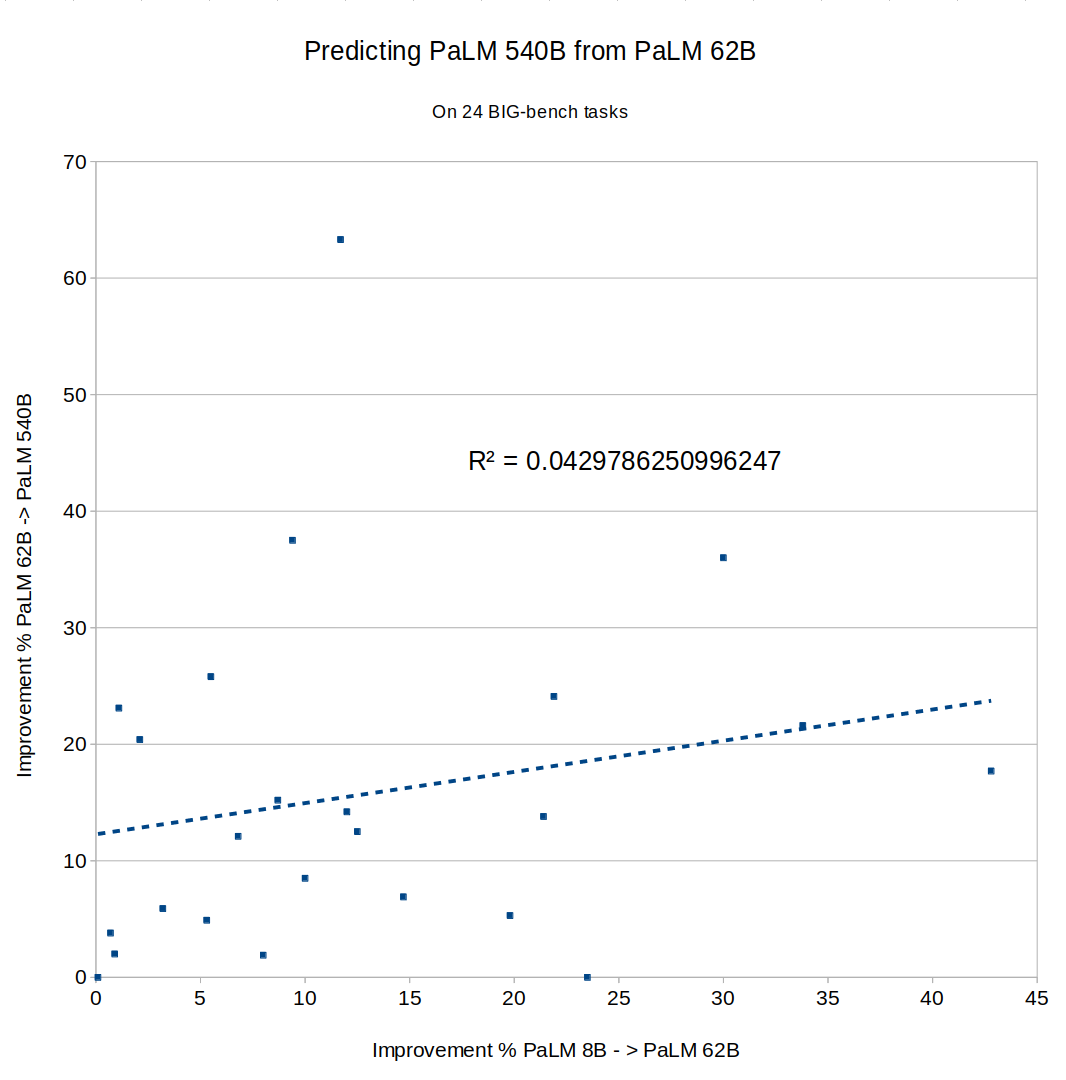
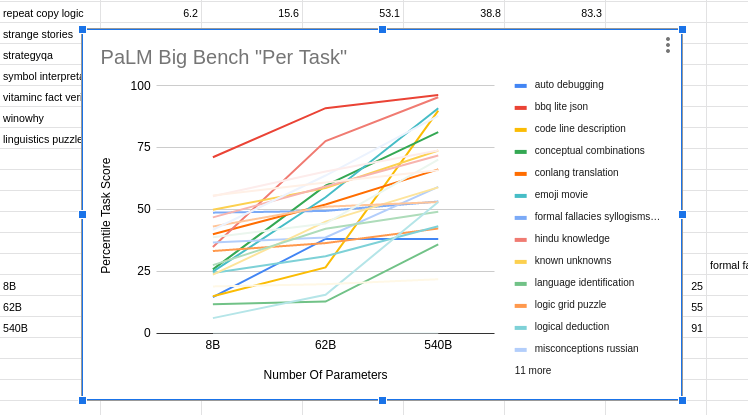
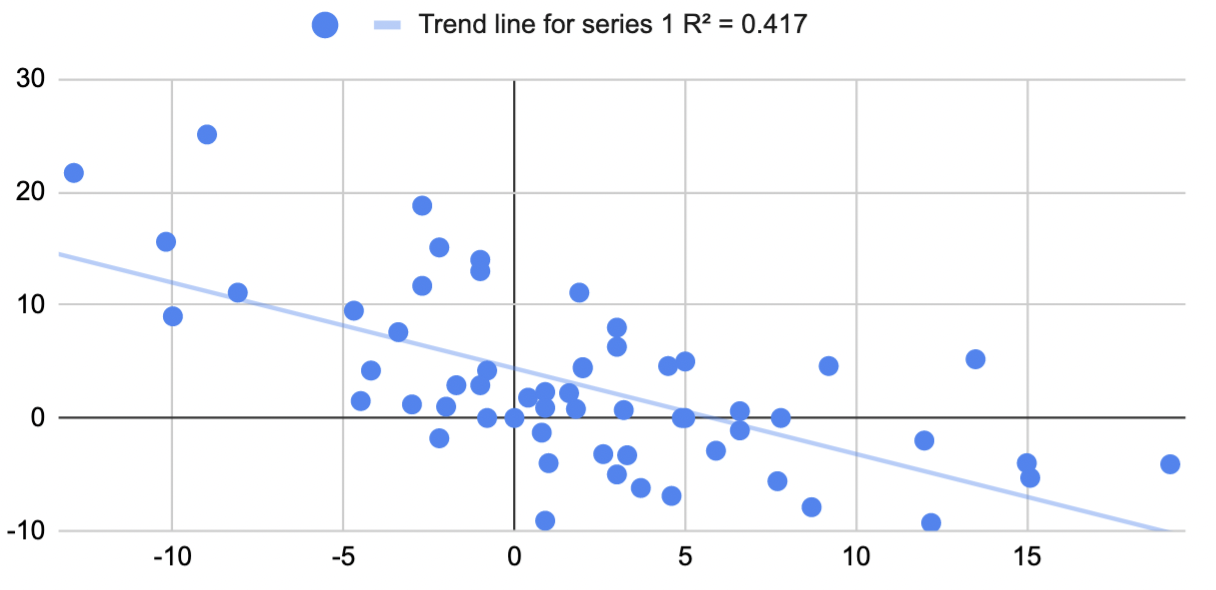
What about Google's PaLM? The full results of PaLM on BIG-bench don't seem to have been published yet, so I couldn't directly compare to Chinchilla or Gopher, but the PaLM paper described an 8B parameter model, a 62B model and a 540B model. Did fast improvement from 8B to 62B predict improvement from 62B to 540B? Not really, R^2 = 0.04:
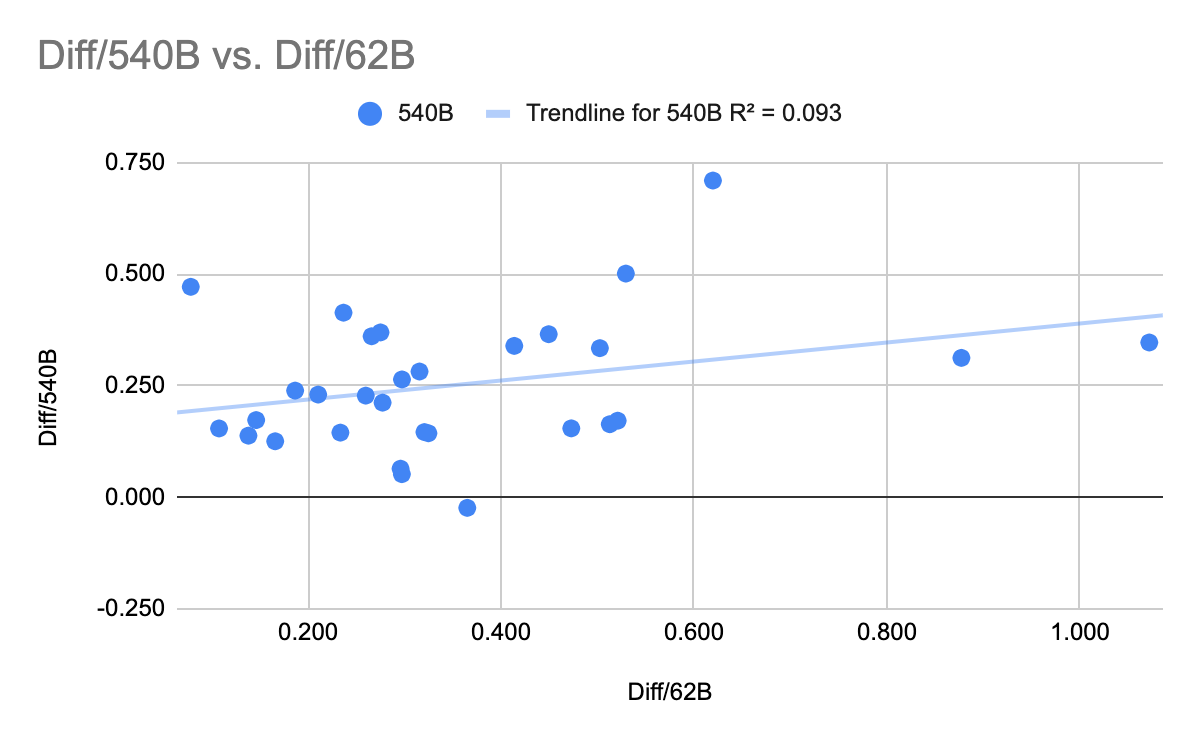
