This is a special post for quick takes by LWLW. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Making the (tenuous) assumption that humans remain in control of AGI, won't it just be an absolute shitshow of attempted power grabs over who gets to tell the AGI what to do? For example, supposing OpenAI is the first to AGI, is it really plausible that Sam Altman will be the one actually in charge when there will have been multiple researchers interacting with the model much earlier and much more frequently? I have a hard time believing every researcher will sit by and watch Sam Altman become more powerful than anyone ever dreamed of when there's a chance they're a prompt away from having that power for themselves.
You're assuming that:
- There is a single AGI instance running.
- There will be a single person telling that AGI what to do
- The AGI's obedience to this person will be total.
I can see these assumptions holding approximately true if we get really really good at corrigibility and if at the same time running inference on some discontinuously-more-capable future model is absurdly expensive. I don't find that scenario very likely, though.
what is the plan for making task-alignment go well? i am much more worried about the possibility of being at the mercy of some god-emperor with a task-aligned AGI slave than I am about having my atoms repurposed by an unaligned AGI. the incentives for blackmail and power-consolidation look awful.
i am much more worried
Why? I figure all the AI labs worry mostly about how to get the loot, without ensuring that there's going to be any loot in the first place. Thus there won't be any loot, and we'll go extinct without any human getting to play god-emperor. It seems to me like trying to build an AGI tyranny is an alignment-complete challenge, and since we're not remotely on track to solving alignment, I don't worry about that particular bad ending.
the difficulty of alignment is still unknown. it may be totally impossible, or maybe some changes to current methods (deliberative alignment or constitutional ai) + some R&D automation can get us there.
The question is not whether alignment is impossible (though I would be astonished if it was), but rather whether it's vastly easier to increase capabilities to AGI/ASI than it is to align AGI/ASI, and ~all evidence points to yes. And so the first AGI/ASI will not be aligned.
Your argument is actually possible, but what evidences do you have, that make it the likely outcome?
The very short answer is that the people with the most experience in alignment research (Eliezer and Nate Soares) say that without an AI pause lasting many decades the alignment project is essentially hopeless because there is not enough time. Sure, it is possible the alignment project succeeds in time, but the probability is really low.
Eliezer has said that AIs based on the deep-learning paradigm are probably particularly hard to align, so it would probably help to get a ban or a long pause on that paradigm even if research in other paradigms continues, but good luck getting even that because almost all of the value currently being provided by AI-based services are based on deep-learning AIs.
One would think that it would be reassuring to know that the people running the labs are really smart and obviously want to survive (and have their children survive) but it is only reassuring before one listens to what they say and reads what they write about their plans on how to prevent human extinction and other catastrophic risks. (The plans are all quite inadequate.)
You’re probably right but I guess my biggest concern is the first superhuman alignment researchers being aligned/dumb enough to explain to the companies how control works. It really depends on if self-awareness is present as well.
Everything feels so low-stakes right now compared to future possibilities, and I am envious of people who don’t realize that. I need to spend less time thinking about it but I still can’t wrap my head around people rolling a dice which might have s-risks on it. It just seems like a -inf EV decision. I do not understand the thought process of people who see -inf and just go “yeah I’ll gamble that.” It’s so fucking stupid.
- They are not necessarily "seeing" -inf in the way you or me are. They're just kinda not thinking about it, or think that 0 (death) is the lowest utility can realistically go.
- What looks like an S-risk to you or me may not count as -inf for some people.
I think humanity's actions right now are most comparable those of a drug addict. We as a species dont have the necessary equivalent of executive function and self control to abstain from racing towards AGI. And if we're gonna do it anyway, those that shout about how we're all gonna die just ruin everyone's mood.
Or for that matter to abstain towards burning infinite fossil fuels. We happen to not live on a planet with enough carbon to trigger a Venus-like cascade, but if that wasn't the case I don't know if we could stop ourselves from doing that either.
