This is a special post for quick takes by Aaron Bergman. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Sharing https://earec.net, semantic search for the EA + rationality ecosystem. Not fully up to date, sadly (doesn't have the last month or so of content). The current version is basically a minimal viable product!
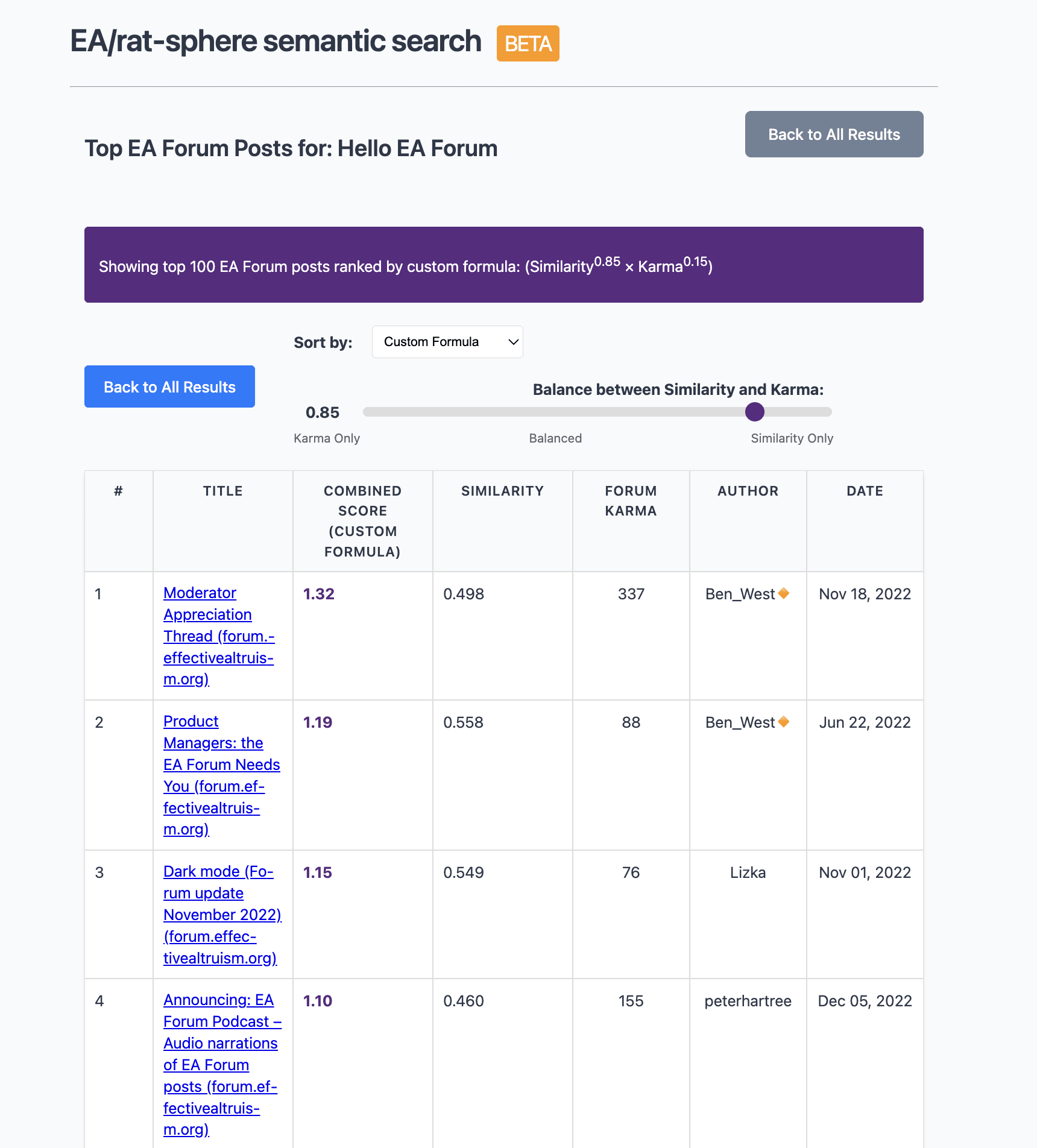
On the results page there is also an option to see EA Forum only results which allow you to sort by a weighted combination of karma and semantic similarity thanks to the API.