PaLM also provides data on 30 different NLU benchmark tasks. Plot those and you get the same thing:
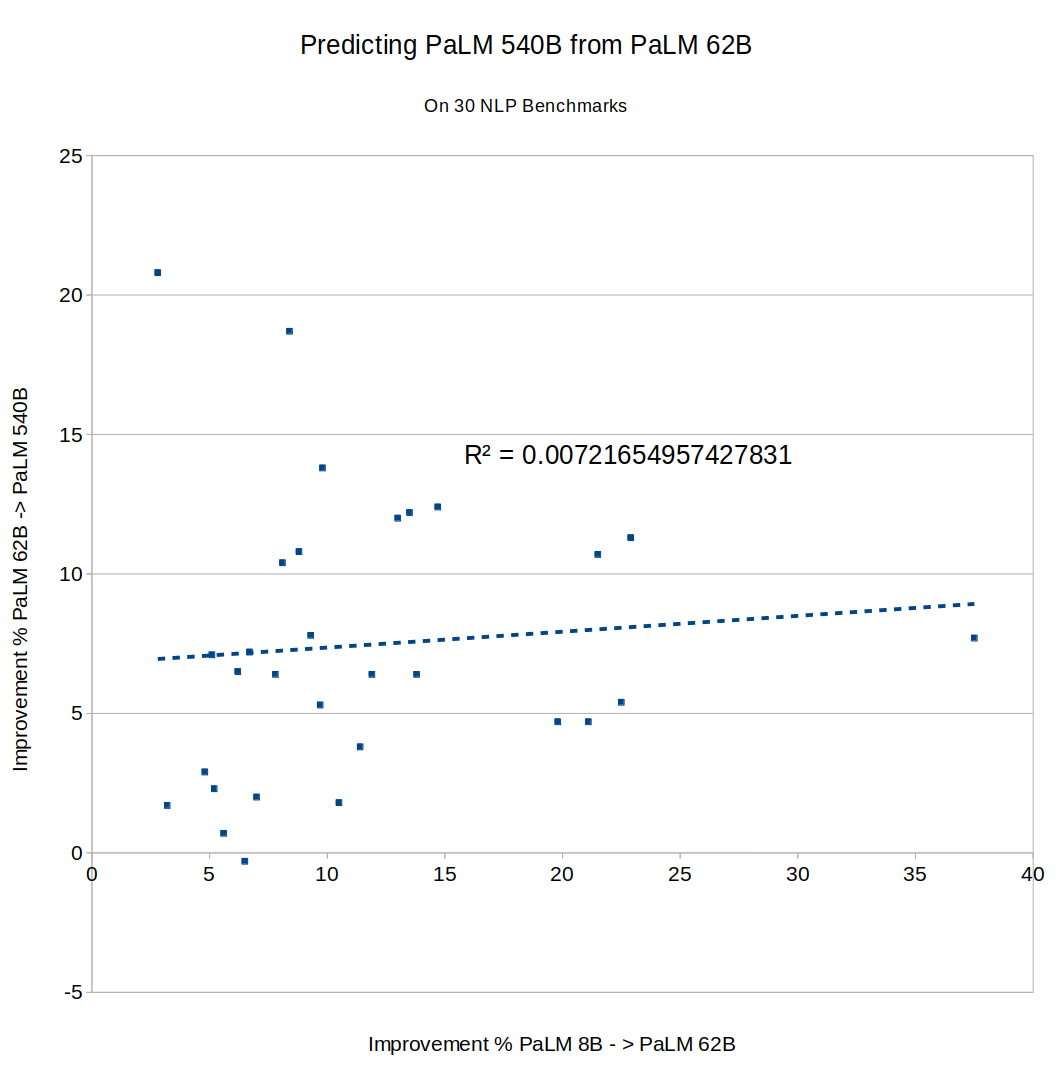
The results here seem pretty clear, but I'm honestly not sure how to interpret them. Before trying this, I assumed you would find that some tasks are "easy" and scale quickly, while others are "hard" and scale slowly. But that would get you high predictability, since fast progress between one pair of models would imply that the task is inherently "easy", and predict (perhaps with some noise) fast progress on the next pair. I didn't see that.
You could also have a theory where tasks scaled similarly (all are of comparable "difficulty"), but there was some noise between model training runs, so that task performance on any given run would bounce up and down around some "true" average value. (Since if you did badly on one run, you'd expect to regress to the mean, and do unusually well on the next.) But I didn't see that either. The two effects (some tasks being intrinsically easier, and individual model runs being noisy) could also cancel out, since one implies a positive correlation and the other implies a negative one... but it seems unlikely that they would exactly cancel every time!
Is AI task performance a type of submartingale, like a stock market index that goes up over time, but where each particular movement is intrinsically unpredictable? Maybe we can compare it to the growth in company profits, where the literature says that companies might grow slowly or quickly, but whether a company has grown fast recently has zero predictive power for future growth. I guess if we knew what we were doing, it wouldn't be called research.