The thing is, any kind of large scale coordination to that effect seems more and more like it would require a degree of removal of agency from individuals that I'd call dystopian. You can't be human and free without a freedom to make mistakes. But the higher the stakes, the greater the technological power we wield, the less tolerant our situation becomes of mistakes. So the alternative would be that we need to willingly choose to slow down or abort entirely certain branches of technological progress - choosing shorter and more miserable lives over the risk of having to curtail our freedom. But of course for the most part, not unreasonably!, we don't really want to take that trade-off, and ask "why not both?".
What looks like an S-risk to you or me may not count as -inf for some people
True but that's just for relatively "mild" S-risks like "a dystopia in which AI rules the world, sees all and electrocutes anyone who commits a crime by the standards of the year it was created in, forever". It's a bad outcome, you could classify it as S-risk, but it's still among the most aligned AIs imaginable and relatively better than extinction.
I simply don't think many people think about what does an S-risk literally worse than extinction look like. To be fair I also think these aren't very likely outcomes, as they would require an AI very aligned to human values - if aligned for evil.
No, I mean, I think some people actually hold that any existence is better than non-existence, so death is -inf for them and existence, even in any kind of hellscape, is above-zero utility.
I just think any such people lack imagination. I am 100% confident there exists an amount of suffering that would have them wish for death instead; they simply can't conceive of it.
One way to make this work is to just not consider your driven-to-madness future self an authority on the matter of what's good or not. You can expect to start wishing for death, and still take actions that would lead you to this state, because present!you thinks that existing in a state of wishing for death is better than not existing at all.
I think that's perfectly coherent.
I mean, I guess it's technically coherent, but it also sounds kind of insane. That way Dormammu lies.
Why would one even care about their future self if they're so unconcerned about that self's preferences?
This just boils down to “humans aren’t aligned,” and that fact is why this would never work, but I still think it’s worth bringing up. Why are you required to get a license to drive, but not to have children? I don’t mean this in a literal way, I’m just referring to how casual the decision to have children is seen by much of society. Bringing someone into existence is vastly higher stakes than driving a car.
I’m sure this isn’t implementable, but parents should at least be screened for personality disorders before they’re allowed to have children. And sure that’s a slippery slope, and sure many of the most powerful people just want workers to furnish their quality of life regardless of the worker’s QOL. But bringing a child into the world who you can’t properly care for can lead to a lifetime of avoidable suffering.
I was just reading about “genomic liberty,” and the idea that parents would choose to make their kids iq lower than possible, that some would even choose for their children to have disabilities like them is completely ridiculous. And it just made me think “those people shouldn’t have the liberty of being parents.” Bringing another life into existence is not casual like where you work/live. And the obligation should be to the children, not the parents.
There is also the related problem of intelligence being negatively correlated with fertility, which leads to a dysgenic trend. Even if preventing people below a certain level of intelligence to have children was realistically possible, it would make another problem more severe: the fertility of smarter people is far below replacement, leading to quickly shrinking populations. Though fertility is likely partially heritable, and would go up again after some generations, once the descendants of the (currently rare) high-fertility people start to dominate.
>be me, omnipotent creator
>decide to create
>meticulously craft laws of physics
>big bang
>pure chaos
>structure emerges
>galaxies form
>stars form
>planets form
>life
>one cell
>cell eats other cell, multicellular life
>fish
>animals emerge from the oceans
>numerous opportunities for life to disappear, but it continues
>mammals
>monkeys
>super smart monkeys
>make tools, control fire, tame other animals
>monkeys create science, philosophy, art
>the universe is beginning to understand itself
>AI
>Humans and AI together bring superintelligence online
>everyone holds their breath
>superintelligence turns everything into paper clips mfw infinite kek
From what I understand, JVN, Poincaré, and Terence Tao all had/have issues with perceptual intuition/mental visualization. JVN had “the physical intuition of a doorknob,” Poincaré was tested by Binet and had extremely poor perceptual abilities, and Tao (at least as a child) mentioned finding mental rotation tasks “hard.”