Unfortunately there's no corresponding system for LessWrong because of (perhaps totally sensible) rate limits (the EA Forum offers a bots site for use cases like this with much more permissive access).
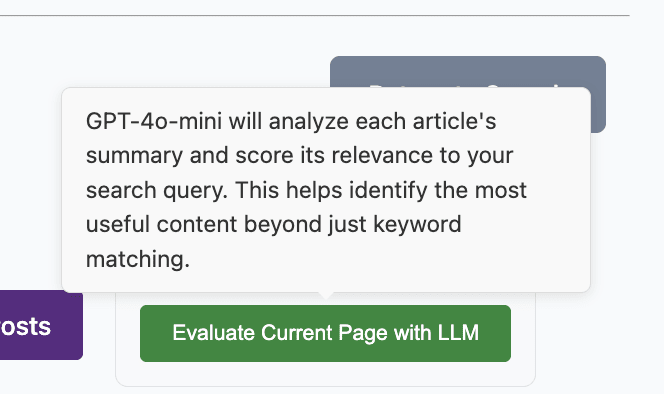
Final feature to note is that there's an option to have gpt-4o-mini "manually" read through the summary of each article on the current screen of results, which will give better evaluations of relevance to some query (e.g. "sources I can use for a project on X") than semantic similarity alone.
Still kinda janky - as I said, minimal viable product right now. Enjoy and feedback is welcome!
Thanks to @Nathan Young for commissioning this!
Training to generalize (and training to train to generalize, etc.)
Inspired by Eliezer's Lethalities post and Zvi's response:
Has there been any research or writing on whether we can train AI to generalize out of distribution?
I'm thinking, for example:
- Train a GPT-like ML system to predict the next word given a string of text only using, say, grade school-level writing (this is one instance of the object level
- Assign the system a meta-level award based on how well it performs (without any additional training) at generating the next word from more advanced, complex writing (likely using many independent tests of this task)
- After all these independent samples are taken, provide the its aggregate or average score as feedback
- (Maybe?) repeat steps I and I.I on a whole new set of training and testing texts (e.g., using text from a different natural language like Mandarin), and do this step and arbitrary number of times
- Repeat this step using French text, then Korean, then Arabic, etc.
- After each of the above steps, the system should (I assume) improve at the general task of generalizing from simple human writing to more complex human writing, (hopefully) to the point of being able to perform well at generalizing from simple Hindi (or whatever) text to advanced Hindi prediction even if it had never seen advanced Hindi text before.
- ^Steps 1-3 constitute the second meta-level of training an AI to generalize, but we can easily treat this process as a single training instance (e.g., rating how well the AI generalizes to Hindi advanced text after having been trained on doing this in 30 other languages) and iterate over and over again. I think this would look like:
- Running the analogs of steps 1-4 on generalizing from
- (a) simple text to advanced text in many languages
- (b) easy opponents to hard ones across many games,
- (c) photo generation of common or general objects ("car") to rare/complex/specific ones ("interior of a 2006 Honda Accord VP"), across many classes of object
- And (hopefully) the system would eventually be able to generalize from simple python code training data to advanced coding tasks even though it had never seen any coding at all before this.
- Running the analogs of steps 1-4 on generalizing from
And, of course, we can keep on adding piling layers on.
A few minutes of hasty Googling didn't turn up anything on this, but it seems pretty unlikely to be an original idea. But who knows! I wanted to get the idea written down and online before I had time to forget about it.
On the off chance it hasn't been beaten thought about to death yet by people smarter than myself, I would consider together longer, less hastily written post on the idea
Curated and popular this week
Sharing https://earec.net, semantic search for the EA + rationality ecosystem. Not fully up to date, sadly (doesn't have the last month or so of content). The current version is basically a minimal viable product!
On the results page there is also an option to see EA Forum only results which allow you to sort by a weighted combination of karma and semantic similarity thanks to the API.
Unfortunately there's no corresponding system for LessWrong because of (perhaps totally sensible) rate limits (the EA Forum offers a bots site for use cases like this with much more permissive access).
Final feature to note is that there's an option to have gpt-4o-mini "manually" read through the summary of each article on the current screen of results, which will give better evaluations of relevance to some query (e.g. "sources I can use for a project on X") than semantic similarity alone.
Still kinda janky - as I said, minimal viable product right now. Enjoy and feedback is welcome!
Thanks to @Nathan Young for commissioning this!