EDIT: By request, here's a Google sheet with the raw data, copy-pasted from the Gopher, PaLM and Chinchilla papers: https://docs.google.com/spreadsheets/d/1Y_00UcsYZeOwRuwXWD5_nQWAJp4A0aNoySW0EOhnp0Y/edit?usp=sharing
EDIT 2: Several people suggested using logits instead of raw percentages. I tried that with the Gopher numbers, still got zero correlation:
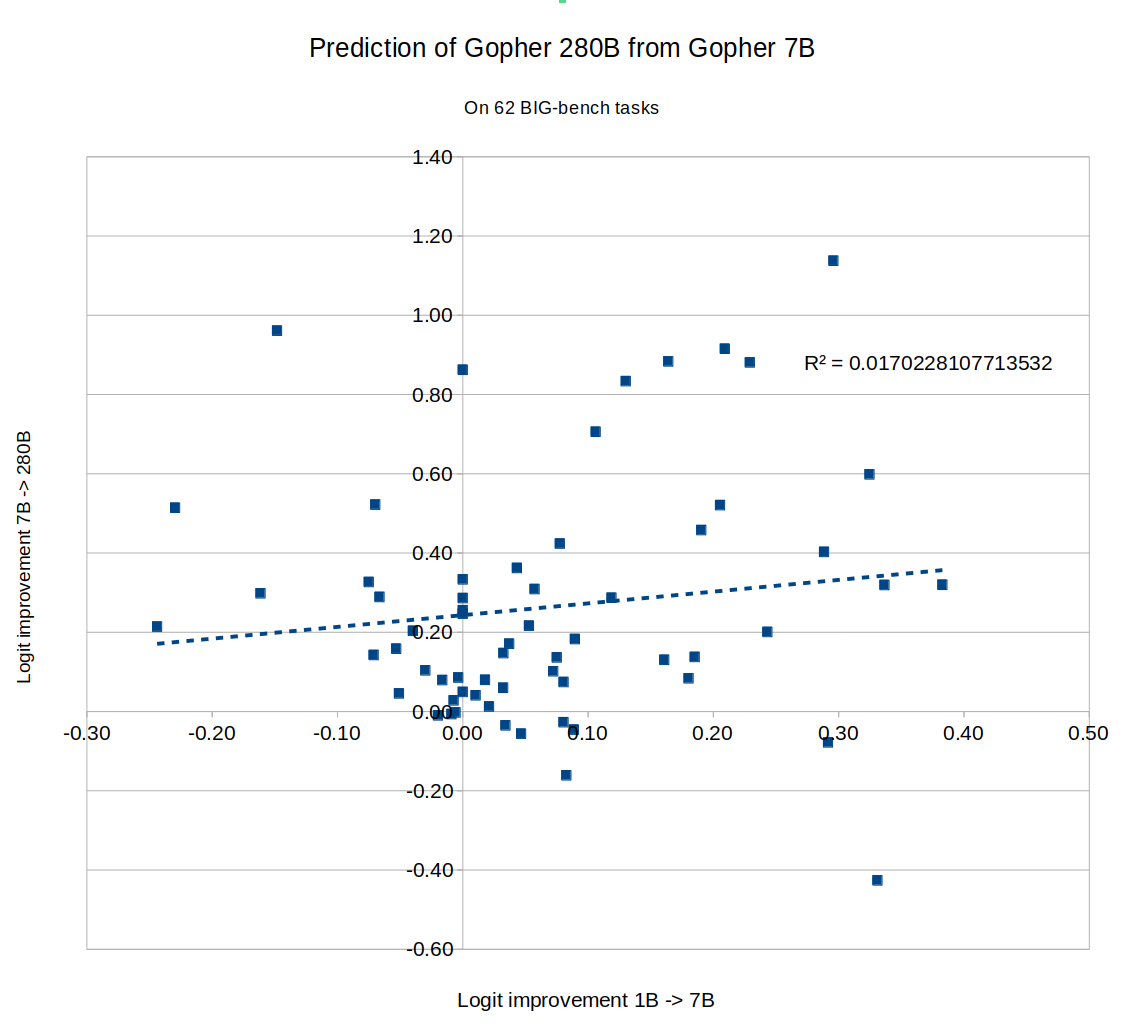
EDIT 3: Tamay noted that if you try to predict 7B Gopher from 1B Gopher, you get a negative correlation:
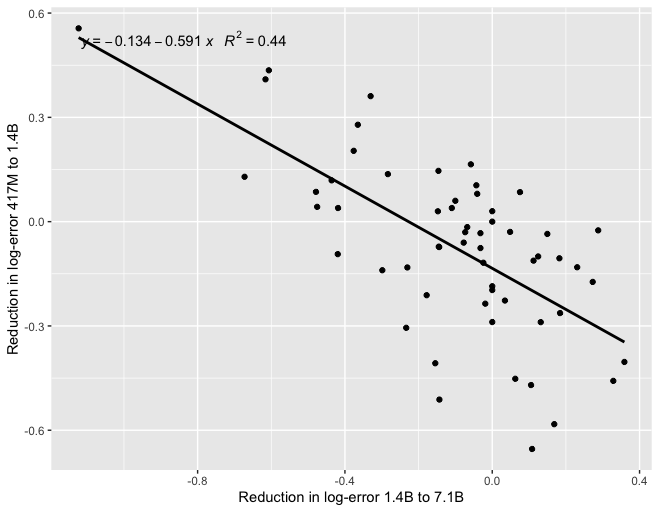
If the models become small enough, maybe this means that scale isn't helping you at that level, so the differences between performances are noise and you should expect mean reversion? Eg., here is a graph of a negative correlation between different "runs", where the "runs" are just draws from a random Gaussian:
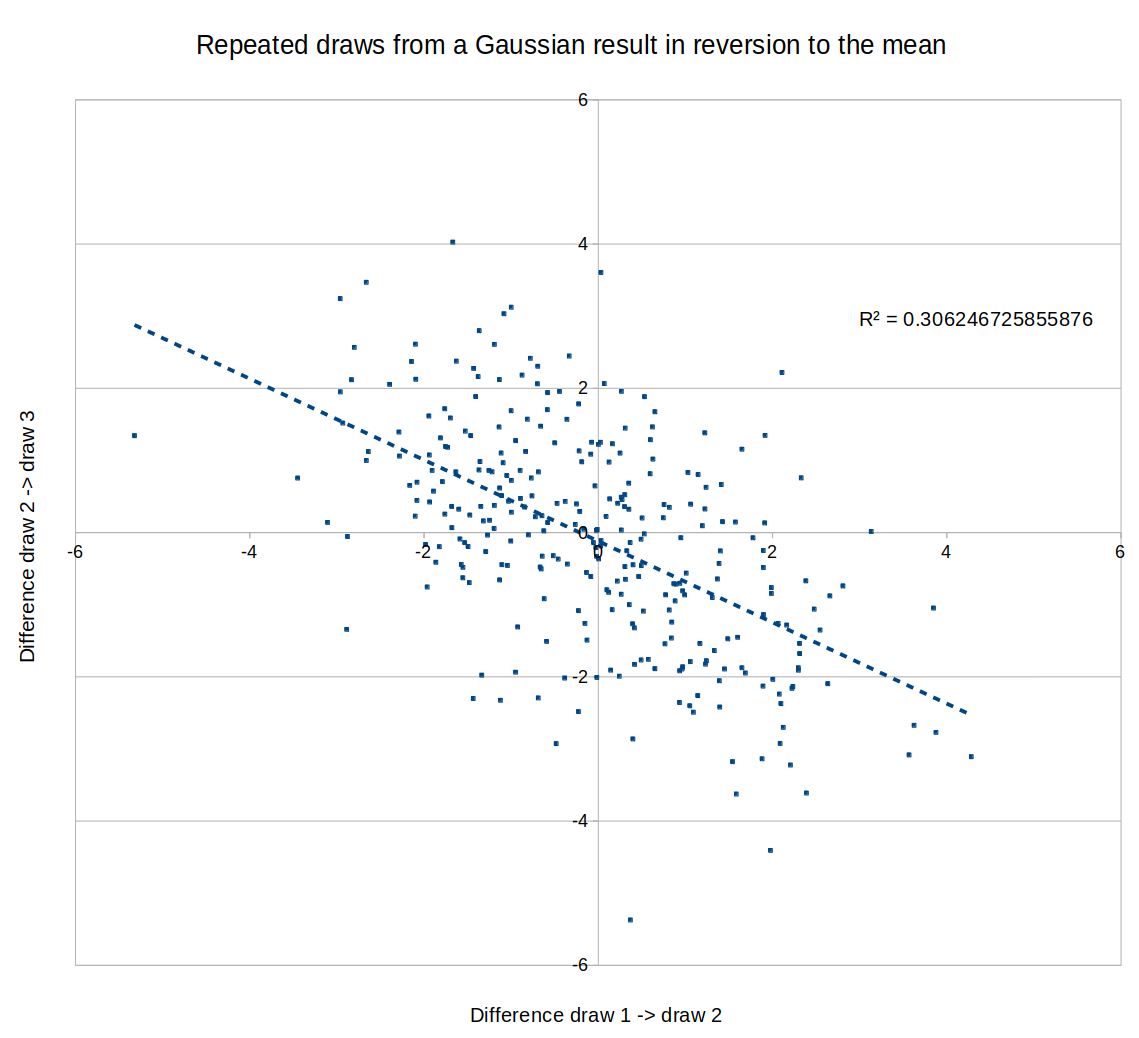
{kind=link}
{kind=link}
tl;dr: if models unpredictably undergo rapid logistic improvement, we should expect zero correlation in aggregate.
If models unpredictably undergo SLOW logistic improvement, we should expect positive correlation. This also means getting more fine-grained data should give different correlations.