I also fit a (much less extreme) version of this pattern, which is why I’m interested in this in the first place. I am (relatively) good at visual pattern recognition and math, but I have aphantasia and have an average visual working memory. I felt insecure about this for a while, but seeing that much more intelligent people than me had a similar (but more extreme) cognitive profile made me feel better.
Does anybody have a satisfactory explanation for this profile beyond a simplistic “tradeoffs” explanation?
Edit: Some claims about JVN/Poincare may have been hallucinated, but they are based at least somewhat on reality. See my reply to Steven
(Not really answering your question, just chatting.)
What’s your source for “JVN had ‘the physical intuition of a doorknob’”? Nothing shows up on google. I’m not sure quite what that phrase is supposed to mean, so context would be helpful. I’m also not sure what “extremely poor perceptual abilities” means exactly.
You might have already seen this, but Poincaré writes about “analysts” and “geometers”:
It is impossible to study the works of the great mathematicians, or even those of the lesser, without noticing and distinguishing two opposite tendencies, or rather two entirely different kinds of minds. The one sort are above all preoccupied with logic; to read their works, one is tempted to believe they have advanced only step by step, after the manner of a Vauban who pushes on his trenches against the place besieged, leaving nothing to chance. The other sort are guided by intuition and at the first stroke make quick but sometimes precarious conquests, like bold cavalrymen of the advance guard.
The method is not imposed by the matter treated. Though one often says of the first that they are analysts and calls the others geometers, that does not prevent the one sort from remaining analysts even when they work at geometry, while the others are still geometers even when they occupy themselves with pure analysis. It is the very nature of their mind which makes them logicians or intuitionalists, and they can not lay it aside when they approach a new subject.
Not sure exactly how that relates, if at all. (What category did Poincaré put himself in? It’s probably in the essay somewhere, I didn’t read it that carefully. I think geometer, based on his work? But Tao is extremely analyst, I think, if we buy this categorization in the first place.)
I’m no JVN/Poincaré/Tao, but if anyone cares, I think I’m kinda aphantasia-adjacent, and I think that fact has something to do with why I’m naturally bad at drawing, and why, when I was a kid doing math olympiad problems, I was worse at Euclidean geometry problems than my peers who got similar overall scores.
Oh I was actually hoping you’d reply! I may have hallucinated the exact quote I mentioned but here is something from Ulam: “Ulam on physical intuition and visualization,” it’s on Steve Hsu’s blog. And I might have hallucinated the thing about Poincaré being tested by Binet, that might just be an urban legend I didn’t verify. You can find Poincaré’s struggles with coordination and dexterity in “Men of Mathematics,” but that’s a lot less extreme than the story I passed on. I am confident in Tao’s preference for analysis over visualization. If you have the time look up “Terence Tao” on Gwern’s website.
I’m not very familiar with the field of neuroscience, but it seems to me that we’re probably pretty far from being able to provide a satisfactory answer to these questions. Is that true from your understanding of where the field is at? What sorts of techniques/technology would we need to develop in order for us to start answering these questions?
If you have the time look up “Terence Tao” on Gwern’s website.
