Hi all, I've been working on some AI forecasting research and have prepared a draft report on timelines to transformative AI. I would love feedback from this community, so I've made the report viewable in a Google Drive folder here.
With that said, most of my focus so far has been on the high-level structure of the framework, so the particular quantitative estimates are very much in flux and many input parameters aren't pinned down well -- I wrote the bulk of this report before July and have received feedback since then that I haven't fully incorporated yet. I'd prefer if people didn't share it widely in a low-bandwidth way (e.g., just posting key graphics on Facebook or Twitter) since the conclusions don't reflect Open Phil's "institutional view" yet, and there may well be some errors in the report.
The report includes a quantitative model written in Python. Ought has worked with me to integrate their forecasting platform Elicit into the model so that you can see other people's forecasts for various parameters. If you have questions or feedback about the Elicit integration, feel free to reach out to elicit@ought.org.
Looking forward to hearing people's thoughts!
Hey everyone! I’m Eleni. I’m doing an AI timelines internship with Open Phil and am going to investigate that topic over the next few months.
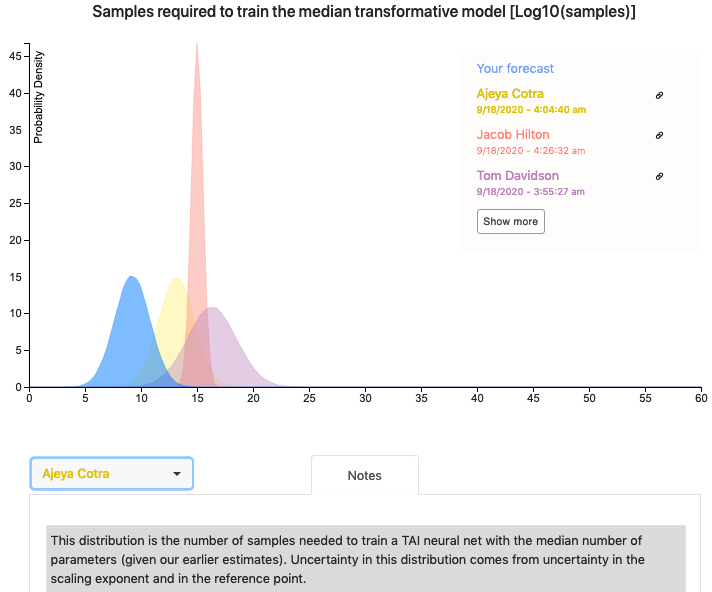
It seems plausible to a lot of people that simply scaling up current ML architectures with more data and compute could lead to transformative AI. In particular, the recent successes of GPT-3 and the impressive scaling observed seem to suggest that a scaled-up language model could have a transformative impact. This hypothesis can be modeled within the framework of Ajeya’s report by considering that a transformative model would have the same effective horizon length as GPT-3 and assuming that the scaling will follow the same laws as current Transformer models. I’ve added an anchor corresponding to this view in an updated version of the quantitative model that can be found (together with the old one) here, where the filenames corresponding to the updated model begin with “(GPT-N)”. Please note that Ajeya’s best guess sheet hasn’t been updated to take this new anchor into account. A couple of minor numerical inconsistencies between the report and the quantitative model were also fixed.