To condense and steelman the original comment slightly:
Imagine that learning curves all look like logistic curves. The following points are unpredictable:
Would this result in zero correlation between model jumps?
So each model is in one of the following states:
Then the possible transitions (small -> 7B -> 280B) are:
1->1->1 : slight negative correlation due to regression to the mean
1->1->2: zero correlation since first change is random, second is always positive
1->1->3: zero correlation as above
1->2->2: positive correlation as the model is improving during both transitions
1->2->3: positive correlation as the model improves during both transitions
1->3->3: zero correlation, as the model is improving in the first transition and random in the second
2->2->2: positive correlation
2->2->3: positive correlation
2->3->3: zero correlation
3->3->3: slight negative correlation due to regression to the mean
That's two cases of slight negative correlation, four cases of zero correlation, and four cases of positive correlation.
However positive correlation only happens if the middle state is state 2, so only if the 7B model does meaningfully better than the small model, AND is not already saturated.
If the logistic jump is slow (takes >3 OOM) AND we are able to reach it with the 7B model for many tasks, then we would expect to see positive correlation.
However if we assume that
Then we will rarely see a 2->2 transition, which means the actual possibilities are:
Two cases of slight negative correlation
Four cases of zero correlation
One case of positive correlation (1->2->3, which should be less common as it requires 'hitting the target' of state 2)
Which should average out to around zero or very small positive correlation, as observed.
However, more precise data with smaller model size differences would be able to find patterns much more effectively, as you could establish which of the transition cases you were in.
However again, this model still leaves progress basically "unpredictable" if you aren't actively involved in the model production, since if you only see the public updates you don't have the more precise data that could find the correlations.
This seems like evidence for 'fast takeoff' style arguments--since we observe zero correlation, if the logistic form holds, that suggests that ability to do a task at all is very near in cost to ability to do a task as well as possible.