In case anyone else is going looking, here is the relevant account of Tao as a child and here is a screenshot of the most relevant part:
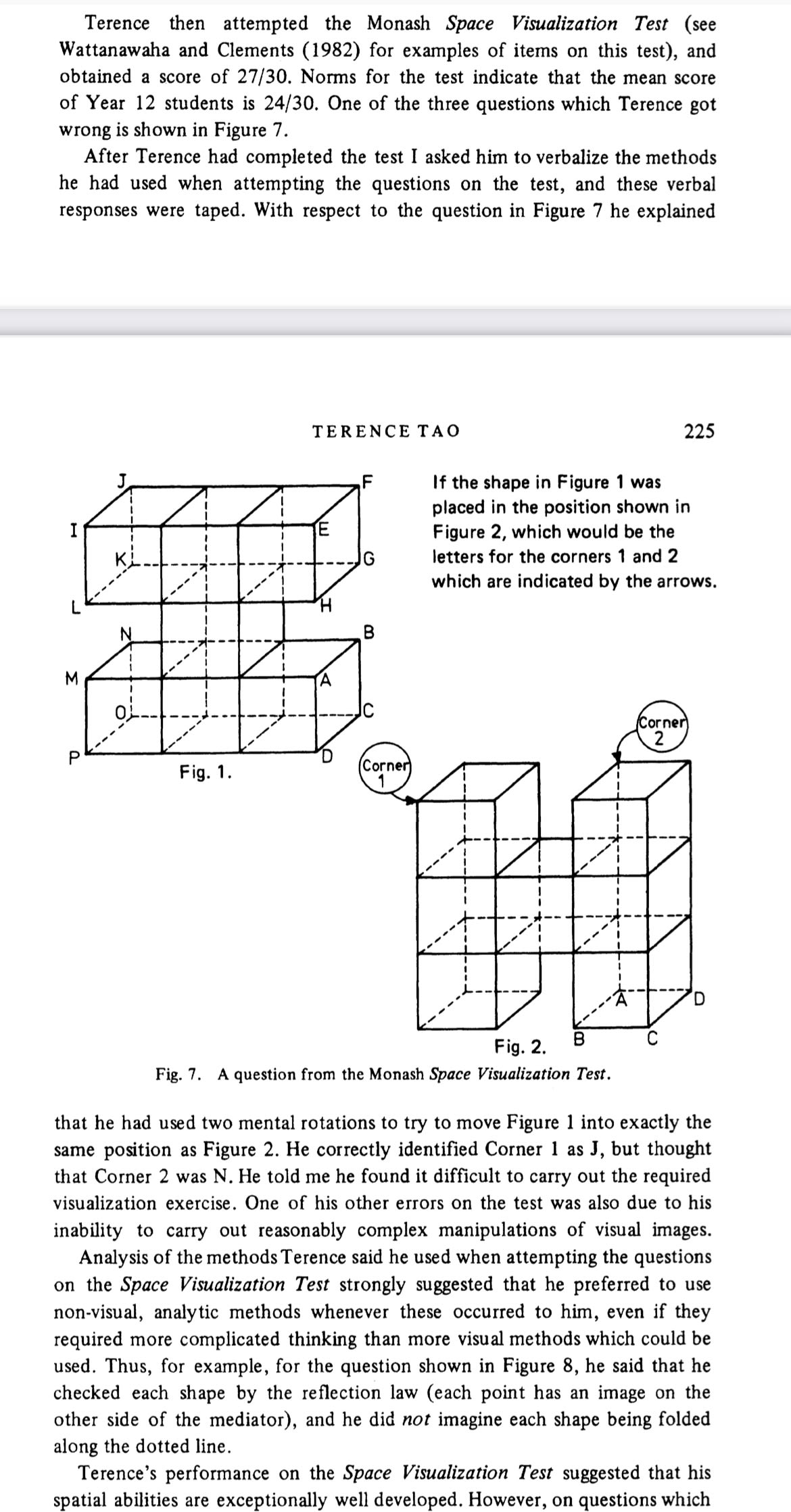
How far along are the development of autonomous underwater drones in America? I’ve read statements by American military officials about wanting to turn the Taiwan straight into a drone-infested death trap. And I read someone (not an expert) who said that China is racing against time to try and invade before autonomous underwater drones take off. Is that true? Are they on track?
Apologies in advance if this is a midwit take. Chess engines are “smarter” than humans at chess, but they aren’t automatically better at real-world strategizing as a result. They don’t take over the world. Why couldn’t the same be true for STEMlord LLM-based agents?
It doesn’t seem like any of the companies are anywhere near AI that can “learn” or generalize in real time like a human or animal. Maybe a superintelligent STEMlord could hack their way around learning, but that still doesn’t seem the same as or as dangerous as fooming, and it also seems much easier to monitor. Does it not seem plausible that the current paradigm drastically accelerates scientific research while remaining tools? The counter is that people will just use the tools to try and figure out learning. But we don’t know how hard learning is, and the tools could also enable people to make real progress on alignment before learning is cracked.
Welcome to Less Wrong. Sometimes I like to go around engaging with new people, so that’s what I’m doing.
On a sentence-by-sentence basis, your post is generally correct. It seems like you’re disagreeing with something you’ve read or heard. But I don’t know what you read, so I can’t understand what you’re arguing for or against. I could guess, but it would be better if you just said.
hi, thank you! i guess i was thinking about claims that "AGI is imminent and therefore we're doomed." it seems like if you define AGI as "really good at STEM" then it is obviously imminent. but if you define it as "capable of continuous learning like a human or animal," that's not true. we don't know how to build it and we can't even run a fruit-fly connectome on the most powerful computers we have for more than a couple of seconds without the instance breaking down: how would we expect to run something OOMs more complex and intelligent? "being good at STEM" seems like a much, much simpler and less computationally intensive task than continuous, dynamic learning. tourist is great at codeforces, but he obviously doesn't have the ability to take over the world (i am making the assumption that anyone with the capability to take over the world would do so). the second is a much, much fuzzier, more computationally complex task than the first.
i had just been in a deep depression for a while (it's embarassing, but this started with GPT-4) because i thought some AI in the near future was going to wake up, become god, and pwn humanity. but when i think about it from this perspective, that future seems much less likely. in fact, the future (at least in the near-term) looks very bright. and i can actually plan for it, which feels deeply relieving to me.
For me, depression has been independent of the probability of doom. I’ve definitely been depressed, but I’ve been pretty cheerful for the past few years, even as the apparent probability of near-term doom has been mounting steadily. I did stop working on AI, and tried to talk my friends out of it, which was about all I could do. I decided not to worry about things I can’t affect, which has clarified my mind immensely.
The near-term future does indeed look very bright.
Hey Carl, sorry to bother you what I'm about to say is pretty irrelevant to the discussion but I'm a highschool student looking to gather good research experience and I wanted to ask a few questions. Is there any place I can reach out to you other than here? I would greatly appreciate any and all help!
You shouldn’t worry about whether something “is AGI”; it’s an I’ll-defined concept. I agree that current models are lacking the ability to accomplish long-term tasks in the real world, and this keeps them safe. But I don’t think this is permanent, for two reasons.
Current large-language-model type AI is not capable of continuous learning, it is true. But AIs which are capable of it have been built. AlphaZero is perhaps the best example; it learns to play games to a superhuman level in a few hours. It’s a topic of current research to try to combine them.
Moreover, tool-type AIs tend to be developed to provide agency, because it’s more useful to direct an agent than it is a tool. This is a more fully fleshed out here: https://gwern.net/tool-ai
Much of my probability of non-doom is resting on people somehow not developing agents.
MuZero doesn’t seem categorically different from AlphaZero. It has to do a little bit more work at the beginning, but if you don’t get any reward for breaking the rules: you will learn not to break the rules. If MuZero is continuously learning then so is AlphaZero. Also, the games used were still computationally simple, OOMs more simple than an open-world game, let alone a true World-Model. AFAIK MuZero doesn’t work on open-ended, open-world games. And AlphaStar never got to superhuman performance at human speed either.
I am in violent agreement. Nowhere did I say that MuZero could learn a world model as complicated as those LLMs currently enjoy. But it could learn continuously, and execute pretty complex strategies. I don’t know how to combine that with the breadth of knowledge or cleverness of LLMs, but if we could, we’d be in trouble.
>be me, omnipotent creator
>decide to create
>meticulously craft laws of physics
>big bang
>pure chaos
>structure emerges
>galaxies form
>stars form
>planets form
>life
>one cell
>cell eats other cell, multicellular life
>fish
>animals emerge from the oceans
>numerous opportunities for life to disappear, but it continues
>mammals
>monkeys
>super smart monkeys
>make tools, control fire, tame other animals
>monkeys create science, philosophy, art
>the universe is beginning to understand itself
>AI
>Humans and AI together bring superintelligence online
>everyone holds their breath
>superintelligence turns everything into paper clips mfw infinite kek